

Open-source SPL speeds up batch operating of bank loan agreements by 10+ times
Abstract
The execution of stored procedure for bank L’s loan agreements takes 2 hours, which seriously affects the whole batch operating task! How to solve it? Click to learn: Open-source SPL speeds up batch operating of bank loan agreements by 10+ times
Problem description
The batch operating task of bank L includes many stored procedures, among which the stored procedure for “corporate loan agreement details” runs for 2 hours, and has become the bottleneck of the whole batch operating task and needs to be optimized as soon as possible.
The operation log of this stored procedure shows that there are 48 steps for storing the details of corporate loan agreements. Each step consists of several main SQLs and some auxiliary SQLs, with a total of 3300 lines. The following figure shows the execution time of each step:

Solution
First, in-depth understanding of the characteristics of data and calculation. The said 48 steps of the stored procedure are relatively complicated, but each step basically consists of three parts: 1. execute the main SQLs; 2. save the results as a temporary table; 3. create an index on the temporary table. When executing the main SQLs, the temporary table generated in the previous step is generally used.
Let's take the longest time-consuming steps 7 and 8 as an example to see the specific characteristics of data and calculation. Step 7 takes 49 minutes, and the main SQL statement is to filter a large table with a small table, and there are other filtering conditions. The desensitized SQL statement is as follows:
select
B_NO,
CUST_NO,
BAL,
nvl(nullif(a.D_BILL, ''), a.BILL_NO),
BEGIN_DATE,
END_DATE
from
BOOK_ HIS a
WHERE CORP = v_corp
and v_sDate >= BEGIN_DATE and v_eDate <= END_DATE
and not exists(
select 1
from SESSION.TMP_BILL d
WHERE nvl(nullif(a.D_BILL, ''), a.BILL_NO)=d.R_NO
)
In the loan standing book information history table BOOK_HIS, there are 110 million pieces of data and 78 fields, and 7 fields are involved in the calculation, and the primary keys are CORP, D_BILL, BEGIN_DATE, and END_DATE.
SESSION.TMP_W_BILL is the temporary table generated in the previous step, which is obtained by conditionally filtering the enterprise loan principal table D_HIS_P, and has a data amount of about 2.44 million. In step 7, it needs to use the IOU number in the TMP_BILL table to filter BOOK_HIS, and then save the calculation results as a temporary table, and finally create an index based on CUST_NO and R_NO respectively to prepare for the next step.
Step 8 takes 36 minutes, and uses two small tables to filter the temporary table generated in step 7, and then perform the grouping and aggregating according to RC_NO.
SELECT LN_R_NO,
SUM(CASE WHEN v_sDate_LM BETWEEN BEGIN_DATE AND END_DATE THEN BAL END) BAL_LM,
…
SUM(CASE WHEN v_sDate_LY BETWEEN BEGIN_DATE AND END_DATE THEN BAL ELSE 0 END) BAL_LYY
FROM session.BOOK_HIS_TEMP a
WHERE (
exists(select 1 from CUST b where a.CUST_NO=b.CUST_NO and b.CORP=v_corp and v_sDate BETWEEN b.BEGIN_DATE AND b.END_DATE)
or
exists(select 1 from session.SALE_BILL c WHERE a.R_NO=c.R_NO)
)
GROUP BY R_NO
The history table for the basic information of corporate customers CUST has 570,000 pieces of data in total, and the session.SALE_BILL is filtered from the ACC table (32,000 pieces of data). The amount of data of both tables is not very large.
The server for batch operating is a 16-core CPU with 32G memory. The data is incrementally updated from the production database into the DB2 database through ETL every day.
Second, determine the optimization idea. Since the server memory is not large enough to load the large table such as BOOK_HIS into the memory, the method of calculating large table in external storage, and calculating small table in memory is adopted.
In step 7, the large table BOOK_HIS will associate with the small table for filtering, and the results will further filter with the two small tables in step 8. The three small tables in the two steps can all use the all-in-memory computing, therefore, we consider creating a cursor for the large table, so as to complete the conditional filtering, the association filtering of three small tables, and the final grouping and aggregating in one traversal. In this way, the time for writing the intermediate results into the hard disk and the time for building an index can be spared.
Filter the large table BOOK_HIS by CORP, BEGIN_DATE and END_DATE, we consider orderly storing this large table by CORP, BEGIN_DATE, END_DATE, so as to quickly filter and find the required data.
Perform the not exists association calculation between the large table BOOK_HIS and the small table SESSION.TMP_BILL. The associated field is the expression of two fields of large table. When traversing the large table, calculate the expression first, and then do the association filtering directly.
