

How to cope with high-concurrency account query?
There are many application scenarios for high-concurrency account query, such as: query the transaction records via a mobile banking app, query the shopping orders in an e-commerce system, and query the recharge records of mobile game account, etc. These scenarios generally involve many accounts, and the total amount of data is very large, and hence the data needs to be stored in external storage. Usually, the amount of data in each account is not large (from a few pieces to several thousand pieces), and the query of the data of one account is a simple task, and almost no extra operation. However, when the number of accounts is huge, the queries in large number and high frequency will naturally occur, resulting in a highly concurrent access. In this case, it is a big challenge to achieve a response speed in seconds or even faster.
In the SQL database or data warehouse, using the index to search for the data of one account is fast and you hardly feel the time consumption, but when many queries are made concurrently, you will feel an obvious delay. The reason is that the relational database based on the unordered set cannot guarantee the order of data when they are stored, and hence it cannot guarantee that the data of the same account are continuously stored physically. Consequently, when searching for the data of one account, it may need to read from many positions on the hard disk before all data are taken out. Moreover, since the reading of hard disk requires a minimum unit, a lot of irrelevant content will be loaded when reading discontinuous data, which will slow down the query speed. Although the data amount of one account is small, and querying one account will only slow down the query speed slightly, the accumulated slowing-down will substantially affect the overall performance in the case of high-concurrency access scenarios.
Because the performance of relational databases is not satisfactory, the search engine Elastic Search is often used to cope with the said scenarios, that is, export data to ES first, and then use the search technology to achieve high-performance concurrent queries. After using ES, the expected performance requirements can indeed be met in general, but unfortunately, ES does not support JOIN very well, and if the association calculation is involved in the query process, it will cause great trouble. For example, when there is a need to associate the account transaction detail table with the user table, product table, store table, etc., if the ES is used to perform association, it has to integrate all the data into the detail table to form a big wide table, but this method has the following disadvantages: i)the process of preparing such big wide table is not only time-consuming and laborious, but greatly loses the flexibility; ii) importing data into ES is very slow, which will further exacerbate this problem; iii) when the big wide table is used, you cannot simply write the changed data in the way of appending when the associated data changes, and instead, you have to re-prepare a new wide table and import all data again, which takes a long time, and the query service has to be suspended during this process. Therefore, solving the high-concurrency account query with ES can only be regarded as a stopgap measure.
In fact, this problem is not difficult to solve. The key of solving it is to sort the data by the accounts to ensure that the data of the same account are continuously stored physically. In this way, the data blocks read from hard disk during query are almost the target values, and thus the performance will be greatly improved. Unfortunately, it is difficult for the relational database to use this method, for it does not guarantee the physical order of data storage.
The open-source data computing engine SPL supports the ordered storage, which can ensure that the data are stored by the accounts physically and orderly. During high-concurrency search, the index of SPL can quickly and accurately locate the storage position of specified account in external storage; the ordered storage technology can ensure that the data of the same account are physically stored in a continuous area without the need to read data in a jump way. The combination of the two features can make the high-concurrency account query achieve extreme performance.
In addition, for the high-concurrency query scenarios, the row-based storage should be selected instead of the columnar storage scheme trumpeted in many data warehouses, for the reason that the data in each field of one record are physically stored continuously in the case of row-based storage, only in this way can all data of the same account be stored in one place. For the columnar storage, however, since the data of each column are stored continuously, and the fields of one account are scattered in different columns, it will still cause the hard disk to read discontinuous data. Especially when the concurrent query occurs, the discontinuous access to the hard disk caused by columnar storage is much more serious than that caused by row-based storage.
In fact, the row-based storage is more suitable for searching, while the columnar storage is more suitable for traversal. SPL supports both storage methods, and programmers are free to choose according to their computing needs. It’s a pity that some data warehouses adopt the transparent mechanism that does not allow users to have their own choice on using the two storage methods, so it is difficult to achieve a best result.
Moreover, the SPL code for ordered row-based storage and index is very simple. For example, the following code is to dump the data from the database and generate the orderly row-based storage account transaction table and index:
A |
B |
|
1 |
=connect("db").cursor@d("select * from detail order by id) |
|
2 |
=file("detail.ctx").create@r(#id,ddate,amt,…) |
=A3.append@i(A2) |
3 |
=A3.index(index_id;id) |
>A3.close() |
A1 connects to the database and prepares to fetch data; A2 creates the transaction detail table, and @r represents the row-based storage; B2 appends data to the detail table; A3 creates an index for the detail table.
