

Implement grouping easily in Java with embeded SPL
Introduction to problems
It’s tedious to implement grouping and aggregation like groupBy in SQL in Java codes. Usually we first need to indicate the data structure (Java entity class), then iterate through the Java set, and finally add it to a subset according to grouping conditions. It’s simpler in Java 8 with Lambda(stream),but aggregation is usually needed after grouping, and we still need to write the aggregation functions like sum (), count (*), topN ()seperately. These are still the most common grouping and aggregation operations, in case of alignment grouping, enumeration grouping, multiple grouping and other unconventional grouping plus other aggregation functions (FIRST, LAST…), the code becomes very lengthy and not universal. If only there could be a middleware specially designed for this kind of calculation, using a similar SQL script to describe the algorithm, calling the script directly in Java and returning the result set, that will be perfect. EsProc and SPL script are just the product.Now we’ll illustrate how to use it by some examples.
SPL Implementation
Conventional grouping
Everyone’s overtime record is kept in the duty.xlsx file:
| workday | name |
|---|---|
| 2016-02-05 | Ashley |
| 2016-02-08 | Ashley |
| 2016-02-09 | Ashley |
| 2016-02-10 | Johnson |
| 2016-02-11 | Johnson |
| 2016-02-12 | Johnson |
| 2016-02-15 | Ashley |
| 2016-02-16 | Ashley |
| 2016-02-17 | Ashley |
Summarize the number of days on duty for each person:
| A | |
|---|---|
| 1 | =file("/Users/test/duty.xlsx").importxls@tx() |
| 2 | =A1.groups(name;count(name):count) |

Save the script file CountName.dfx(will be used when embeded in Java).
TopN of each group
Take the overtime records of each month, each person and the first three days.
| A | |
|---|---|
| 1 | =file("/Users/test/duty.xlsx").importxls@tx() |
| 2 | =A1.group(month(workday):mon,name;~.top(3):top3) |

