

The Data Computing Layer in Reporting Architecture
In the previous article, we discussed the necessity of the existence of a computing layer in the reporting architecture. Reporting tools support the user-defined interface-based programming with its host language (i.e. the programming language used for developing a reporting tool) to achieve the functionality of a computing layer for implementing complex computational logics, but the strategy reveals some real-life problems. An explicit data computing layer that provides scripting functionality capable of interpretive execution to make the data preparation an independent stage is thus preferred.
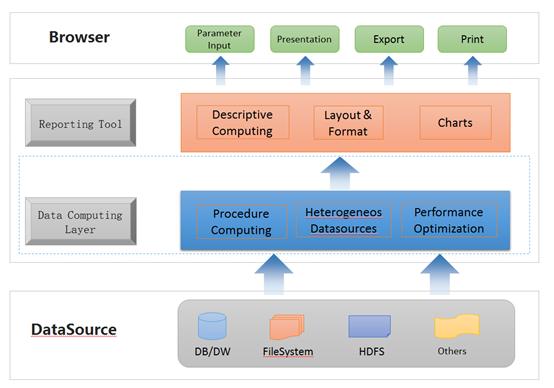
An independent data computing layer has four merits.
Facilitating coding
Generally a reporting tool’s host programming language is a high-level language, such as Java and C#, which has an all-round but low-level support for processing structured data sets. The computing process is very tedious. A simple sum needs to be implemented through loops of lines of code. Since the preparation of data source involves a lot of batch processing, it’s common to have hundreds of lines of code, which is tedious to write and difficult to debug, when a high-level language is used.
A script intended for data computing provides rich functionalities of processing structured data sets, which makes batch processing convenient. A shorter code piece means not only light workload and convenient debugging, but an easier understanding and control of the algorithm. With a convenient to use programming language, the data preparation algorithm for most report building can be completed within the expanse of a computer screen, which is clear and clean.
Loose coupling with the application
The report layout is controlled by report templates, which are regular files stored in the file system. With a user-defined data source, the data preparation algorithm will be compiled and packaged into the application. As two indispensable components, the template and the algorithm must be appropriately coordinated for a smooth processing of the data set. But storing them in different systems, plus the possibility of development by different programmers, makes it inconvenient to modify and maintain the report and requires special extra effort to keep them consistent. A computational script written within an independent computing layer is interpretive execution, so it can be stored in a file system along with the report templates, which are also interpretive execution, making it convenient to keep them consistent for report maintenance and achieving a loose coupling with the application.
Hot switching isn’t an issue anymore
For report building using a user-defined data source, the algorithm for data set processing is part of the application. Any modification of the report will lead to a recompilation and repackaging of the whole application, and the termination and restart of the application on most occasions. The reporting is inclined to change because of frequent addition and modification to a report, causing frequent restart of the application. Though a programming mechanism like Java supports hot loading, the complicated usage is a challenge to many programmers. Besides, a loaded application can’t be removed and will occupy memory space even when it becomes useless. So it’s not suitable to use the hot loading in handling report data sources.
But the hot loading won’t be an issue any more for a script written within an independent computing layer. Any modification to the report needs only the change of the template and the script. The interpretive execution of the script doesn’t need to modify the application, eliminating the chances of the termination and restart of the application. The modification of the report can be done while trying to access it.
Reducing human resource cost
The code of the preparation of the data sets for report building using Java or other high-level languages needs to reference environment information including database connection, base class library, etc. The development team needs to learn and observe a set of coding standards for building the application to enhance communications, which is a skill only professional programmers can master. For users, though many of their technical specialists can understand the data structure and computational logic of preparing report data sets, they have difficulty in grasping the development environment and thus can’t build reports in a flexible way.
With an independent computing layer, the environment information for report building can be preconfigured in the application. Except for data structure and computational logic, developers don’t need to take care of the consistency of the coding standards. Thus more technical specialists will be able to handle the task of report development, which suits the characteristic of frequent modifications to a report.
SPL Official Website 👉 http://www.scudata.com
SPL Feedback and Help 👉 https://www.reddit.com/r/esProc
SPL Learning Material 👉 http://c.scudata.com
SPL Source Code and Package 👉 https://github.com/SPLWare/esProc
Discord 👉 https://discord.gg/ydhVnFH9
Youtube 👉 https://www.youtube.com/@esProc_SPL

