

SPL: integrated with Kettle
Object
esProc can write SQL queries directly on data files, as well as SPL scripts to support complex calculations. it provides an embedded JDBC driver to make it easy to return result to application. This article introduces the method of integrating SPL in Kettle through JDBC and different ways to retrieve data.
Integration
Download the Pentaho installation pack, in which the design-tools\data-integration\Spoon.bat is the boot program of Kettle. Before booting, put the esproc-*.jar program into design-tools\data-integration\lib\.
Create a new Transformation named Test, under TEST create a new Database connection named esproc, the join type is Generic Database, the connection method is Native (JDBC) , the driver class of esProc is com.esproc.jdbc.InternalDriver, and URL is jdbc:esproc:local://?config=d:/esProcData/raqsoftConfig.xml, in which the configuration file for esProc, raqsoftConfig.xml, is specified by the parameter.
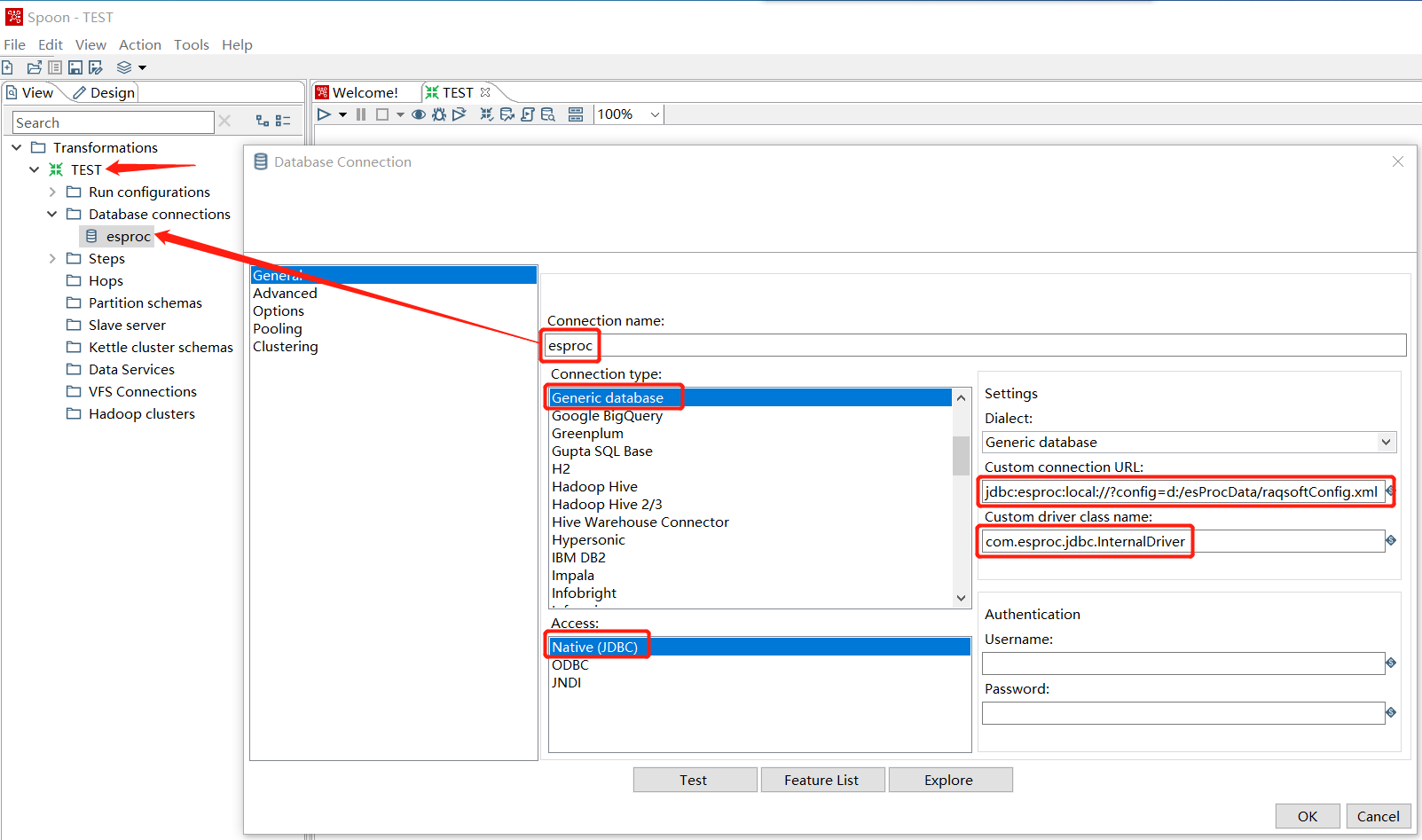
There are two main configurations in raqsoftConfig.xml, mainPath and charSet.