Since the large table BOOK_HIS needs to associate and filter with two small tables cust and session.SALE_BILL respectively, and the results need to be DISTINCTed and merged, we will adopt the method of traversing the large table once, calculating the two association and filtering in batches in the memory, and merging the results. In this way, we can guarantee that the large table is traversed by only once. Such algorithm is called multipurpose traversal.
The final grouping and aggregating results are also not large, and can be calculated by in-memory aggregating to the result set.
The large table BOOK_HIS has 78 fields, among which 7 fields involve in the calculation; each of the small tables has only one field involved in the calculation. Therefore, it is suitable to use the columnar storage method, which can decrease the amount of data read from the hard disk and improve the performance.
After the two steps are combined, the large table is traversed once, and the multi-thread parallel computing can be used to give full play to the computing power of the 16-core CPU, and improve the computing speed.
Thirdly, determine the technical selection and implementation scheme. Since the relational databases are based on the theory of unordered set, there is no way to achieve the physically ordered storage of the large table BOOK_HIS.
In addition, if the two main SQLs in steps 7 and 8 were merged into one SQL, it would be more complicated, and it is difficult for the database automatic optimization mechanism to achieve the best query path. Actual test also shows that the performance will decrease sharply when multiple temporary tables are associated, and hence the whole stored procedure is reconstructed and split into many SQLs. That is to say, the above optimization scheme cannot be implemented in SQL in relational databases.
If the relational database is not used, storing the data in an external file to process will be more convenient. Since the server memory is not large in capacity, it cannot hold all data, and cannot implement the all-in-memory calculation technology (including some optimized in-memory databases).
The newly added data used for batch operating is exported from the production database to the batch operating database every day. Since the data was to move in the first place, we can write them to the file during the moving process to implement the high-performance algorithms described above. The file system is better in the IO performance, thus writing the data into the file will be faster than writing into the database. Moreover, storing the data externally is also feasible in practice.
If the high-level language such as Java or C++ was used based on the external file, it could implement the above algorithms; however, the amount of coding is too large and the implementation cycle is too long, as a result, it is prone to hidden trouble with code errors, and it is also difficult to debug and maintain.
The open-source esProc SPL provides support for all the above algorithms, including mechanisms such as the high-performance columnar storage file, file cursor, multi-thread parallel computing, small result in-memory grouping and cursor reuse, which allows us to quickly implement this personalized calculation with less amount of code.
Finally, implement the scheme. First, export the large table BOOK_HIS used in the stored procedure as an SPL columnar storage composite table file. It will take a long time to export for the first time, and after that, it will take a short time because it only needs to export the incremental data and merge them in an orderly manner every day. Actual test found that the newly added data is 1.37 million, and the time for orderly merging is 5 minutes. The small tables used can be either completely exported every day, or incrementally exported.
Then write SPL code to implement the calculation requirements of the original stored procedure. The stored procedure for the details of corporate loan agreement is merely one of many stored procedures of batch operating tasks, which has a sequential relationship with other stored procedures. Therefore, the bypass acceleration method should be adopted, and the calculation results should be written back to the database, see the figure below:

esProc SPL supports the command line calling, and the stored procedure for batch operating of DB2 database can call the written SPL code through the command line. Moreover, SPL supports the JDBC driver, which allows us to use third-party scheduling tools to call.
Application effect
After a few weeks of programming and debugging, the optimization of stored procedure for the details of corporate loan agreement is completed, and the effect is obvious. Under the condition of using the same hardware, the running time before optimization is 2 hours, while it only takes 10 minutes to complete the calculation after optimization, the performance is improved by 12 times.
In terms of programming difficulty, SPL has made a lot of encapsulations, provided rich functions, and built-in the basic algorithms and storage mechanisms required by the above optimization scheme. Although the algorithms described above are relatively complex, the actual code is not long, much less than original SQL, and the development efficiency is very high. The original stored procedure needs more than 3300 lines to implement, after recoding in SPL, it can be implemented by SPL statements that only occupies around 500 cells. As a result, the amount of code is decreased by more than 6 times, which greatly improves the ease of maintenance.
