

Is There a Database Technique That Enables Fast JOIN?
JOIN is a long-standing challenge in optimizing database performance. The more large tables in a JOIN operation, the worse the performance.
The key of JOIN optimization is to properly classify the operations so that we can design and choose the right optimization method according to the characteristics of each category. SQL defines JOINs in one single way that is too general and simple to leave little room for performance optimization. This is why it is hard to speed up JOIN operations in relational databases.
The open-source esProc SPL categorizes JOINs into more types and designs specific high-performance algorithms for each type of operation, in an effort to increase computational speed. An SPL programmer will choose the most suitable algorithm according to the current computing scenario to achieve a fast JOIN operation.
A common foreign key association creates a relationship between tables by associating a non-primary-key field in one table with the other table’s primary key. We simply call the former the fact table and the latter dimension table. There are examples like associating Orders table’s CustomerID field with Customer table, its ProductID field with Product table, and its VendorID field with Vendor table.
Usually, a fact table like Orders will grow larger and larger over time while the dimension table remains relatively small. SPL offers a special technique – foreign key numberizing – to handle such type of JOIN operations. The technique, in advance, converts values of a dimension field in the fact table into sequence numbers of corresponding records of the in-memory dimension table. Then at computation, we can directly get records of the in-memory table using the above-mentioned dimension field values (that is, sequence numbers of records in the dimension table) after the fact table is fetched into the memory in batches.
According to tests using the same data size and under the same environment, SPL runs 3 to 8 times faster than Oracle in handling the join operation between a large fact table and a small dimension table:
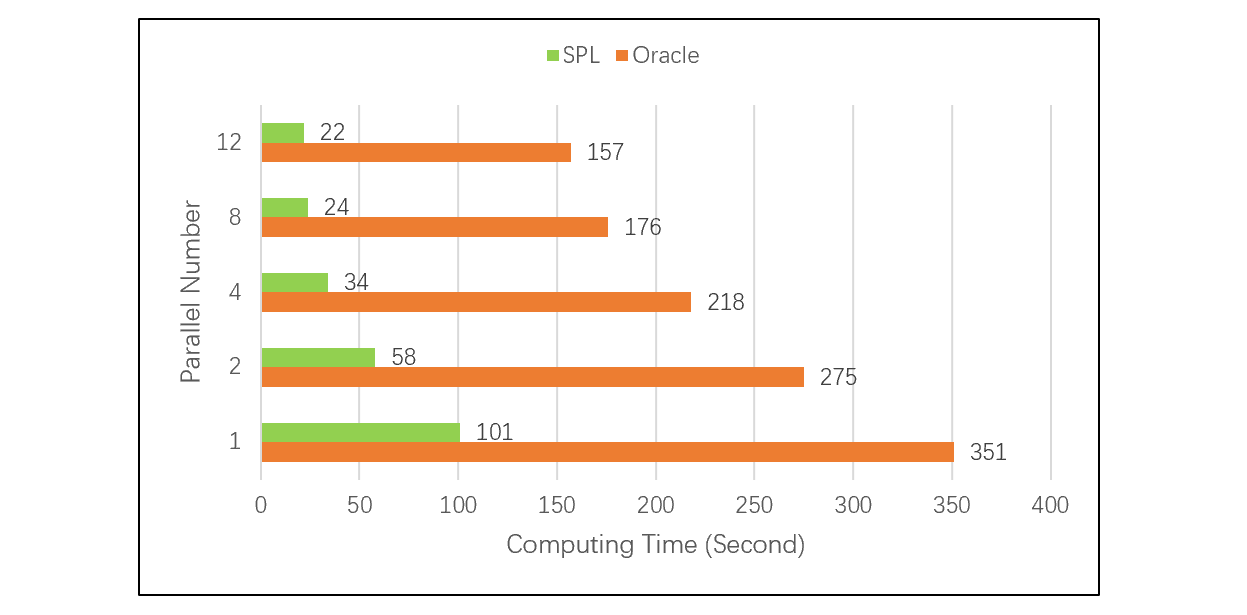
SPL is faster because the foreign key numberizing technique does not compute and compare HASH values as relational databases do. It speeds up the process of association with the dimension table and effectively enhances performance.