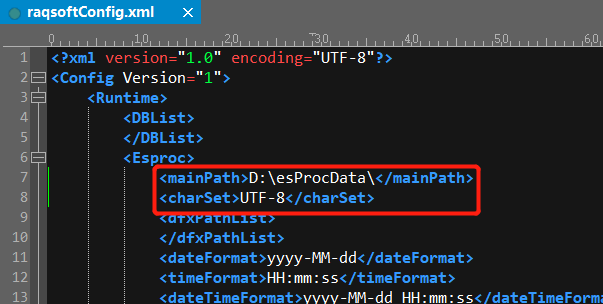
Query file data
There is data file emp.txt in the mainpath of esProc. (Note that the charset must be UTF-8, being consistent with the above configuration, or else the query may fail).
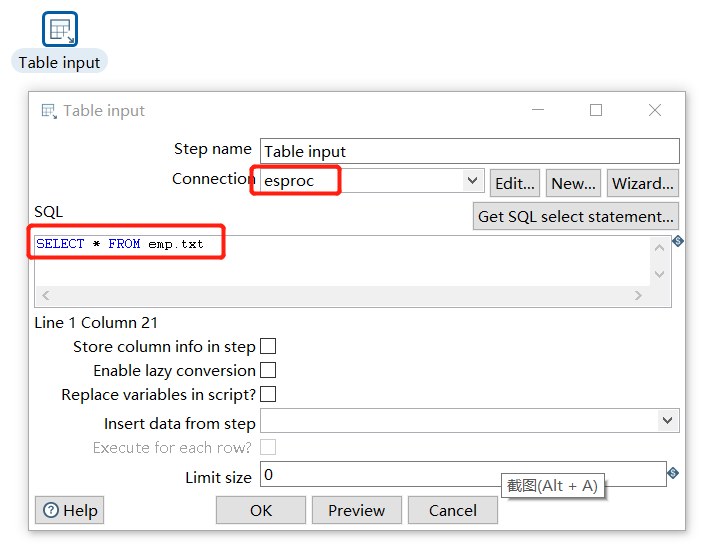
In the Kettle designer, drag a Table input under the Input category
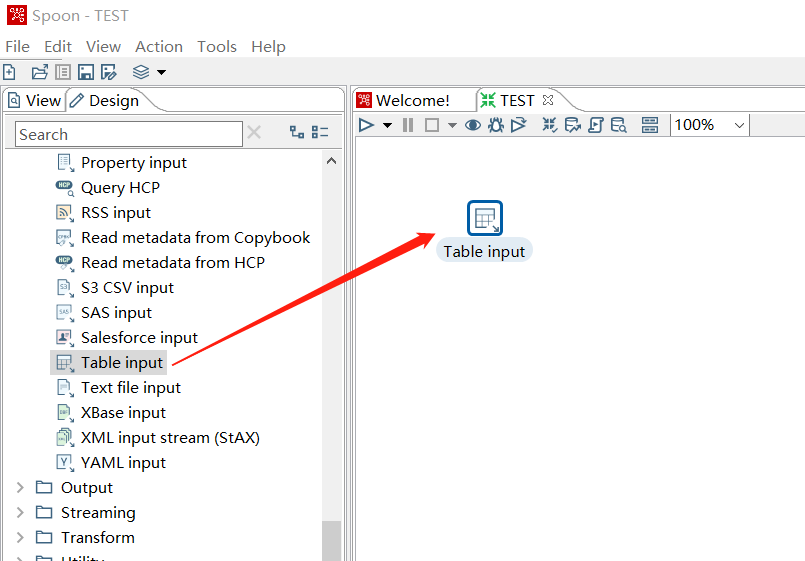
Set Table input, select the esproc connection created earlier, and the SQL statement directly queries emp.txt:
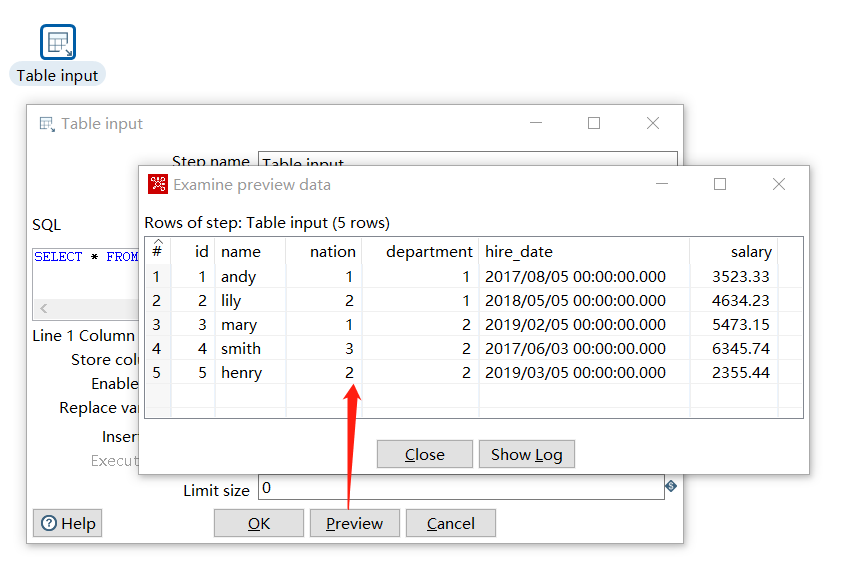
Click the Preview below to see that the query is successful:
Then try conditional query, group query, multi-table join query, data can be successfully queried:
SELECT * FROM emp.txt where id<5 and hire_date<date('2019-01-01')
