

SPL Examples of Implementing & Optimizing SQL IN & EXISTS
1. TPC-H data structure
IN & EXISTS are common yet hard-to-handle to SQL. We are often confronted with them when moving data into external calculation engines that can perform SQL queries or stored procedures efficiently. Based on the TPC-H-defined model, the article explains how to achieve and optimize the two operators with esProc.
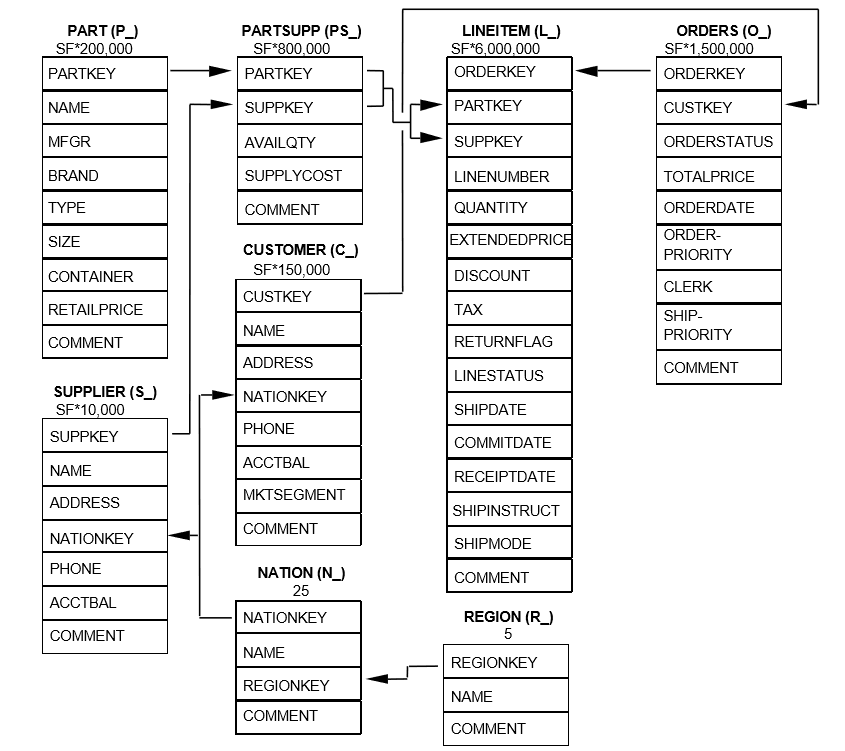
Established by the Transaction Processing Performance Council (TPC), TPC-H is a decision-support benchmark. It simulates real-world business environment to examine the performance metric and the capability of an OLAP system to process queries. The TPC-H model includes 8 tables. Below is the structure of each table and the relationships between them:
2. IN- Constant set
2.1 SQL example 1
select
P_SIZE, P_TYPE, P_BRAND, count(1) as P_COUNT
from
PART
where
P_SIZE in (2, 3, 8, 15, 17, 25, 27, 28, 30, 38, 41, 44, 45)
and P_TYPE in ('SMALL BRUSHED NICKEL', 'SMALL POLISHED STEEL')
and P_BRAND not in ('Brand#12', 'Brand#13')
group by
P_SIZE, P_TYPE, P_BRAND
2.2 Optimization method
If there are less than 3 elements in a constant set, the IN condition can be phrased as (f == v1 || f == v2). Correspondingly, the NOT IN is (f != v1 && .f != v2). Most of the time, we can define a constant set as a sequence in the outer query and use A.contain(f) function to check if a field value falls within the sequence. If there are more than 13 elements in a constant set, we can first sort the set and then use A.contain@b(f) function to perform an order-based search. In this case, NOT IN is ! A.contain(f). The definition of sequence must be outside the loop; otherwise an operation over it will be performed repeatedly.
If there are many elements in a constant set, use the join filter to perform the search. Detailed code is shown below.
