

Deduplicate Row-based Excel
There are multiple columns of data in a file, among which the first row is the column name, and the data of records start from the second row. The computational task is to compare the key columns in the file, delete the duplicate rows in the key column or keep only the duplicate rows.
Some of the data in the sales order table of 2018 order_2018.xlsx are as follows:
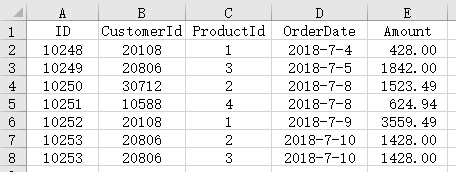
1. Remove duplicates
Example 1: Find all the different customer IDs who purchased products in 2018 and store them in 2018c.xlsx.
The esProc SPL script is as follows:
A |
|
1 |
=T("e:/orders/order_2018.xlsx") |
2 |
=A1.id(CustomerId) |
3 |
=T("e:/orders/2018c.xlsx",A2) |
A1 Read the data in order_2018.xlsx
A2 Take out all distinct CustomerIds in A1
A3 Write the data in A2 into 2018c.xlsx
Example 2: Find all the different products each customer purchased in 2018 and store CustomerId and ProductId in 2018c_p.xlsx.
The esProc SPL script is as follows:
A |
|
1 |
=T("e:/orders/order_2018.xlsx";CustomerId,ProductId) |
2 |
=A1.group@1(CustomerId,ProductId) |
3 |
=T("e:/orders/2018c_p.xlsx",A2) |
A1 Read two columns of CustomerId and ProductId in order_2018.xlsx
A2 Group the data by key column, and the @1 option means to take only one record in the group
A3 Write the data in A2 into 2018c_p.xlsx
2. Keep only duplicates
Example: Find the orders placed by the repeat customers (customers who bought the same product multiple times) in 2018, and store the results in 2018c_rebuy.xlsx.
The esProc SPL script is as follows:
A |
|
1 |
=T("e:/orders/order_2018.xlsx") |
2 |
=A1.group(CustomerId,ProductId) |
3 |
=A2.select(~.count()>1).conj() |
4 |
=T("e:/orders/2018c_rebuy.xlsx",A3) |
A1 Read the data of order_2018.xlsx
A2 Group the data by key column. The orders from the same customer for the same product are divided into a group
A3 Select groups with orders greater than 1, and concatenate the orders of each group into a data table
A4 Write the data in A3 to 2018c_rebuy.xlsx
SPL Official Website 👉 http://www.scudata.com
SPL Feedback and Help 👉 https://www.reddit.com/r/esProc
SPL Learning Material 👉 http://c.scudata.com
SPL Source Code and Package 👉 https://github.com/SPLWare/esProc
Discord 👉 https://discord.gg/ydhVnFH9
Youtube 👉 https://www.youtube.com/@esProc_SPL