Save the script file RecMonTop3.dfx(will be used when embeded in Java).
Java Incocation
SPL is very convenient to be embedded in Java applications. It can be loaded by calling stored procedure method through JDBC. We’ll illustrate the invocation by the example CountName.dfx.
...
Connection con = null;
Class.forName("com.esproc.jdbc.InternalDriver");
con= DriverManager.getConnection("jdbc:esproc:local://");
//Call stored procedure,CountName is the dfx file name
st =(com. esproc.jdbc.InternalCStatement)con.prepareCall("call CountName()");
//Execute stored procedure
st.execute();
//Get the result set
ResultSet rs = st.getResultSet();
...
It’s the same with RecMonTop3.dfx, and we only need to call RecMonTop3.dfx instead. We can also return two result sets at the same time. Only partial Java codes are used here to explain roughly how to embed SPL. For detailed steps, please refer to How to Call an SPL Script in Java. SPL also supports ODBC drivers and can be integrated into ODBC-enabled languages. The embedding process is similar.
Some examples
In fact, there are many kinds of data grouping, such as alignment grouping, enumeration grouping and multiple grouping. Here we give some examples.
SPL alignment grouping
Example 1:List in order the number of countries using Chinese, English and French as official languages.
MySQL8:
with t(name,ord) as (select 'Chinese',1
union all select 'English',2
union all select 'French',3)
select t.name, count(countrycode) cnt
from t left join world.countrylanguage s on t.name=s.language
where s.isofficial='T'
group by name,ord
order by ord;
Note: Character set of the table and database should be consistent.
(1) show variables like ‘character_set_connection’. View the current session character set
(2) show create table world.countrylanguage. View the character set of the table
(3) set character_set_connection=[Character set]Update the current session character set
esProc SPL:
| A | |
|---|---|
| 1 | =connect("mysql") |
| 2 | =A1.query@x("select * from world.countrylanguage where isofficial='T'") |
| 3 | Chinese,English,French] |
| 4 | =A2.align@a(A3,Language) |
| 5 | =A4.new(A3(#):name, ~.len():cnt) |
A1: Connect the database
A2: Query the records of all official languages
A3: the specified languages
A4: Align all records to the relative position in A3 by Language
A5: Create a table with the fields: language, the number of countries using the language as official languages
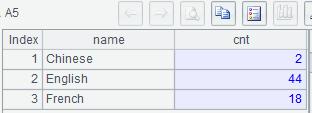
Example 2:List in order the number of countries using Chinese, English, French and other languages as official languages.
MySQL8:
with t(name,ord) as (select 'Chinese',1 union all select 'English',2
union all select 'French',3 union all select 'Other', 4),
s(name, cnt) as (
select language, count(countrycode) cnt
from world.countrylanguage s
where s.isofficial='T' and language in ('Chinese','English','French')
group by language
union all
select 'Other', count(distinct countrycode) cnt
from world.countrylanguage s
where isofficial='T' and language not in ('Chinese','English','French')
)
select t.name, s.cnt
from t left join s using (name)
order by t.ord;
esProc SPL:
| A | |
|---|---|
| 1 | =connect("mysql") |
| 2 | =A1.query@x("select * from world.countrylanguage where isofficial='T'") |
| 3 | [Chinese,English,French,Other] |
| 4 | =A2.align@an(A3.to(3),Language) |
| 5 | =A4.new(A3(#):name, if(#<=3,~.len(), ~.icount(CountryCode)):cnt) |
A4: Align all records to the relative position in A3.to(3) by Language, and add a group to store non-aligned records.
A5: Calculate the number of countries in A4
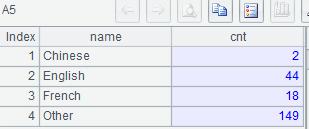
SPL Enumeration grouping
Example 1:List in order the number of different types of cities.
MySQL8:
with t as (select * from world.city where CountryCode='CHN'),
segment(class,start,end) as (select 'tiny', 0, 200000
union all select 'small',?? 200000, 1000000
union all select 'medium', 1000000, 2000000
union all select 'big', 2000000, 100000000
)
select class, count(1) cnt
from segment s join t on t.population>=s.start and t.population<s.end
group by class, start
order by start;
esProc SPL:
| A | |
|---|---|
| 1 | =connect("mysql") |
| 2 | =A1.query@x("select * from world.city where CountryCode='CHN'") |
| 3 | =${string([20,100,200,10000].(~*10000).("?<"/~))} |
| 4 | [tiny,small,medium,big] |
| 5 | =A2.enum(A3,Population) |
| 6 | =A5.new(A4(#):class, ~.len():cnt) |
A3: ${…}Macro replacement.The result of the expression in brackets is used as the new expression to calculate. The result is the sequence [“?<200000”,“?<1000000”,“?<2000000”,“?<100000000”].
A5: For each record in A2, find the first condition in A3 and add it to the corresponding group.
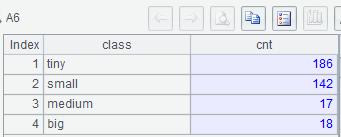
Example 2:List the number of large cities in East China, the number of large cities in other areas, and the number of Non-large cities.
MySQL8:
with t as (select * from world.city where CountryCode='CHN')
select 'East&Big' class, count(*) cnt
from t
where population>=2000000
and district in ('Shanghai','Jiangshu', 'Shandong','Zhejiang','Anhui','Jiangxi')
union all
select 'Other&Big', count(*)
from t
where population>=2000000
and district not in ('Shanghai','Jiangshu','Shandong','Zhejiang','Anhui','Jiangxi')
union all
select 'Not Big', count(*)
from t
where population<2000000;
esProc SPL:
| A | |
|---|---|
| 1 | =connect("mysql") |
| 2 | =A1.query@x("select * from world.city where CountryCode='CHN'") |
| 3 | [Shanghai,Jiangshu, Shandong,Zhejiang,Anhui,Jiangxi] |
| 4 | [?(1)>=2000000 && A3.contain(?(2)), ?(1)>=2000000 && !A3.contain(?(2))] |
| 5 | [East&Big,Other&Big, Not Big] |
| 6 | =A2.enum@n(A4, [Population,District]) |
| 7 | =A6.new(A5(#):class, A6(#).len():cnt) |
A5: enum@n stores records that do not meet all the conditions in A4 in the last additional group.
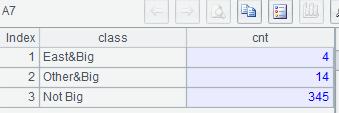
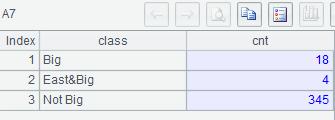
Example 3:List the number of large cities in all regions, the number of large cities in East China and the number of Non-large cities.
MySQL8:
with t as (select * from world.city where CountryCode='CHN')
select 'Big' class, count(*) cnt
from t
where population>=2000000
union all
select 'East&Big' class, count(*) cnt
from t
where population>=2000000
and district in ('Shanghai','Jiangshu','Shandong','Zhejiang','Anhui','Jiangxi')
union all
select 'Not Big' class, count(*) cnt
from t
where population<2000000;
esProc SPL:
| A | |
|---|---|
| 1 | =connect("mysql") |
| 2 | =A1.query@x("select * from world.city where CountryCode='CHN'") |
| 3 | [Shanghai,Jiangshu, Shandong,Zhejiang,Anhui,Jiangxi] |
| 4 | [?(1)>=2000000, ?(1)>=2000000 && A3.contain(?(2))] |
| 5 | [Big, East&Big, Not Big] |
| 6 | =A2.enum@rn(A4, [Population,District]) |
| 7 | =A6.new(A5(#):class, A6(#).len():cnt) |
A6: If the records in A2 satisfy more than one condition in A4, enum@r adds them to the corresponding group respectively.
Advantage summary
-
Use SQL if database is available, otherwise use SPL
It is cumbersome to implement grouping and aggregation by Java programing, the code is long and not reusable. Often the data is not stored in database. With SPL, it’s as convenient as using SQL in Java. -
The free esProc Community Edition has been released. To use it permanently, users can deploy it on the server and integrate it with Java.
-
Technical documentation and community support
Officially provided esProc technology documentation has many ready-made examples, and solutions to conventional problems can be found in the documentation. If you’ve got the introductory version, you can not only use the regular functions of SPL, but also go to the Raqsoft Community to consult if you encounter any problems. Raqsoft provides free technical support to the users of the introductory version through the community.
SPL Official Website 👉 http://www.scudata.com
SPL Feedback and Help 👉 https://www.reddit.com/r/esProc
SPL Learning Material 👉 http://c.scudata.com
SPL Source Code and Package 👉 https://github.com/SPLWare/esProc
Discord 👉 https://discord.gg/ydhVnFH9
Youtube 👉 https://www.youtube.com/@esProc_SPL