Though it takes certain time and resource to transform the fact table’s foreign key field to sequence numbers of records in the dimension table beforehand, the pre-computation result can be reused repeatedly for foreign key associations.
Learn more about the technique in Performance Optimization Skill: Numberizing Foreign Key.
For scenarios where both the fact table and the dimension table are large, SPL has the one-sided partitioning technique to enable faster JOIN operations than relational databases (Learn details about the technique in One-side partitioning algorithm of SPL). Take the result (Unit: second) of a test of such a JOIN in Performance Optimization Skill: Associating Big Fact Table and Big Dimension Table as an example:
Number of records in fact table |
1 billion |
1.2 billion |
1.4 billion |
1.5 billion |
1.6 billion |
Oracle |
730 |
802 |
860 |
894 |
>10 hours |
SPL |
486 |
562 |
643 |
681 |
730 |
When data can be wholly loaded to the memory, the speed of Oracle increases in direct proportion to the size of data. When data cannot fit into the memory, swap space will be heavily used and computation become particularly slow. During our test, the query didn’t finish after 11 hours’ execution and had to be terminated. SPL’s one-sided partitioning technique caters to external memory and is not restricted by data sizes. It involves only one heaping action and the computing time increases linearly with increase in data size.
The other two common types of JOINs involve association between two tables’ primary keys (or between one primary key and a field of the other composite primary key). Examples include the association between the Orders table and the OrderDetail table through OrderID and between the Customer table and the VIPCustomer table through their primary keys. For these JOIN operations, SPL’s optimization method is to first sort the two large tables by primary keys and join them using the ordered merge algorithm.
The ordered merge algorithm traverses two tables in sequence without turning to the external buffering, greatly reducing the IO costs. It has a linear degree of complexity, which is much lower than the HASH JOIN of quadratic complexity degree, and thus boasts significantly higher performance.
Under the same environment, SPL is nearly 3 times faster than Oracle in handling OrderID field -based association between two large tables, the Orders table and the OrderDetail table, according to our test (Details can be found in Performance Optimization Skill: Ordered MERGE):
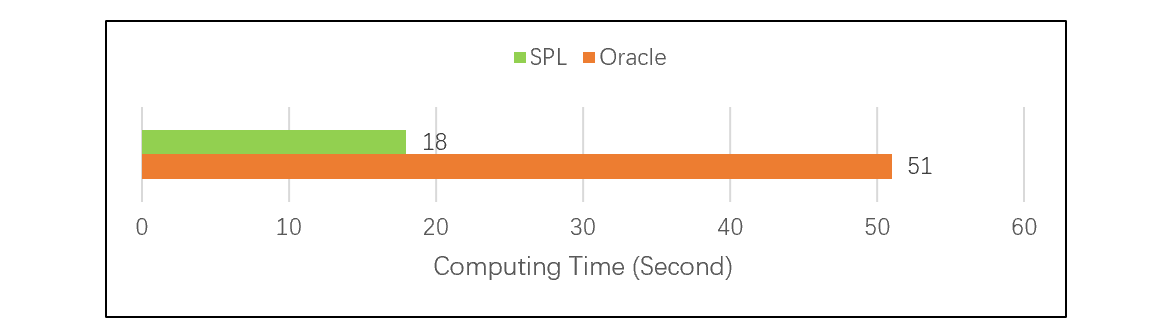
This type of JOINs is only based on primary keys (or a primary key and a certain field of the other key) of two tables, and does not involve any other fields. The pre-sorting operation by primary keys is a little time-consuming, but it is a one-off and data will only be thus stored without redundancy.
SPL Official Website 👉 http://www.scudata.com
SPL Feedback and Help 👉 https://www.reddit.com/r/esProc
SPL Learning Material 👉 http://c.scudata.com
SPL Source Code and Package 👉 https://github.com/SPLWare/esProc
Discord 👉 https://discord.gg/ydhVnFH9
Youtube 👉 https://www.youtube.com/@esProc_SPL


Chinese version