

SPL: Access Cassandra
Cassandra is a distributed NoSQL database. In JAVA, DataStax can be used to execute the CQL of Cassandra. This language can maintain and access data in a simple way, but does not support operations such as association, grouping and aggregation, etc., which shows a much worse computational ability than SQL of relational database. Another constraint on the computational ability of CQL is that this language needs to support more complex data models, where field values may be nested sets such as Set, Map, etc. SPL, the computational engine language, supports calculations on the complex data models very well, and provides several functions to connect Cassandra, which can compensate for the weaker computational ability of Cassandra database by importing the data.
Create/close Cassandra connection
Similar to the JDBC connection of relational database, SPL also connects Cassandra with paired "create/close".
stax_open(server[:port][,keyspace][,user:pwd][,compressor][,version:verX][,queryOptions:optionX]), server is the address of server, after which there are port, key space, user name, password, compression algorithm, version number of protocol, and query option, which can be omitted if not needed.
stax_close(staxConn), staxConn is the connection to be closed.
Code sample: A1 creates the connection, and A3 closes the connection after some other data assessing and calculating operations in the middle steps.
A |
|
1 |
=stax_open("127.0.0.1":9042) |
2 |
…… |
3 |
=stax_close(A1) |
Execute CQL
stax_execute(staxConn, cql, [arg1], [arg2], ...), staxConn is the Cassandra connection, and cql is the statement to be executed, in which multiple parameters are allowed. We can use "?" as placeholders for parameters to be given, and arg1, arg2, etc. are the values of parameters, so we have to provide corresponding number of parameter values as the number of "?".
Code sample:
A |
|
1 |
=stax_open("127.0.0.1":9042) |
2 |
=stax_execute(A1,"CREATE KEYSPACE splSpace WITH replication = {'class':'SimpleStrategy','replication_factor': 3}") |
3 |
=stax_execute(A1,"USE splSpace") |
4 |
CREATE TABLE emp( emp_id int PRIMARY KEY, emp_name text, emp_city text, emp_sal int, emp_phone text ) |
5 |
=stax_execute(A1,A4) |
6 |
=stax_execute(A1, "select * from emp") |
7 |
INSERT INTO emp(emp_id, emp_name, emp_city,emp_sal, emp_phone) VALUES(4,'robin', 'Hyderabad',?,?); |
8 |
=stax_execute(A1, A7, 234, "984-8022-339") |
9 |
=stax_execute(A1, "select * from emp") |
10 |
=stax_cursor(A1, "select * from emp") |
11 |
=A10.fetch(10) |
12 |
CREATE TABLE users ( id text PRIMARY KEY, name text, favs map<text, text> ) |
13 |
=stax_execute(A1,A12) |
14 |
INSERT INTO users (id, name, favs) VALUES ('jsmith', 'John Smith', { 'fruit' : 'Apple', 'band' : 'Beatles'}) |
15 |
=stax_execute(A1,A13) |
16 |
=stax_execute(A1, "select * from users") |
17 |
=stax_close(A1) |
A key space named “splSpace” is created in A2.
A3 uses this key space, and all subsequent operations are performed in this key space;
A4 is a CQL for table definition, and A5 executes the CQL in A4 to create the table; A6 queries the table. After the above operations, although there is no data yet, the table structure can be seen already:

A7 is a statement for inserting data in emp table, and the last two values are given as parameters; A8 executes the statement in A7, where the given parameter values are 234 and 984-8022-339. After executing, A9 queries the emp table again, then the data can be seen as:

A10 is a new function, stax_cursor(), which shares the same syntax of stax_execute(). Instead of returning result data immediately, it returns a cursor and fetches batches of data as needed, for example, A11 fetches the data of first 10 rows. The stax_cursor() function is suitable for big data.
The favs field of users table defined in A12 is of map type; A13 executes to create CQL; A15 inserts a row of data; A16 queries the users table. The result shown in SPL is the following nested table sequence:
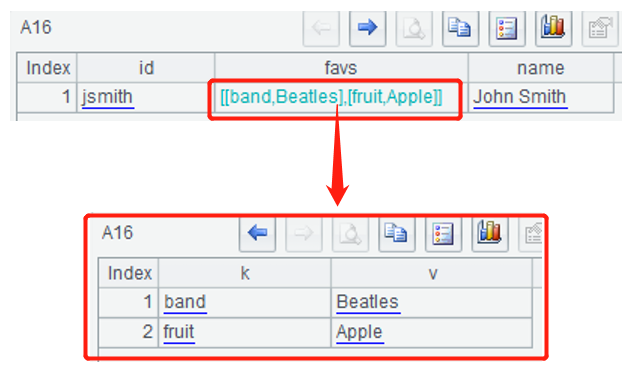
As for such nested data of multiple layers, it is much easier to do the subsequent transpositions and calculations by importing them in SPL.
SPL Official Website 👉 http://www.scudata.com
SPL Feedback and Help 👉 https://www.reddit.com/r/esProc
SPL Learning Material 👉 http://c.scudata.com
SPL Source Code and Package 👉 https://github.com/SPLWare/esProc
Discord 👉 https://discord.gg/ydhVnFH9
Youtube 👉 https://www.youtube.com/@esProc_SPL


Chinese version