

Python vs. SPL 8 -- Ordered Grouping
We are naturally interested in order-related operations, and grouping operations may also involve the order. This article will compare the calculation abilities of Python and SPL in ordered grouping.
Grouping by positions
It is possible that the position information of members participates in the grouping and the grouping keys are related to positions (or sequence numbers) of the members. For example:
Here are the data:
time a b
0 0.5 -2.0
1 0.5 -2.0
2 0.1 -1.0
3 0.1 -1.0
4 0.1 -1.0
5 0.5 -1.0
6 0.5 -1.0
7 0.5 -3.0
8 0.5 -1.0
It is expected that every three rows are grouped together and the mode number is taken as the result of that group. And the expected result is as follows:
time a b
2 0.5 -2.0
5 0.1 -1.0
8 0.5 -1.0
Python
import pandas as pd file1="D:/data/position.txt" data1=pd.read_csv(file1,sep="\t") pos_seq=[i//3 for i in range(len(data1))] res1=data1.groupby(pos_seq).agg(lambda x:x.mode().iloc[-1]) print(res1) |
Derive a column according to positions, and group by the integer quotient divided by 3 Group and aggregate according to the derived column
|
In order to group every three rows, we can divide the sequence number by 3 and take the integer quotient to get the grouping key, by which the grouping operation is performed. To get the mode number of each group, we can use the agg+lambda expression, which is actually an aggregation operation.
SPL
A |
B |
|
1 |
D:\data\position.txt |
|
2 |
=file(A1).import@t() |
|
3 |
=A2.group((#-1)\3).new(~.max(time):time,~.mode(a):a,~.mode(b):b) |
/group and aggregate |
In SPL, we can get the grouping key with “#” rather than calculating an extra column of grouping keys separately. Here the grouping key is an integer and can be calculated using the group@n() function in SPL. This function is an efficient grouping method for natural numbers, which can directly obtain the correct grouped subsets with sequence numbers rather than performing the comparison operation, so it calculates much faster. Here we can change the code slightly as:
A3=A2.group@n((#+2)\3)...
Grouping when values change
Sometimes the data are ordered originally, we want to group only the adjacent records with the same value together during grouping, for example:
Here are the data:
duration location user
0 10 house A
1 5 house A
2 5 gym A
3 4 gym B
4 10 shop B
5 4 gym B
6 6 gym B
It is expected to get the sum of “duration” when “user” and “location” are the same consecutively and to get the sum again when the values of “location” are changed. And the expected result is:
duration location user
15 house A
5 gym A
4 gym B
10 shop B
10 gym B
Python
file2="D:/data/value.txt" data2=pd.read_csv(file2,sep="\t") value_seq=(data2.location!=data2.location.shift()).cumsum() res2=data2.groupby(['user','location',value_seq], as_index=False, sort=False)['duration'].sum() print(res2) |
The derived column, the values of the column are the same if the adjacent “location” values are the same; otherwise +1 Group and aggregate according to [user, location, derived column]
|
Python cannot group the adjacent members with the same value, but has to derive a column and take it as part grouping keys to complete the grouping operation. However, it takes great effort for us to come up with a relatively simple derived column.
SPL
A |
B |
|
… |
… |
|
4 |
D:\data\value.txt |
|
5 |
=file(A5).import@t() |
|
6 |
=A6.groups@o(user,location;sum(duration)) |
/group with changed values |
The groups@o() function in SPL scans the whole sequence in turn and adds the member to the current grouped subset if the grouping key value is the same as the grouping key of the last member; or generates a new grouped subset and adds the current member to it if the grouping values are not the same. Then after scanning, a batch of grouped subsets are obtained, thus the grouping operation is finally completed. This method in SPL does not need us to derive a new column and the syntax of it is also quite easy with only an additional @o option to the groups function. Such grouping operation only compares the adjacent values, so it executes faster, and this is exactly what the groupby function in Python cannot achieve.
Grouping when conditions change
There is another situation for the originally ordered data, that is, grouping the data when the conditions are changed. For example:
Here are the data:
ID code
333_c_132 x
333_c_132 n06
333_c_132 n36
333_c_132 n60
333_c_132 n72
333_c_132 n84
333_c_132 n96
333_c_132 n108
333_c_132 n120
999_c_133 x
999_c_133 n06
999_c_133 n12
999_c_133 n24
998_c_134 x
998_c_134 n06
998_c_134 n12
998_c_134 n18
998_c_134 n36
997_c_135 x
997_c_135 n06
997_c_135 n12
997_c_135 n24
997_c_135 n36
996_c_136 x
996_c_136 n06
996_c_136 n12
996_c_136 n18
996_c_136 n24
996_c_136 n36
995_c_137 x
It is expected to retrieve one row out of every two “x”es in code column randomly, and the expected result is:
333_c_132 n06
999_c_133 n12
998_c_134 n18
997_c_135 n36
996_c_136 n18
Python
file3="D:/data/condition.txt" data3=pd.read_csv(file3,sep="\t") cond_seq=data3.code.eq('x').cumsum() res3=data3[data3.code.ne('x')].groupby(cond_seq).apply(lambda x:x.sample(1)).reset_index(level=0,drop=True) print(res3) |
The derived column Group according to the derived column and then sample
|
The logic of this operation in Python stays the same with the previous two examples, i.e., deriving a column of grouping keys on our own arduously and grouping according to that column. Also, Python provides the sample() function for sampling the data, making the sampling more effective.
SPL
A |
B |
|
… |
… |
|
9 |
D:\data\condition.txt |
|
10 |
=file(A9).import@t() |
|
11 |
=A10.group@i(code=="x").conj((l=~.len(),if(l<2,,~.m(2:)(rand(l-1)+1)))) |
/group with changed conditions |
The grouping key of the group@i() function in SPL is an expression, which generates a new grouped subset if the return result is true, that is, a new group will be generated when a certain condition is satisfied. This method also does not need to think of a derived column arduously and the calculation efficiency is excellent. But the sampling function is not provided in SPL, we have to write the sampling action manually, which can be easily completed using the rand() function in SPL.
In addition, @o and @i options are valid for both groups and group functions with the same effects.
As for processing logs, these three order-related grouping operations introduced in the article all work very well.
1. The log with fixed number of lines
The form of the log is:
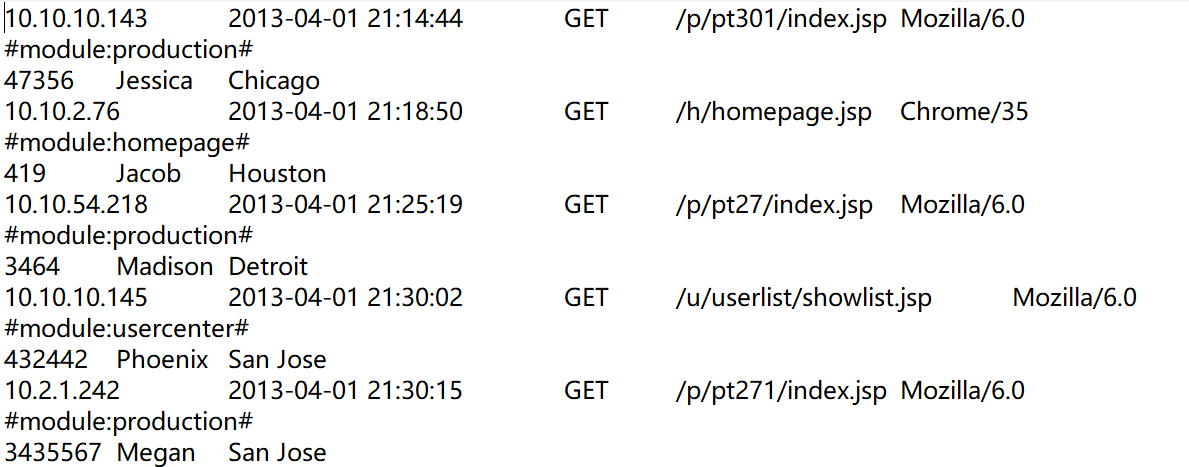
IP, TIME, GET, URL, and BROWER are in the first line;
MODULE is in the seconds line;
USERID, UNAME, and LOCATION are in the third line.
In this case, use group((#-1)\3) and then process the log of each group.
2. The log with unfixed number of lines but each line has a mark
The form of such kind of log is as follows:

The number of lines of each user is different but each line is started with the ID of users.
In this case, use group@o(~.split(“\t”)(1)) and then process the log of each group.
3. The log with unfixed number of lines but there is a starting mark
The form of the log is:
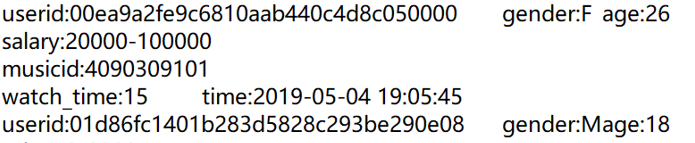
The number of lines of each user is different but each user has a staring mark “userid”.
In this case, use group@i(~.split(“:”)(1)==”userid”), and then process the log of each group.
Summary
Python is not able to use the ordered data to improve efficiency because it adopts the same method for ordered grouping and unordered grouping. It is always necessary to derive a column and make it satisfy the grouping conditions, wasting a lot of useful information.
While SPL can make full use of the ordered data to make the grouping operation even faster. As long as the grouping conditions are well written, we don’t have to derive a column by ourselves, and @n, @o or @i options can be added to change the form of functions, which is very easy and practical.
SPL Official Website 👉 http://www.scudata.com
SPL Feedback and Help 👉 https://www.reddit.com/r/esProc
SPL Learning Material 👉 http://c.scudata.com
SPL Source Code and Package 👉 https://github.com/SPLWare/esProc
Discord 👉 https://discord.gg/ydhVnFH9
Youtube 👉 https://www.youtube.com/@esProc_SPL


Chinese version