SELECT department, sum(salary) FROM emp.txt group by department
SELECT e.*,d.name dept_name FROM emp.txt e join dept.txt d on e.department=d.id
The data files also support excel (at this point some poi-related jar packages, poi*.jar which java reads and writes excel, are needed. They can be copied from the lib path of esProc, and there may be different versions of jars, be careful to delete them, and test for compatibility).
SELECT * FROM eml.xlsx
Parameter query
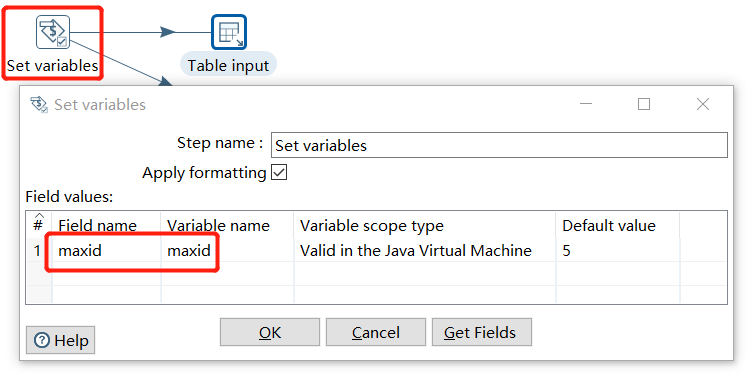
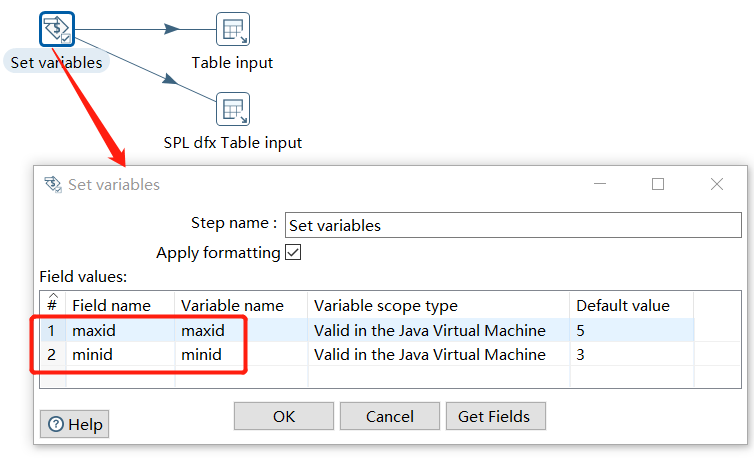
Parameters can also be used in SQL of query file, and add a Set variables step before the Table input:
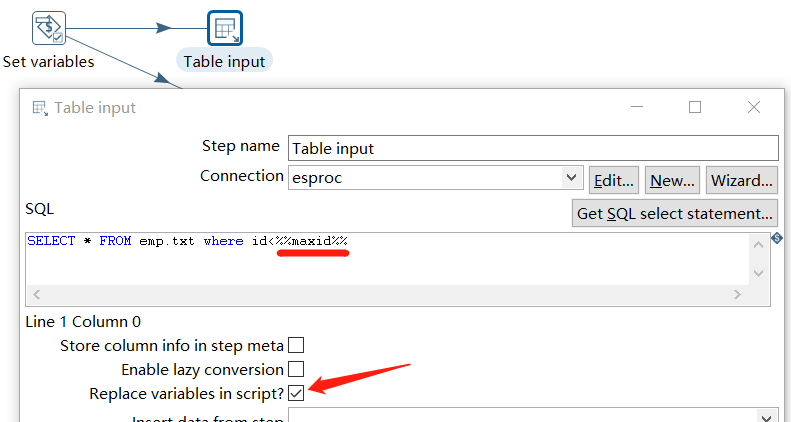