Then we can use the generated detail table and index to query quickly:
A |
|
… |
|
4 |
=file("detail.ctx").open().index@3(index_id) |
5 |
=A4.icursor (id,ddate,amt;id==1101004 && …,index_id).fetch() |
A4 loads the index of detail table, and A5 uses the orderly row-based storage table and index to achieve query.
On this basis, it is also very easy for SPL to implement JOIN operations such as multiple-foreign-key association and multiple-layer association. For example, when querying the transaction detail table, there is a need to associate the store table (store), and include the store name in the query result. SPL code:
A |
|
… |
|
4 |
=file("detail.ctx").open().index@3(index_id) |
5 |
=A4.icursor (id,ddate,amt,sid;id==1101004 && …,index_id).fetch() |
6 |
=file("store.btx").import@b(id,name,...).keys(id) |
7 |
=A5.switch(sid,A6) |
8 |
=A7.new(id,sid.name:sname,amt,ddate) |
A6, A7, A8 load the store table to perform the in-memory association, and generate the query result (including the store name).
Since the amount of data in each account is not large, the operations in A7 and A8 are performed in the memory and take little time.
SPL also supports the fast appending of new data, please visit: for details.
An actual test indicates that, in a scenario with 200 million pieces of total data amount and concurrent queries by 500 users, the query performance of SPL’s orderly row-based storage and index exceeds that of ES. Test result:
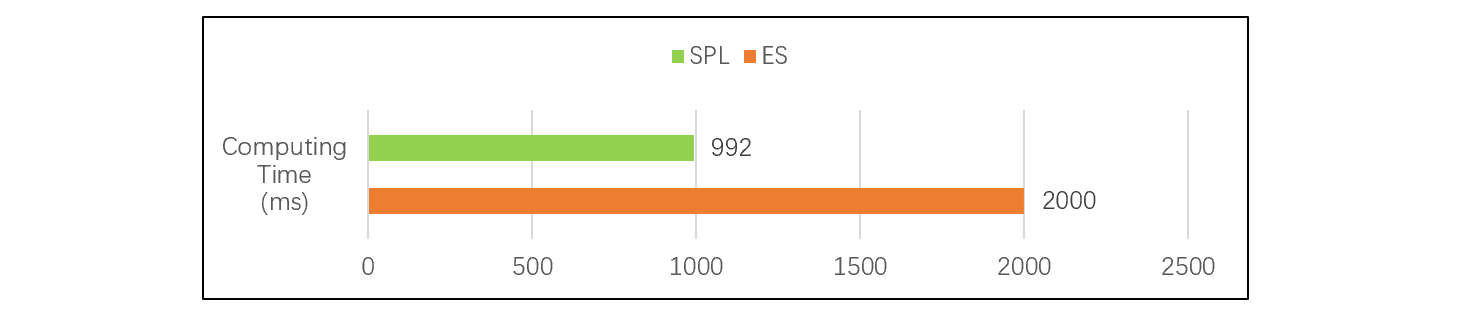
This figure shows that the performance of SPL is comparable to or even slightly faster than ES. However, SPL supports JOIN much better, and there is no complex loading problem. In contrast, SPL is more suitable for high-concurrency account query scenarios than ES.
It should also be noted that high-concurrency account queries belong to search calculation, but sometimes the system also needs to take into account the performance of traversal calculation. For example, for the account transaction data in February, there may be a need to count the total transaction amount and total number of transactions by product group. To meet this requirement, SPL provides the index-with-values mechanism, which supports the high-performance traversal and search calculations at the same time. If you are interested in this mechanism, visit: 《SQL Performance Enhancement: Queries on Highly Concurrent Accounts》.
SPL Official Website 👉 http://www.scudata.com
SPL Feedback and Help 👉 https://www.reddit.com/r/esProc
SPL Learning Material 👉 http://c.scudata.com
SPL Source Code and Package 👉 https://github.com/SPLWare/esProc
Discord 👉 https://discord.gg/ydhVnFH9
Youtube 👉 https://www.youtube.com/@esProc_SPL


Chinese version