

How to easily handle text file calculations in Java?
To other questions:
How to easily consolidate data from different sources in Java?
What should a Java programmer do when it is too difficult to write complex SQL?
What is the lightweight Java library to read and write Excel dynamically?
What would be a dynamic and flexible way to transform Json to Java object?
How to perform SQL-like queries on MongoDB in Java?
What should I do when it is difficult to implement code with Java Stream?
Solution: esProc – the professional computational package for Java
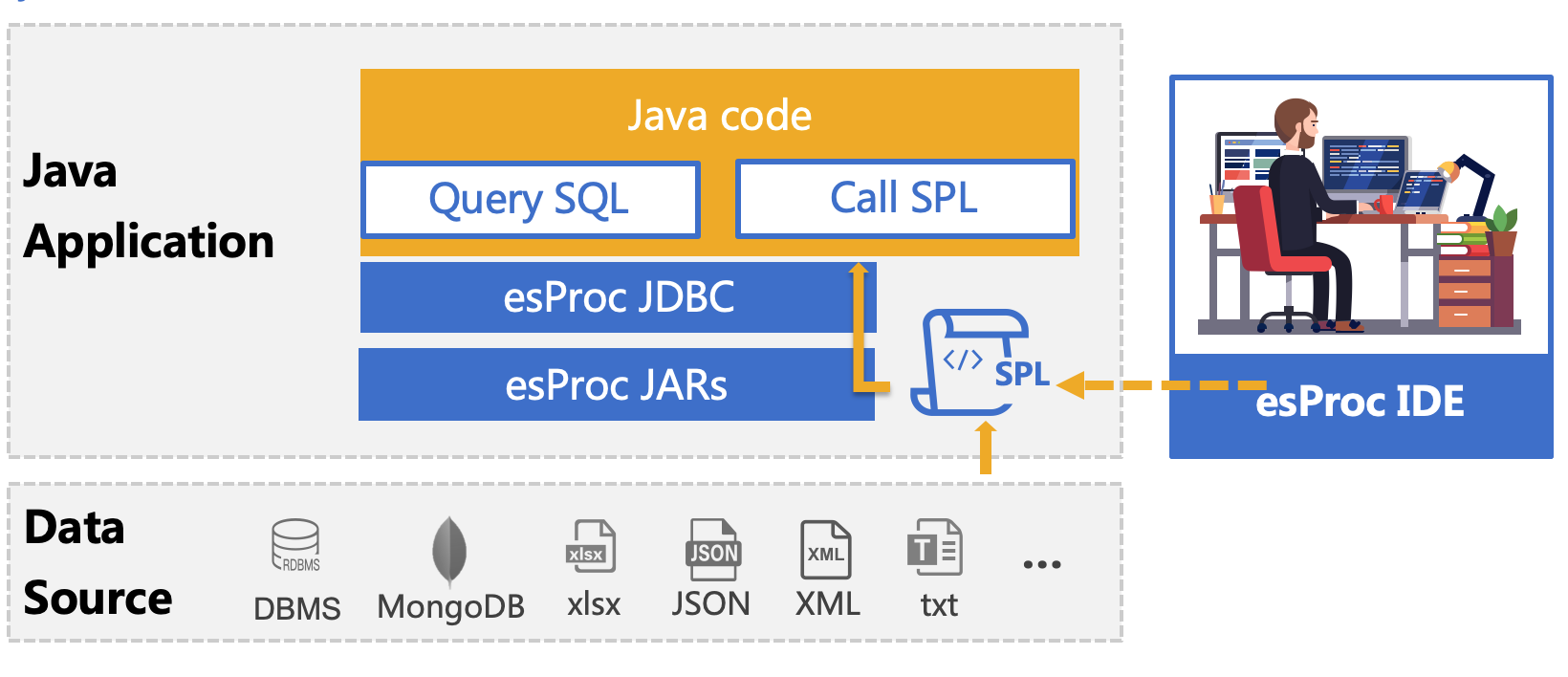
esProc is a class library dedicated to Java-based calculations and aims to simplify Java code. SPL is a scripting language based on the esProc computing package. It can be deployed together with Java programs and understood as a stored procedure outside the database. Its usage is the same as calling a stored procedure in a Java program. It is passed to the Java program for execution through the JDBC interface, realizing step-by-step structured computing, return the ResultSet object.
Regular text query
Java only provides relatively basic low-level functions and lacks professional structured data calculation functions, such as data set filtering, sorting, group-summarizing, joining, etc. All need to be written by programmers, and it is very simple to read with SPL.
For example: find classes with an average English score of less than 70.
A |
|
1 |
=T(“E:/txt/Students_scores.txt”) |
2 |
=A1.groups(CLASS;avg(English):avg_En) |
3 |
=A2.select(avg_En<70) |
This block of code can be debugged or executed in esProc IDE, or stored as a script file (like condition.dfx) for invocation from a Java program through the JDBC interface. Below is the code for invocation:
package Test;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
public class test1 {
public static void main(String[] args)throws Exception {
Class.forName("com.esproc.jdbc.InternalDriver");
Connection connection =DriverManager.getConnection("jdbc:esproc:local://");
Statement statement = connection.createStatement();
ResultSet result = statement.executeQuery("call condition.dfx");
printResult(result);
if(connection != null) connection.close();
}
…
}
This is similar to calling a stored procedure. SPL also supports the SQL-like way of embedding the code directly into a Java program without the need of storing it as a script file. Below is the code for embedding:
…
ResultSet result = statement.executeQuery("
=file(\"D:\\sOrder.csv\").groups(CLASS;avg(English):avg_En).select(avg_En<70)");
…
For details on integration with Java programs, please refer to How to Call an SPL Script in Java
Use SPL to realize multi-text association calculation:
For example, the sales order information and product information are stored in two text files, respectively, and calculate the sales amount of each order. The data structure of the two files is as follows:

A |
|
1 |
=T(“e:/orders/sales.csv”) |
2 |
=T(“e:/orders/product.csv”).keys(ID) |
3 |
=A1.join(ProductID,A2,Name,Price) |
4 |
=A3.derive(Quantity*Price:amount) |
There are many texts with the same structure in a directory, and the query summary after merging with SPL is also very simple:
| A | |
| 1 | =directory@p("./"+user+"/*.csv") |
| 2 | =A1.conj(file(~).import@tc()) |
| 3 | =A2.groups('Customer ID':CID,year('Purchase Date'):Year; 'Customer Name':Customer,sum('Sale Amount'):Total,round(avg('Sale Amount'),1):Average) |
| 4 | =A3.select(Year==when).new(Customer,Total,Average) |
SPL provides a complete method of querying file data with SQL:
For example, State, Department, and Employee are stored in 3 text files respectively, query employees in New York state whose manager is in California.
A |
|
1 |
$select e.NAME as ENAME from E:/txt/EMPLOYEE.txt as e join E:/txt/DEPARTMENT.txt as d on e.DEPT=d.NAME join E:/txt/EMPLOYEE.txt as emp on d.MANAGER=emp.EID where e.STATE='New York' and emp.STATE='California' |
Large text calculation
If the amount of data is large, SPL can read data by a cursor, and the calculation can be bound to the cursor. Such as grouping by the Dept field of the Employees table, we summarize the Orders table’s Amount field and implement sorting, association, and group on the cursor calculation. With cursors, we can complete big data calculations in small memory.
A |
|
1 |
=file("E:/txt/Employees.txt").cursor@t().sortx(EId) |
2 |
=file("E:/txt/Orders.txt").cursor@t().sortx(SellerId) |
3 |
=joinx(A2:O,SellerId; A1:E,EId) |
4 |
=A3.groups(E.Dept;sum(O.Amount)) |
Large text computing often needs to add parallel computing to improve computing efficiency. Each thread uses a large file computing method to process a part of the data, and finally, each thread’s processing results are summarized.
For example, the big data file of user login records user_info_reg.csv counts the total number of logins of users in each province. The SPL script is as follows:
| A | |
|---|---|
| 1 | =file(“E:/txt/user_info_reg.csv”).cursor@tcm(;4) |
| 2 | =A1.groups(id_province;count(~):cnt) |
It is very easy to use parallel speed in SPL. @m means parallel computing, and parameter 4 means 4-way parallel. Compared with single-threaded code, there is only one more cursor option and parameter, making it very convenient for users to use parallelism.
Irregular text processing
For example, each line is divided into columns with the same string in order from the beginning, and the other ones are grouped into one column.
col1,col2,clo3,col4
word1,date1,date2,port1,port2,....some amount of port
word2,date3,date4,
....
SPL processing is as follows:
| A | |
|---|---|
| 1 | =file(“file.txt”).import@st() |
| 2 | =A1.(#1.split@c()).new(~(1):col1,~(2):col2,~(3):col3,~.to(4,).concat@c():col4) |
Import text, separated by commas, items 1-3 are divided into one column, and item 4 is divided into one column.
For another example, the text T2.txt is a string of the following line, extracting the state name (LA) before the character US and the number after COOP:.
COOP:166657,'New Iberia Airport Acadiana Regional LA US',200001,177,553
COOP:177562,'Bobo Dioulasso Airport BF',200001,322,682
COOP:179534,'La Tapoa Airport NE',200002,408,514
COOP:196410,'Caribou Municipal Airport ME US',200003,436,658
……
| A | |
|---|---|
| 1 | =file(“T2.txt”).import@c() |
| 2 | =A1.select(pos(_2, “US”)!=null) |
| 3 | =A2.derive(mid(_2, pos(_2,"US")-2, 2):State) |
| 4 | =A3.derive(right(_1, pos(_1,“:”)+1):ID) |
Import the text, filter the second column, the string must contain “US”; find the position of “US”, move 2 positions to the left, and extract 2 characters to the right; find the position of “:”, extract to the right to the end, extract The results are as follows:

esProc also provides regular expressions, but we recommend using conventional methods. esProc IDE supports advanced debugging modes such as single step and breakpoint, which is very convenient to deal with complex disassembly requirements.
More calculation examples
Refer to Use SPL in applications - File calculation
SPL Official Website 👉 http://www.scudata.com
SPL Feedback and Help 👉 https://www.reddit.com/r/esProc
SPL Learning Material 👉 http://c.scudata.com
SPL Source Code and Package 👉 https://github.com/SPLWare/esProc
Discord 👉 https://discord.gg/ydhVnFH9
Youtube 👉 https://www.youtube.com/@esProc_SPL