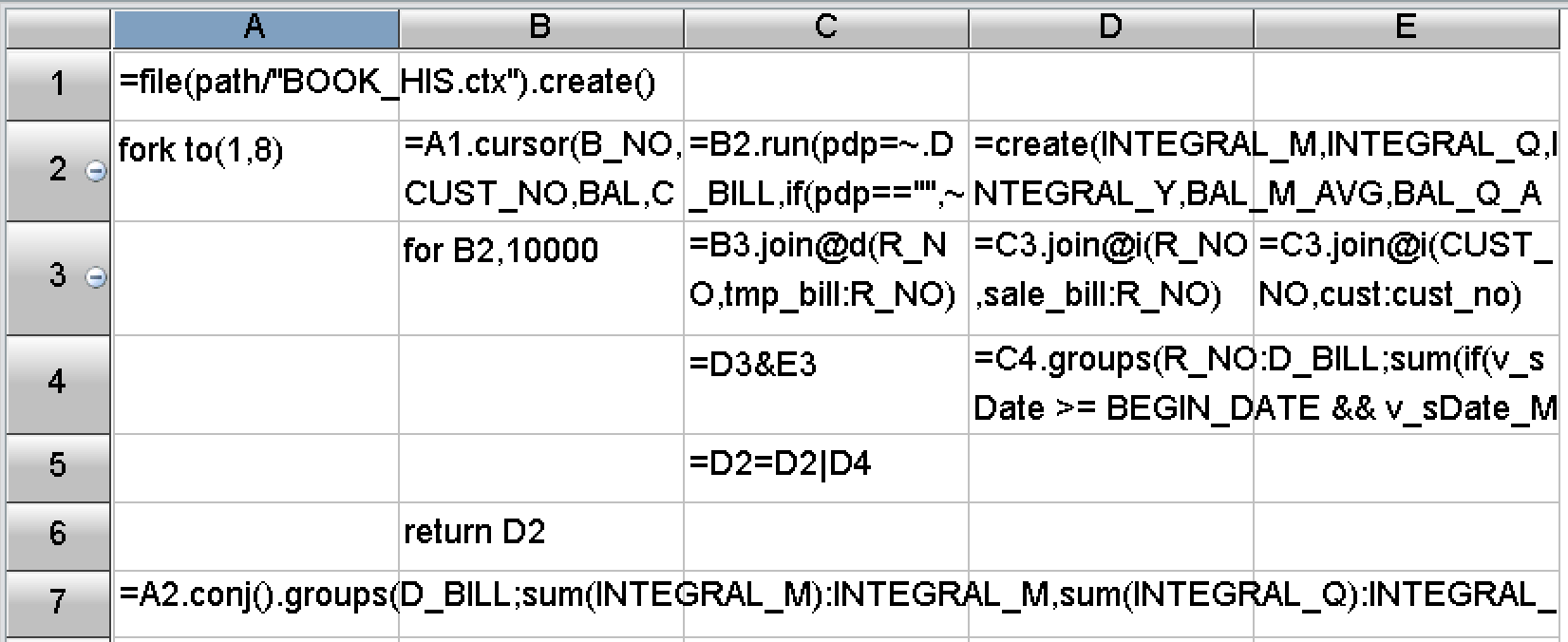
SPL calculation code corresponding to the above steps 7 and 8 is shown as below:
Postscript
To solve the performance optimization problem, the most important thing is to design a high-performance computing scheme to effectively reduce the computational complexity, thereby ultimately increasing the speed. Therefore, we should not only fully understand the characteristics of calculation and data, but also have an intimate knowledge of common high-performance algorithms, only in this way can we design a reasonable optimization scheme according to local conditions. The basic high-performance algorithms used herein can all be found at: , where you can find what you are interested in.
Unfortunately, the current mainstream big data systems in the industry are still based on relational databases. Whether it is the traditional MPP or HADOOP system, or some new technologies, they are all trying to make the programming interface closer to SQL. Being compatible with SQL does make it easier for users to get started. However, SQL, subject to theoretical limitations, cannot implement most high-performance algorithms, and can only face helplessly without any way to improve as hardware resources are wasted. Therefore, SQL should not be the future of big data computing.
After the optimization scheme is obtained, we also need to use a good programming language to efficiently implement the algorithms. Although the common high-level programming languages can implement most optimization algorithms, the code is too long and the development efficiency is too low, which will seriously affect the maintainability of the program. In this case, the open-source SPL is a good choice, because it provides enough basic algorithms, and its code is very concise, in addition, SPL also provides a friendly visual debugging mechanism, which can effectively improve development efficiency and reduce maintenance cost.
SPL Official Website 👉 https://www.scudata.com
SPL Feedback and Help 👉 https://www.reddit.com/r/esProcSPL
SPL Learning Material 👉 https://c.scudata.com
SPL Source Code and Package 👉 https://github.com/SPLWare/esProc
Discord 👉 https://discord.gg/cFTcUNs7
Youtube 👉 https://www.youtube.com/@esProc_SPL


Chinese version