

SPL Programming - 8.5 [Data table] Calculations on the fields
As we said earlier, the ability of structured data in row and column directions is asymmetric. Convenient batch operations are usually only provided for row direction, and columns always appear as independent individuals. However, we also need to perform some overall operations in the column direction sometimes, that is, to process a batch of fields together as a set.
Let’s do the problem of merging Excel again. Change the requirement to: spell the file name in front of all columns.
The derive()function can only append fields to the end. To change the order of fields, we can only recreate with new() function for the present, and we need to know what fields are already in the table sequence and copy them again.
The fname()function can return a sequence of field names in the table sequence, that is, a sequence of strings. But this is not enough. Even if we concatenate the new field to the front, we still don’t know how to write this new() function, such as the following code:
| A | |
|---|---|
| 1 | =10.new(rand(10):a,rand(20):b,rand(30):c) |
| 2 | =A1.fname() |
| 3 | =A1.new(0:NewField, A2) |
A1 is a table sequence, A2 gets its field name sequence, but A3 is meaningless. SPL will generate a field named A2, and its value is the current cell value of A2, that is, the field name sequence of A1. When SPL executes here, it does not know to concatenate the value of A2 into this code, but will execute the two characters A and 2 as part of the code.
What should we do?
SPL provides the syntax of dynamic program. The above code is written as follows, and it can be executed correctly:
| A | |
|---|---|
| 1 | =10.new(rand(10):a,rand(20):b,rand(30):c) |
| 2 | =A1.fname().concat(“,”) |
| 3 | =A1.new(0:NewField, ${A2} ) |
We have used the concat() function. It will concatenate a string sequence with the specified separator, and here we use commas. Here A1 has three fields a,b,c, and the calculation result of A2 is the string “a,b,c”.
The meaning of ${} in A3 is to tell SPL to calculate the expression in braces (it will be a string), then spell the string as part of the statement, and then execute it. A2 is now “a,b,c”, ${A2} will spell this string into the statement in A3. As a result, the actual statement to be executed by A3 is
=A1.new(0:NewField, a,b,c)
That’s what we want.
The syntax of ${} is called a macro. Using macros, we can dynamically spell some code to execute, and achieve a very flexible operation effect. Calculations related to uncertain number fields often use macros.
Using macros, we can solve the problem of spelling the file name to the front in merging Excel:
| A | B | |
|---|---|---|
| 1 | =directory@p(“data/*.xlsx”) | |
| 2 | for A1 | =file(A2).xlsimport@t() |
| 3 | =B2.new(filename@n(A2):File,${B2.fname().concat@c()}) | |
| 4 | =@|B3 | |
| 5 | =file(“all.xlsx”).xlsexport@t(B4) | |
concat@c()means to separate by commas. A calculation expression can be written in ${} as long as the calculation result is a string.
Using macros, we can easily generate the student score table:
| A | |
|---|---|
| 1 | [English,Maths,Science,Arts,PE] |
| 2 | =A1.(“rand(100):”+~).concat@c() |
| 3 | =100.new(string(~,“0000”):id, ${A2}) |
The calculation result of A2 will be a string:
“rand(100):Engligh,rand(100):Maths,rand(100):Science,rand(100):Arts,rand(100):PE”
After spelling into A3, we will get a score table of 100 students, and the id field is the student number of the student.
Now we want to calculate a total score field Total for each student and append it to the end.
| A | |
|---|---|
| … | … |
| 4 | =A3.derive(English+Maths+Science+Arts+PE:Total) |
Of course, it’s OK, but if there are many subjects, it’s hard to write.
SPL provides a method to convert record fields into a sequence, and it is much more convenient when field values need to be processed in batch:
| A | |
|---|---|
| … | … |
| 4 | =A3.derive(~.array().to(2,).sum():Total) |
r.array()gets the field values of record r to form a sequence and return. In this way, no matter how many subjects, the code is like this. It should be noted that since the data types of each field value may be different, the return value of array() may not be a sequence composed of members of the same data type.
With macros, we can also complete more complex tasks.
All of the Excel files we have previously processed are in row format. However, just as we talked about the concept of structured data, many Excel files storing structured data are not in row format, such as:
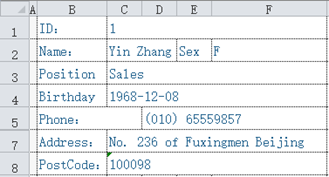
(This is part of the previous example. There is only one record to simplify the problem.)
Suppose there are a batch of such files, each file stores a person’s information. Now we hope to extract these data and make a row table, using the field names in this table: ID, name, sex, postion, birthday, phone, address, postcode.
If there are hundreds of such files, it will obviously be too tiring to do it manually. We use a program to do it.
To do this, we also need to use two Excel related functions xlsopen()and xlscell().
xlsopen()can open an Excel file to form an Excel object, and xlscell() can read the content of a cell from the Excel object. With them, we can finish the work.
| A | B | C | |
|---|---|---|---|
| 1 | =create(ID,Name,Sex,Postion,Birthday,Phone,Address,PostCode) | ||
| 2 | =directory@p(“data/*.xlsx”) | ||
| 3 | for A2 | =file(A3).xlsopen() | |
| 4 | =B3.xlscell(“C1”) | =B3.xlscell(“C2”) | |
| 5 | =B3.xlscell(“F2”) | =B3.xlscell(“C3”) | |
| 6 | =B3.xlscell(“C4”) | =B3.xlscell(“D5”) | |
| 7 | =B3.xlscell(“C7”) | =B3.xlscell(“C8”) | |
| 8 | =A1.insert(0,B4,C4,B5,C5,B6,C6,B7,C7) | ||
| 9 | >file(“all.xlsx”).xlsexport@t(A1) | ||
The code logic is not complex, and we will not explain it in detail.