2.3 esProc script
| A | B | |
|---|---|---|
| 1 | =[28, 30, 38,2, 3, 8, 15, 17, 25, 27,50 , 41, 44, 45].sort() | / Sort the constant set to perform an order-based search. This is faster than traversal when there are more than 13 elements in the sequence. |
| 2 | =file(PART).cursor@b(P_SIZE, P_TYPE, P_BRAND) | / Define a cursor over PART table’s bin file; parameters are to-be-selected columns |
| 3 | =A2.select(A1.contain@b(P_SIZE) && (P_TYPE == "SMALL BRUSHED NICKEL" || P_TYPE == "SMALL POLISHED STEEL") && (P_BRAND != "Brand#12" && P_BRAND != "Brand#13")) | / Attach a filtering operation to the cursor; the constant sequence must be defined outside the filtering function, otherwise the it will be repeatedly filtered |
| 4 | =A3.groups(P_SIZE, P_TYPE, P_BRAND; count(1): P_COUNT) | / Group the result of computing the cursor data to get the final result |
If there are too many elements in A1’s sequence, we can use the hash join to perform the filtering. Now rewrite A3’s code in this way:
| 3 | =A2.select((P_TYPE == "SMALL BRUSHED NICKEL" || P_TYPE == "SMALL POLISHED STEEL") && (P_BRAND != "Brand#12" && P_BRAND != "Brand#13")) .join@i(P_SIZE, A1:~) | // Attach a filtering operation and then a join filter to the cursor |
3. IN - Subquery
3.1 The selected field is primary key
3.1.1 SQL example 2
select
PS_SUPPKEY, count(1) as S_COUNT
from
PARTSUPP
where
PS_PARTKEY in (
select
P_PARTKEY
from
PART
where
P_NAME like ' bisque%%'
)
group by
PS_SUPPKEY
3.1.2 Optimization method
Perform filtering in the subquery and import the result set into the memory. Then perform a hash join between the outer table and the memory table (result of the subquery) and perform filtering. esProc provides switch@i() function and join@i() function to perform a hash join and filtering. The switch() function performs a foreign-key-based join to replace foreign key values with the referenced field values. This way, we can reference a field of the referenced table directly through the foreign key field. The join() function won’t change foreign key values and can be used for filtering only.
3.1.3 esProc script
| A | B | |
|---|---|---|
| 1 | =file(PART).cursor@b(P_PARTKEY, P_NAME) | / Define a cursor over PART table’s bin file; parameters are to-be-selected columns |
| 2 | =A1.select(like(P_NAME, "bisque*")).fetch() | / Attach a filtering operation to the cursor and fetch data |
| 3 | =file(PARTSUPP).cursor@b(PS_SUPPKEY, PS_PARTKEY) | / Define a cursor over PARTSUPP table’s bin file; parameters are to-be-selected columns |
| 4 | =A3.join@i(PS_PARTKEY, A2:P_PARTKEY) | / Perform a join filter over cursor PARTSUPP; @i option means an inner join |
| 5 | =A4.groups(PS_SUPPKEY; count(1):S_COUNT) | / Group the result of computing the cursor data to get the final result |
3.2 The selected field isn’t primary key
3.2.1 SQL example 3
select
O_ORDERPRIORITY, count(*) as O_COUNT
from
ORDERS
where
O_ORDERDATE >= date '1995-10-01'
and O_ORDERDATE < date '1995-10-01' + interval '3' month
and O_ORDERKEY in (
select
L_ORDERKEY
from
LINEITEM
where
L_COMMITDATE< L_RECEIPTDATE
)
group by
O_ORDERPRIORITY
3.2.2 Optimization method
In the subquery, perform filtering and then distinct by the associated field and import the result set to the memory. Now the situation is similar to the primary-key-based filtering. We can use the switch@i() function and join@i() function to perform a hash join and filtering.