The parameters in SQL are identified with two % before and after, and note that the option to replace the parameters is clicked:
Invoke the SPL script
In addition to directly querying the data files, SPL script files can also be invoked. This is suitable for complex calculations to be encapsulated in *.dfx, the SPL script file. Write a calc.dfx in the esProc designer and put it in the main path:
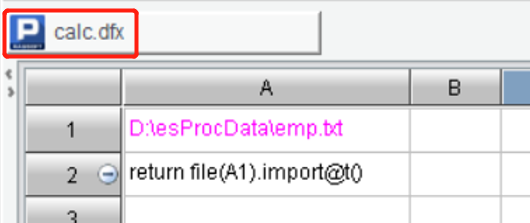
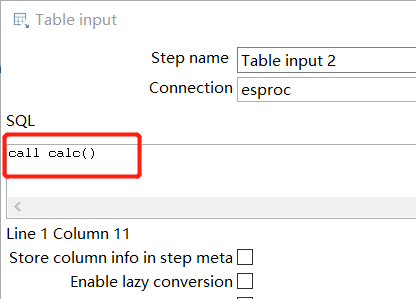
Execute call calc() and the data returned by A2 in calc.dfx can be queried:
Use parameters
The SPL script statement also supports defining (multiple) parameters, defining the maximum ID (maxid) and the minimum ID (minid) :
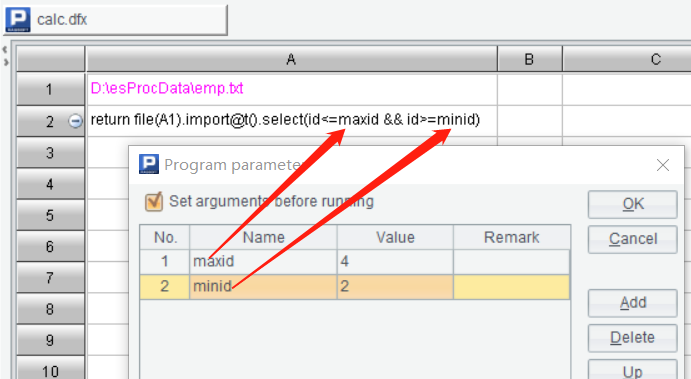
Two parameters, maxid and minid are also defined in Kettle:
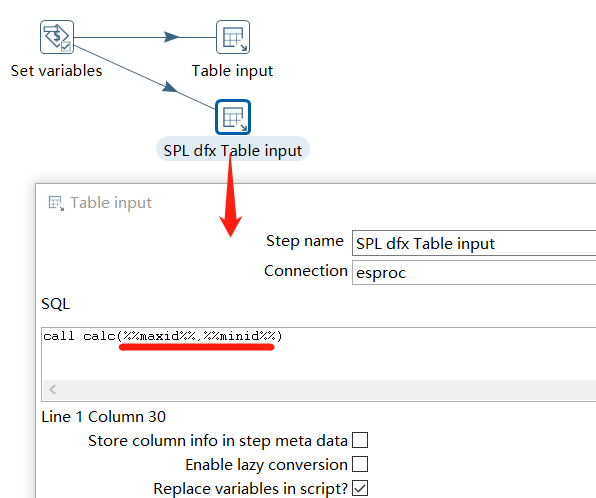
When invoking calc.dfx in Kettle, parameters are passed dynamically as follows:
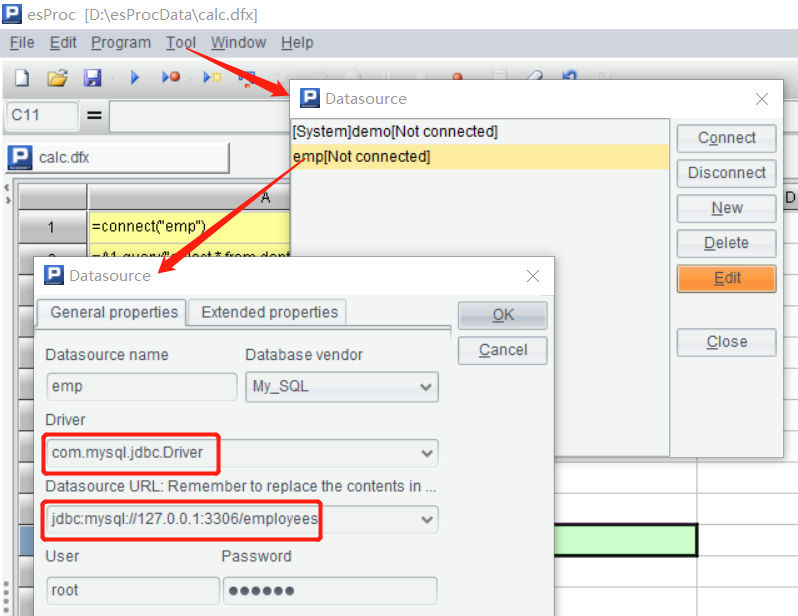
Multiple data sources
Write a SPL script in the designer to set a simple example of associative calculation between Mysql library table and file data table. First define the Mysql data source:
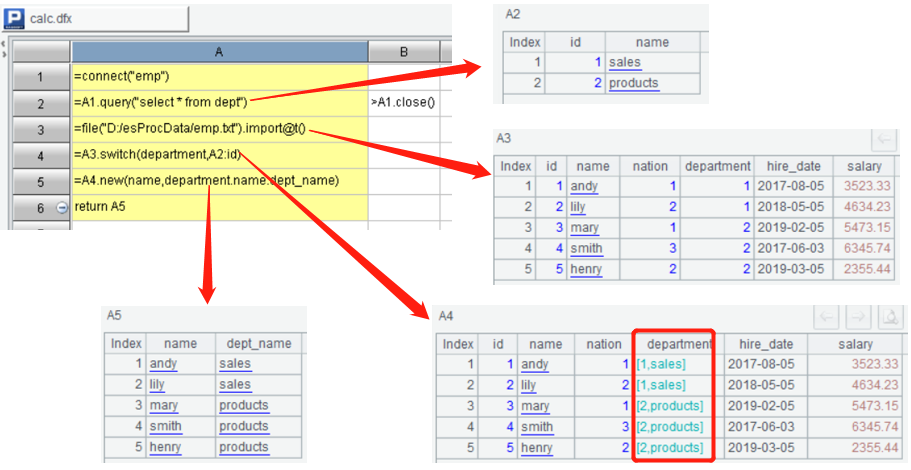
A1 connects to the Mysql data source emp defined above; A2 loads the dept table of the emp database; B2 closes connection of A1; A3 loads emp.txt text data table; A4 associates the tables of two sources; A5 selects the final calculation result (employee name, department name) from the associated data; A6 returns the result to the main program.