However, it is still a little troublesome to write, and if the table style and data structure change, it needs to be changed a lot.
We use macros and loop functions to simplify it.
| A | B | C | ||
|---|---|---|---|---|
| 1 | [ID,Name,Sex,Postion,Birthday,Phone,Address,PostCode] | |||
| 2 | [C1,C2,F2,C3,C4,D5,C7,C8] | |||
| 3 | =directory@p(“data/*.xlsx”) | |||
| 4 | for A3 | =file(A4).xlsopen() | =B2.(B4.xlscell(~)) | |
| 5 | =@ | C4 | ||
| 6 | =create(${A1.concat@c()}).record(B5) | |||
| 7 | >file(“all.xlsx”).xlsexport@t(A6) | |||
The fields and corresponding cells are made into two sequences, and it is much easier to get data from each Excel file and do concatenation. The code is not only shorter, but also more general. If we encounter a new format, just modify the first two lines.
Conversely, we may use the data of a row table to generate multiple such free-style Excel. Obviously, doing it manually will be very tiring.
We still use a program to complete this task. We need to learn a little more knowledge: the xlscell()function can also fill data into a cell of an Excel object; and then learn an xlswrite() function, which can write the processed Excel object into a file.
| A | B | C | |
|---|---|---|---|
| 1 | [ID,Name,Sex,Postion,Birthday,Phone,Address,PostCode] | ||
| 2 | [C1,C2,F2,C3,C4,D5,C7,C8] | ||
| 3 | =file(“temp.xlsx”).xlsopen() | ||
| 4 | =file(“all.xlsx”).xlsimport@t() | ||
| 5 | for A4 | =A1.(A5.field(~)) | >A2.(A3.xlscell(~;B5(#))) |
| 6 | =file(A5.ID/“.xlsx”).xlswrite(A3) | ||
First make a template Excel file in this format, read it into an Excel object, and then fill the relevant values into the Excel object for each record, and then write it into a file. Fill them in and write it out repeatedly, and it’s done.
When doing artificial intelligence tasks, we often encounter the problem of filling in missing values, that is, filling in the missing data according to certain rules, such as mode (the most frequent of other non missing values) or average (calculated from other non missing values).
Let’s try this task. Suppose data.xlsx stores the original data:
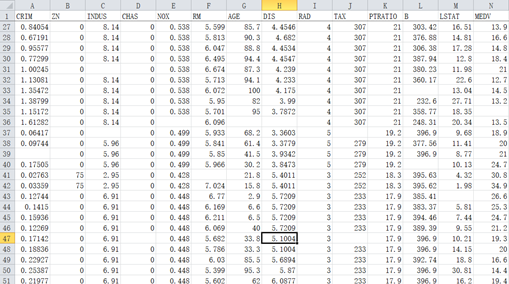
The blank part indicates missing. Our rule is: if this column is an integer, fill it with the mode scheme; If it is a floating-point number, it is filled with the average scheme.
| A | B | C | |
|---|---|---|---|
| 1 | =file(“data.xlsx”).xlsimport@t() | ||
| 2 | for A1.fname() | =A1.field(A2) | |
| 3 | =B2.sum() | =B2.sum(int(~)) | |
| 4 | =if(B3==C3,B2.mode(),B2.avg()) | ||
| 5 | =B2.(if(~,~,B4)) | >A1.field(A2,B5) | |
| 6 | >file(“dataNew.xlsx”).xlsexport@t(A1) | ||
Read the data into table sequence A1, A2 loops through each field. The field()function in B2 will get all the values of a certain field of all records to form a sequence. It is a bit like A1.(x), but the difference is that the parameter of the field()function here is a string, while x in A1.(x) is a field name. If it is written in A1.(x), a macro needs to be used and it should be written as A1.(${A2}).
Calculate the sum of the whole column, compare it with the sum of the integerized members, if it is equal, it can be regarded as all integers, then execute the mode scheme, otherwise execute the average scheme. The mode() function can return the mode of the sequence.
Then calculate the field value sequence after filling in the missing values in B5. The field()function can also fill the sequence into the field. Here, it can also be written as A1.run(${A2}=B5(#)) in macro, but it is obviously clearer and simpler using the field() function.
SPL Programming - Preface
SPL Programming - 8.4 [Data table] Loop functions
SPL Programming - 9.1 [Grouping] Grouping and aggregation
SPL Official Website 👉 http://www.scudata.com
SPL Feedback and Help 👉 https://www.reddit.com/r/esProc
SPL Learning Material 👉 http://c.scudata.com
SPL Source Code and Package 👉 https://github.com/SPLWare/esProc
Discord 👉 https://discord.gg/ydhVnFH9
Youtube 👉 https://www.youtube.com/@esProc_SPL