3.2.3 esProc script
| A | B | |
|---|---|---|
| 1 | 1995-10-01 | =after@m(A1,3) |
| 2 | =file(LINEITEM).cursor@b(L_ORDERKEY,L_COMMITDATE,L_RECEIPTDATE) | / Define a cursor over LINEITEM table’s bin file; parameters are to-be-selected columns |
| 3 | =A2.select(L_COMMITDATE < L_RECEIPTDATE) | / Attach a filtering operation to the cursor |
| 4 | =A3.groups(L_ORDERKEY) | / groups() function removes duplicates from L_ORDERKEY |
| 5 | =file(ORDERS).cursor@b(O_ORDERKEY,O_ORDERDATE,O_ORDERPRIORITY) | / Define a cursor over ORDER table’s bin file; parameters are to-be-selected columns |
| 6 | =A5.select(O_ORDERDATE>=A1 && O_ORDERDATE < B1) | / Attach a filtering operation to the cursor |
| 7 | =A6.join@i(O_ORDERKEY, A4:L_ORDERKEY) | / Perform a join filter over cursor ORDERS; @i option means an inner join |
| 8 | =A7.groups(O_ORDERPRIORITY; count(1):O_COUNT) | / Group the result of computing the cursor data to get the final result |
3.3 A result set that exceeds the available memory space
3.3.1 SQL example 4
select
O_ORDERPRIORITY, count(*) as O_COUNT
from
ORDERS
where
O_ORDERDATE >= date '1995-10-01'
and O_ORDERDATE < date '1995-10-01' + interval '3' month
and O_ORDERKEY in (
select
L_ORDERKEY
from
LINEITEM
where
L_COMMITDATE< L_RECEIPTDATE
)
group by
O_ORDERPRIORITY
3.3.2 Optimization method
The IN subquery amounts to performing distinct over the subquery result and then inner-joining with the outer table. Two fast ways of performing an inner join is the hash join and the order-based merge join. The key to optimizing IN subquery is the efficient translation to a join. The following shows how to translate the IN subquery to a join in different data environments:
A. An outer table that can be loaded to the memory
Load the outer table, remove duplicates according to the associated field if it isn’t the logical primary key, perform a hash join and filtering over the subquery by the deduplicated associated field values, and, finally, perform a hash join and filtering over the outer table based on the associated field values of the subquery result.
B. Both outer table and inner table are ordered by the associated fields
We can use joinx() function to perform a merge join over ordered cursors if both outer table and inner table are ordered by the associated fields (Both ORDERS and LINEITEM are ordered by ORDERKEY in this instance). Make sure to remove duplicates over the inner table if the associated filed isn’t the logical primary key.
C. The inner table is a big dimension table and is ordered by the primary key
For a big dimension table, esProc offers A.joinx() function to perform a join. Other operations are similar to cases where an inner table can be all loaded to the memory.
3.3.3 esProc script 1
| A | B | |
|---|---|---|
| 1 | 1995-10-01 | =after@m(A1,3) |
| 2 | =file(ORDERS).cursor@b(O_ORDERKEY,O_ORDERDATE,O_ORDERPRIORITY) | / Define a cursor over ORDER table’s bin file; parameters are to-be-selected columns |
| 3 | =A2.select(O_ORDERDATE>=A1 && O_ORDERDATE < B1).fetch() | / Attach a filtering operation to the cursor and fetch data |
| 4 | =file(LINEITEM).cursor@b(L_ORDERKEY,L_COMMITDATE,L_RECEIPTDATE) | / Define a cursor over LINEITEM table’s bin file; parameters are to-be-selected columns |
| 5 | =A4.select(L_COMMITDATE < L_RECEIPTDATE).join@i(L_ORDERKEY,A3:O_ORDERKEY) | / Attach a filtering operation and then a join filter to the cursor |
| 6 | =A5.groups(L_ORDERKEY) | / Perform distinct over L_ORDERKEY |
| 7 | =A3.join@i(O_ORDERKEY, A6:L_ORDERKEY) | / Perform a join filter over the record sequence |
| 8 | =A7.groups(O_ORDERPRIORITY;count(1):O_COUNT) | / Group and summarize the record sequence to get the final result |
3.3.4 esProc script 2
| A | B | |
|---|---|---|
| 1 | 1995-10-01 | =after@m(A1,3) |
| 2 | =file(ORDERS).cursor@b(O_ORDERKEY,O_ORDERDATE,O_ORDERPRIORITY) | / Define a cursor over ORDER table’s bin file; parameters are to-be-selected columns |
| 3 | =A2.select(O_ORDERDATE>=A1 && O_ORDERDATE < B1) | / Attach a filtering operation to the cursor |
| 4 | =file(LINEITEM).cursor@b(L_ORDERKEY,L_COMMITDATE,L_RECEIPTDATE) | / Define a cursor over LINEITEM table’s bin file; parameters are to-be-selected columns |
| 5 | =A4.select(L_COMMITDATE < L_RECEIPTDATE) | / Attach a filtering operation to the cursor |
| 6 | =A5.group@1(L_ORDERKEY) | / Perform distinct over L_ORDERKEY |
| 7 | =joinx(A3:ORDER, O_ORDERKEY; A6, L_ORDERKEY) | / Perform inner join over ordered cursors |
| 8 | =A7.groups(ORDER.O_ORDERPRIORITY:O_ORDERPRIORITY;count(1):O_COUNT) | / Group the result of computing the cursor data to get the final result |
4. EXISTS condition
The optimization method for EXISTS condition is similar to that for the IN subquery. In fact EXISTS subqueries can be expressed by IN subqueries, or vice versa.
