

How Reporting Tools Access TXT/CSV/XLS Data
Reporting tools generally support file sources, such as txt/csv/xls. Yet they only provide basic computing abilities for computing files with regular formats. They need to find indirect ways to handle complicated computing tasks or files with irregular formats. A popular solution is to use the user-defined data set plus the third-party class library. There are various file handling class libraries. They have strong parsing abilities but weak computing abilities. A lot of hard coding work is needed to achieve computing tasks. Another way is to execute SQL directly on files using CSVJDBC/XLSJDBC. The solution is integration-friendly and easy to learn, but it has weak parsing and computing abilities, does not have date functions and string functions, and provides no support of join operations, set-oriented operations and subqueries.
The wise choice is to use SPL. The Java-based, open-source class library offers powerful computational capabilities, is able to parse files with irregular formats, and has JDBC interface that is easy to integrated by reporting tools.
SPL provides analytic functions of simplistic syntax. The library can use one T function to parse regular files of various formats:
T("d:/Orders.csv") // Comma-separated and the first row contains column names
T("d:/Employees.txt) // Tab-separated and the first row contains column names
T("d:/data.xls") // The row-wise xls/xlsx and the first row contains column names
SPL has a wealth of built-in functions for processing file data using simple and intuitive syntax, without the need of any complicated hardcoding. To perform a query on orders data according to interval-style conditions, for instance, we have the following SPL code, where p_start and p_end are parameters:
A |
|
1 |
=T("d:/Orders.csv") |
2 |
select(Amount>p_start && Amount<=p_end)=A1. |
3 |
return A2 |
As code written in an RDB, SPL code can be integrated into a reporting tool through its JDBC driver. Take the above SPL code as an example, we can first save it as a script file (intervalQuery.splx) and then invoke it in the reporting tool as we do with a stored procedure. Suppose we are using Birt and the code is as follows:
{call intervalQuery(? , ?)}
More examples:
A |
B |
|
1 |
… |
|
2 |
=A1.select(Amount>1000 && like(Client,\"*S*\")) |
//Fuzzy query |
3 |
=A1.sort(Client,-Amount)" |
//Sort |
4 |
=A1 .id(Client) |
//Distinct |
5 |
=A1.groups(year(OrderDate);sum(Amount)) |
//Grouping & aggregation |
6 |
=join(A1:O,SellerId; T("D:/Employees.txt"):E,EId).new(O.OrderID, O.Client,O.Amount,E.Name,E.Gender,E.Dept) |
/Join |
It is easy for SPL to handle files of irregular formats:
To parse a CSV file using the special double horizontal line as the separator:
= file("D:/Orders.txt").import@t(;,"--").select(Amount>1000 && Amount<=3000)
In the file, every three lines forms one record, and the second line contains multiple fields. We are trying to reorganize the file into a standard two-dimensional table sorted by the 3rd and the 4th fields:
A |
|
1 |
=file("D:\\data.txt").import@si() |
2 |
=A1.group((#-1)\3) |
3 |
=A2.new(~(1):OrderID,(line=~(2).array("\t"))(1):Client,line(2):SellerId,line(3):Amount,~(3):OrderDate ) |
4 |
=A3.sort(_3,_4) |
It is simple for SPL to handle XLS files of irregular formats. Here are some common examples:
// To import a file without column names where detail data begins from the first row:
=file("D:/Orders.xlsx").xlsimport()
// To import a file by skipping the title area in the second row:
=file("D:/Orders.xlsx").xlsimport@t(;,3)
// To import rows from the 3rd to the 10th:
=file("D:/Orders.xlsx").xlsimport@t(;,3:10)
// To import only three columns:
=file("D:/Orders.xlsx").xlsimport@t(OrderID,Amount,OrderDate)
// To import data from the specified “sheet3”:
=file("D:/Orders.xlsx").xlsimport@t(;"sheet3")
The xlsimport function can also import N rows backward, open a big file using a password, and read data from a big file. We just skip the detailed explanations about them here.
SPL also supports standard SQL syntax, including plenty of string functions and date functions, join operations, set-oriented operations and subqueries. To accomplish the above query based on interval-style conditions, we can create a SQL data set in the reporting tool and write the following SQL statement:
$select * from d:/Orders.csv where Amount>? and Amount<=?
To perform a join:
$select e.name, s.orderdate, s.amount from sales.xls s left join employee.csv e on s.sellerid= e.eid
More examples can be found in Examples of SQL Queries on Files.
SPL possesses outstanding computational capabilities to simplify computations with complex logic, including stepwise computations, order-based computations and post-grouping computations. SPL can deal with many computations effortlessly that are hard to handle in SQL. Here is an example. We are trying to find the first n big customers whose sales amount occupies at least half of the total and sort them by amount in descending order.
A |
B |
|
1 |
… |
/ Retrieve data |
2 |
=A1.sort(amount:-1) |
/ Sort data by amount in descending order |
3 |
=A2.cumulate(amount) |
/ Get the sequence of cumulative totals |
4 |
=A3.m(-1)/2 |
/ The last cumulative total is the final total |
5 |
=A3.pselect(~>=A4) |
/ Get position of record where the cumulative total reaches at least half of the total |
6 |
=A2(to(A5)) |
/ Get values by position |
In the following Excel sheet, every 8 rows constitute one record whose fields are scattered among different cells. We are trying to retrieve records one by one and generate a standard two-dimensional table.
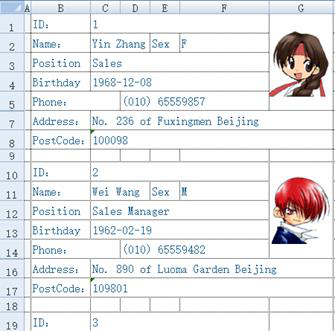
This is a complicated, multi-step task that involves loop control and order-based computation. For class libraries like POI, it is a heavy project while for SPL, it is simple and easy. Below is the short SPL code:
A |
B |
C |
|
1 |
=create(ID,Name,Sex,Position,Birthday,Phone,Address,PostCode) |
||
2 |
=file(“e:/excel/employe.xlsx").xlsopen() |
||
3 |
[C,C,F,C,C,D,C,C] |
[1,2,2,3,4,5,7,8] |
|
4 |
for |
=A3.(~/B3(#)).(A2.xlscell(~)) |
|
5 |
if len(B4(1))==0 |
break |
|
6 |
>A1.record(B4) |
||
7 |
>B3=B3.(~+9) |
||
SPL has a professional IDE equipped with all-around debugging functionalities and lets users observe the result of each step with grid-style coding, making it particularly suited to developing algorithms with complex logic.

SPL also supports many more data sources, including WebService, RESTful, MongoDB, Hadoop, Redis, ElasticSearch, SalesForce, and Cassandra, and the mixed computations between any types of data sources or databases.
SPL Official Website 👉 http://www.scudata.com
SPL Feedback and Help 👉 https://www.reddit.com/r/esProc
SPL Learning Material 👉 http://c.scudata.com
SPL Source Code and Package 👉 https://github.com/SPLWare/esProc
Discord 👉 https://discord.gg/ydhVnFH9
Youtube 👉 https://www.youtube.com/@esProc_SPL


Chinese version