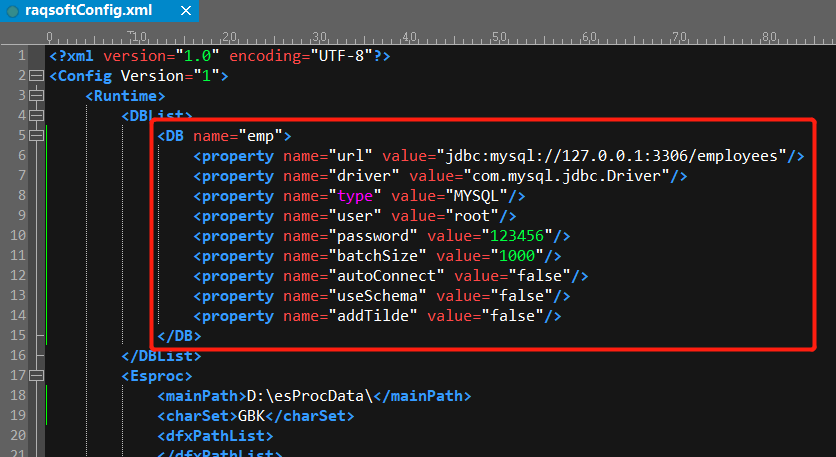
At this point, the SPL script can not be invoked directly in Kettle. First of all, put the JDBC driver jars of Mysql(mysql-connector-java-*.jar) into design-tools\data-integration\lib\, and then edit the esProc configuration file raqsoftConfig.xml with the definition of the emp data source:
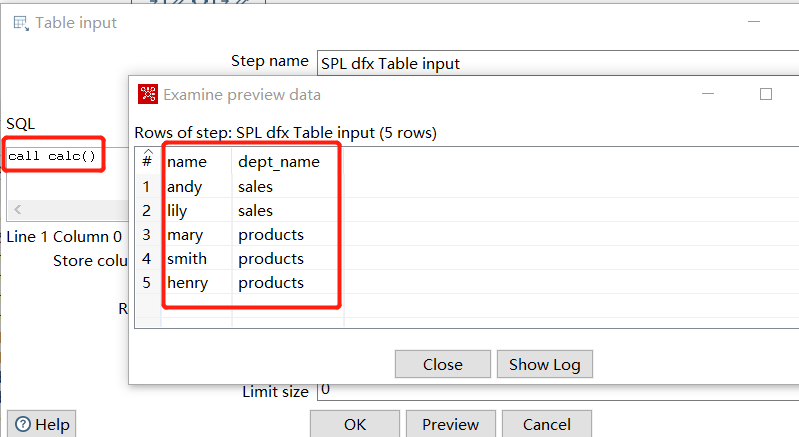
Then invoke it in Kettle and it will execute successfully:
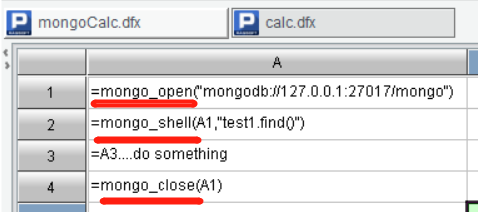
The data sources supported in SPL scripts are rich and fall into three main types:
various relational databases connected to JDBC/ODBC, Oracle/Mysql/DB2/SQL Server…; text data like txt, excel, xml, csv, json…; some non-relational databases like hadoop, mongodb, hbase, spark…, which is read through built-in external library. Refer to the script below that reads mongodb.
Epilogue
The SPL script is a JAVA-implemented computing engine that is easy to be embedded into any JAVA environment. When the Kettle task file created above is deployed to WEB service such as tomcat, weblogic, etc. , the involved SPL jar, configuration files, and script files can be brought along (put jars in WEB-INF/lib; configuration files, script files in the server’s specified directories, and properly configure the main path) .
SPL Official Website 👉 http://www.scudata.com
SPL Feedback and Help 👉 https://www.reddit.com/r/esProc
SPL Learning Material 👉 http://c.scudata.com
SPL Source Code and Package 👉 https://github.com/SPLWare/esProc
Discord 👉 https://discord.gg/ydhVnFH9
Youtube 👉 https://www.youtube.com/@esProc_SPL