4.1 The associated field is primary key
4.1.1 SQL example 5
select
PS_SUPPKEY, count(1) as S_COUNT
from
PARTSUPP
where
exists (
select
*
from
PART
where
P_PARTKEY = PS_PARTKEY
and P_NAME like ' bisque%%'
)
group by
PS_SUPPKEY
4.1.2 Optimization method
In the subquery, perform filtering, import the result set to the memory, and perform a hash join and filtering over the outer table and the memory table (the subquery result set) using switch@i() function and join@i() function. Now the situation is similar to the primary-key-based filtering. The switch() function performs a foreign-key-based join to replace foreign key values with the referenced field values. This way, we can reference a field of the referenced table directly through the foreign key field. The join() function won’t change foreign key values and can be used for filtering only.
4.1.3 esProc script
| A | B | |
|---|---|---|
| 1 | =file(PART).cursor@b(P_PARTKEY, P_NAME) | / Define a cursor over PART table’s bin file; parameters are to-be-selected columns |
| 2 | =A1.select(like(P_NAME, "bisque*")).fetch() | / Attach a filtering operation to the cursor and fetch data |
| 3 | =file(PARTSUPP).cursor@b(PS_SUPPKEY, PS_PARTKEY) | / Define a cursor over PARTSUPP table’s bin file; parameters are to-be-selected columns |
| 4 | =A3.join@i(PS_PARTKEY, A2:P_PARTKEY) | / Perform a join filter over cursor PARTSUPP; @i option means an inner join |
| 5 | =A4.groups(PS_SUPPKEY; count(1):S_COUNT) | / Group the result of computing the cursor data to get the final result |
4.2 The associated field isn’t primary key
4.2.1 SQL example 6
select
O_ORDERPRIORITY, count(*) as O_COUNT
from
ORDERS
where
O_ORDERDATE >= date '1995-10-01'
and O_ORDERDATE < date '1995-10-01' + interval '3' month
and exists (
select
*
from
LINEITEM
where
L_ORDERKEY = O_ORDERKEY
and L_COMMITDATE < L_RECEIPTDATE
)
group by
O_ORDERPRIORITY
4.2.2 Optimization method
In the subquery, perform filtering and then distinct by the associated field and import the result set to the memory. Now the case is similar to the primary-key-based filtering. We can use the switch@i() function and join@i() function to perform a hash join and filtering.
4.2.3 esProc script
| A | B | |
|---|---|---|
| 1 | 1995-10-01 | =after@m(A1,3) |
| 2 | =file(LINEITEM).cursor@b(L_ORDERKEY,L_COMMITDATE,L_RECEIPTDATE) | / Define a cursor over LINEITEM table’s bin file; parameters are to-be-selected columns |
| 3 | =A2.select(L_COMMITDATE < L_RECEIPTDATE) | / Attach a filtering operation to the cursor |
| 4 | =A3.groups(L_ORDERKEY) | / Perform distinct over L_ORDERKEY |
| 5 | =file(ORDERS).cursor@b(O_ORDERKEY,O_ORDERDATE,O_ORDERPRIORITY) | / Define a cursor over ORDER table’s bin file; parameters are to-be-selected columns |
| 6 | =A5.select(O_ORDERDATE>=A1 && O_ORDERDATE < B1) | / Attach a filtering operation to the cursor |
| 7 | =A6.join@i(O_ORDERKEY, A4:L_ORDERKEY) | / Perform a join filter over cursor ORDERS; @i option means an inner join |
| 8 | =A7.groups(O_ORDERPRIORITY; count(1):O_COUNT) | / Group the result of computing the cursor data to get the final result |
4.3 A result set that exceeds the available memory space
4.3.1 SQL example 7
select
O_ORDERPRIORITY, count(*) as O_COUNT
from
ORDERS
where
O_ORDERDATE >= date '1995-10-01'
and O_ORDERDATE < date '1995-10-01' + interval '3' month
and exists (
select
*
from
LINEITEM
where
L_ORDERKEY = O_ORDERKEY
and L_COMMITDATE < L_RECEIPTDATE
)
group by
O_ORDERPRIORITY
4.3.2 Optimization method
The EXISTS condition is equivalent to performing distinct over the inner table’s associated field and then inner-joining with the outer table. The efficient ways of performing an inner join is the hash join and the order-based merge join. Then the key to optimizing EXISTS condition becomes an efficient translation to a join. The following explains how to translate EXISTS to a join in different data environments:
A. An outer table that can be loaded to the memory
Load the outer table, remove duplicates over the associated field if it isn’t the logical primary key, perform a hash join and filtering over the subquery by the deduplicated associated field values, and, finally, perform a hash join and filtering over the outer table based on the associated field values of the subquery result.
B. Both outer table and inner table are ordered by the associated fields
We can use joinx()function to perform a merge join over ordered cursors if both outer table and inner table are ordered by the associated fields (Both ORDERS and LINEITEM are ordered by ORDERKEY in this instance). Make sure to remove duplicates over the inner table if the associated filed isn’t the logical primary key.
C. The inner table is a big dimension table and is ordered by the primary key
For a big dimension table, esProc offers A.joinx() function to perform a join. Other operations are similar to cases where an inner table can be all loaded to the memory.
4.3.3 esProc script 1
| A | B | |
|---|---|---|
| 1 | 1995-10-01 | =after@m(A1,3) |
| 2 | =file(ORDERS).cursor@b(O_ORDERKEY,O_ORDERDATE,O_ORDERPRIORITY) | / Define a cursor over ORDER table’s bin file; parameters are to-be-selected columns |
| 3 | =A2.select(O_ORDERDATE>=A1 && O_ORDERDATE < B1).fetch() | / Attach a filtering operation to the cursor and fetch data |
| 4 | =file(LINEITEM).cursor@b(L_ORDERKEY,L_COMMITDATE,L_RECEIPTDATE) | / Define a cursor over LINEITEM table’s bin file; parameters are to-be-selected columns |
| 5 | =A4.select(L_COMMITDATE < L_RECEIPTDATE).join@i(L_ORDERKEY,A3:O_ORDERKEY) | / Attach a filtering operation and then a join filter to the cursor |
| 6 | =A5.groups(L_ORDERKEY) | / Perform distinct over L_ORDERKEY |
| 7 | =A3.join@i(O_ORDERKEY, A6:L_ORDERKEY) | / Perform a join filter over the record sequence |
| 8 | =A7.groups(O_ORDERPRIORITY;count(1):O_COUNT) | / Group and summarize the record sequence to get the final result |
4.3.4 esProc script 2
| A | B | |
|---|---|---|
| 1 | 1995-10-01 | =after@m(A1,3) |
| 2 | =file(ORDERS).cursor@b(O_ORDERKEY,O_ORDERDATE,O_ORDERPRIORITY) | / Define a cursor over ORDER table’s bin file; parameters are to-be-selected columns |
| 3 | =A2.select(O_ORDERDATE>=A1 && O_ORDERDATE < B1) | / Attach a filtering operation to the cursor |
| 4 | =file(LINEITEM).cursor@b(L_ORDERKEY,L_COMMITDATE,L_RECEIPTDATE) | / Define a cursor over LINEITEM table’s bin file; parameters are to-be-selected columns |
| 5 | =A4.select(L_COMMITDATE < L_RECEIPTDATE) | / Attach a filtering operation to the cursor |
| 6 | =A5.group@1(L_ORDERKEY) | / Perform distinct over L_ORDERKEY |
| 7 | =joinx(A3:ORDER, O_ORDERKEY; A6, L_ORDERKEY) | / Perform inner join over ordered cursors |
| 8 | =A7.groups(ORDER.O_ORDERPRIORITY:O_ORDERPRIORITY;count(1):O_COUNT) | / Group the result of computing the cursor data to get the final result |
5. NOT EXISTS condition
5.1 Self-join
5.1.1 SQL example 7
select
L_SUPPKEY, count(*) as numwait
from
LINEITEM L1,
where
L1.L_RECEIPTDATE > L1.L_COMMITDATE
and exists (
select
*
from
LINEITEM L2
where
L2.L_ORDERKEY = L1.L_ORDERKEY
and L2.L_SUPPKEY <> L1.L_SUPPKEY
)
and not exists (
select
*
from
LINEITEM L3
where
L3.L_ORDERKEY = L1.L_ORDERKEY
and L3.L_SUPPKEY <> L1.L_SUPPKEY
and L3.L_RECEIPTDATE > L3.L_COMMITDATE
)
group by
L_SUPPKEY
5.1.2 Optimization method
First let’s examine the LINEITEM table. It has a composite primary key L_ORDERKEY and L_LINENUMBER, which means one order covers multiple records. These records have same L_ORDERKEY and its values are continuously arranged. In the SQL query, the goal is to find orders where only one of its multiple suppliers doesn’t deliver the goods on time. The data is arranged in order by orders. So we can group it by orders, and traverse each group to see if there are undelivered orders, multiple supplies and only one supplier delays the delivery.
5.1.3 esProc script
| A | B | |
|---|---|---|
| 1 | =file(LINEITEM).cursor@b(L_ORDERKEY,L_SUPPKEY,L_RECEIPTDATE,L_COMMITDATE) | / Define a cursor over LINEITEM table’s bin file; parameters are to-be-selected columns |
| 2 | =A1.group(L_ORDERKEY) | / Attach a grouping operation to an ordered cursor; the result is a record sequence cursor |
| 3 | =A2.conj((t=~.select(L_RECEIPTDATE > L_COMMITDATE), if(t.len() > 0 && t.select@1(t(1).L_SUPPKEY!=L_SUPPKEY)== null && ~.select@1(t(1).L_SUPPKEY!=L_SUPPKEY)!= null,t,null))) | / Select the delayed orders from each group and assign them to the temporary variable t; return t if the length of t is greater than 0 and contains only one supplier and the corresponding group includes multiple supplies; return null otherwise; conj amounts to the inverse operation of group. |
| 4 | =A3.groups@u(L_SUPPKEY;count(1):numwait) | / Group the result of computing the cursor data to get the final result |
6. Summary
An IN subquery not involving null values can be expressed in EXISTS. A query phrased with both IN and EXISTS corresponds to same esProc SPL query. As long as we know how to translate and optimize EXISTS in SPL, we’ll know how to handle IN optimization.
An EXIST condition boils down to performing a join. The hash join and the ordered-based merge join are two efficient ways of joining tables. To translate a SQL query in the style of select *** from A where exists (select *** from B where ***) into SPL, we need to know the following things:
A. If the associated fields are (logical) primary keys;
B. If the resultant joined table can be all loaded into the memory;
C. If neither of the two to-be-joined tables can be loaded into the memory, check if they are ordered respectively by the associated fields.
If one of the tables can be loaded into the memory, then we can perform a hash join. There are two esProc functions – cs.switch() and cs.join() – for doing it. Both can work with @i option and @d option respectively to realize EXISTS and NOT EXISTS. The table holding the parameter field should have distinct data according to the associated field. If the associated field isn’t the primary key, it needs to be first deduplicated through A.groups() function. If neither of the two tables can be loaded into the memory, check if they are ordered by the associated fields. If they are not, use cs.sortx() function to sort the tables; if they are, use joinx() function to join them.
For the NOT EXISTS condition, we need to examine the computing logic to see if it can be translated into grouping operation. If it can’t, the only choice is to perform the nested loop join with xjoin() function.
SPL Official Website 👉 http://www.scudata.com
SPL Feedback and Help 👉 https://www.reddit.com/r/esProc
SPL Learning Material 👉 http://c.scudata.com
SPL Source Code and Package 👉 https://github.com/SPLWare/esProc
Discord 👉 https://discord.gg/ydhVnFH9
Youtube 👉 https://www.youtube.com/@esProc_SPL

