

The performance problems of data warehouse and solutions
As the volume of data continues to grow and the complexity of business rises gradually, we are facing a big challenge in data processing efficiency. The most typical manifestation is that the performance problem of data warehouse is becoming more and more prominent when dealing with an analytical task, and some problems occur from time to time such as high computing pressure, low performance, long query time or even unable to find out result, production accident caused by failure to accomplish a batch job on time. When a data warehouse has performance problem, it doesn't serve the business well.
Solutions for performance problem of traditional data warehouse
Let’s start with the most common solution - cluster, that is, use the distributed technology and rely on expanding hardware to improve performance. It is certain that splitting a large task to every node of a cluster to let the nodes compute simultaneously can achieve better performance than performing this task on a single node. Even if we don't do distributed computing, but simply share a concurrent task, we can also reduce the computing pressure of a single node. The idea of cluster to solve performance problem is simple and rough. As long as the data warehouse supports cluster and the task can be split, the performance problem can be solved just through adding hardware resources. Although this solution may not achieve a linear performance improvement, it will basically work.
The disadvantage of cluster is high cost. In the current era of big data, we inevitably mention the cluster whenever performance improvement is involved, and often ignore whether the performance of a single node is brought into full play, as we think that the method of adding hardware resources is OK as long as the cluster is supported. Therefore, the cluster is likely to be a “panacea” in the eyes of many people. However, we should note that the cluster needs more hardware resources, the cost will naturally be high, and the operation and maintenance of cluster also need to invest more. In addition, some complex multi-step computing tasks cannot utilize cluster at all since they can’t be split. For example, most of the multi-step batch jobs involving large data volume can only be performed with a single node (single database stored procedure). Although cluster is a good solution, it is not a panacea. Even if we have enough money to build a cluster, we cannot solve all performance problems.
For some time-consuming query tasks, we can adopt the pre-calculation solution, that is, use the method of trading space for time to process the data to be queried in advance. In this way, the computing complexity can be reduced to O (1), and the efficiency can be greatly improved. Likewise, this solution can solve many performance problems. Pre-aggregating the data to be calculated and processing them in advance can trade space for time, which is particularly effective for multidimensional analysis scenarios.
However, the disadvantage of the solution is extremely poor in flexibility. For example, in the multi-dimensional analysis, although it is theoretically possible to pre-calculate all dimension combinations (this will satisfy all query requirements), we will find it unrealistic in practice because it requires a huge storage space to perform pre-calculation, so we have to do partial pre-calculation after sorting out business, which greatly limits the query scope and reduces the flexibility.
In fact, even if the full pre-calculation is performed, it still can’t tackle some situations, such as unconventional aggregation (e.g., calculating median and variance), combining aggregations (e.g., calculating average monthly sales), conditional metric (e.g., calculating the total sales of orders with transaction amount greater than 100 dollars), time period aggregation (aggregating within a freely chosen time period). The query requirements in real world are diverse and highly flexible, pre-aggregation can only solve a part or even a small part of the requirements. To meet diverse on-line query requirements in a wider range and more efficiently , more effective computing means is required.
A more effective solution is the optimization engine, which can make the data warehouse run faster under the same hardware resource. This solution has become the focus of many vendors, they provide a lot of engineering means that are already well known in the industry, such as columnar storage, vectorized execution, coding compression and memory utilization (cluster can also be regarded as an engineering means). With these means, the computing performance can be improved by several times, provided that the amount of data is within a certain range, and they can fully meet the computing requirements of some scenarios. Unfortunately, these engineering means cannot change the computing complexity, and the improved performance still often fails to meet the computing requirements in scenarios where the data amount is large, or the complexity is particularly high.
The more effective means of optimization engine is to improve the performance at algorithm level (improving at complexity level). A good data warehouse optimization engine can guess the real intention of a query statement, and adopt a more efficient algorithm to execute the statement (instead of executing it according to the literally expressed logic). Algorithm-level improvements usually make it possible to achieve a higher performance. Currently, most data warehouses still use SQL as their main query language, and SQL-based optimization has been done well enough. However, due to the limitations of SQL description ability, very circuitous ways have to be adopted for complex query tasks. Once the complexity of SQL statement increases, it will be difficult for optimization engine to play its role (it can't guess the real intention of the statements, and has to execute according to literally expressed logic instead, resulting in a failure to improve the performance). In short, the optimization engine works only for simply query tasks.
Let's take an example, the following code is to calculate TopN:
SELECT TOP 10 x FROM T ORDER BY x DESC
Most data warehouses will optimize the task instead of doing a real sorting. However, if we want to query the in-group TopN:
select * from
(select y,*,row_number() over (partition by y order by x desc) rn from T)
where rn<=10
As we can see, although the complexity of this calculation is not much higher than that of the previous one, the optimization engine will get confused and can't guess its real intention, and hence it has to do a big sorting according to the literally expressed meaning, resulting in low performance. Therefore, in some scenarios, we will process the data into a wide table in advance, so that we can simplify the query and give the optimization engine into play. While it is costly, we have to do that sometimes in order to effectively utilize optimization engine.
Currently, almost all data warehouse vendors are competing for SQL ability. For example, they are competing to provide more comprehensive SQL support, offer stronger optimization ability, and support larger cluster, and so on. Although these actions can “please” the wide range of SQL users to the greatest extent, the aforementioned means are often less effective in the face of complex computing scenarios, and performance problem still exists. No matter how hard they work on SQL (engineering optimization), the effect is not satisfactory, nor does it fundamentally solve performance problem. Such type of performance problem is common in practice, here are a few examples.
Complicated ordered computing: When analyzing the user behavior through conversion funnel, it involves multiple events, such as page browsing, searching, adding to cart, placing order and paying. To count the user churn rate after each event, we need to follow a principle that these events are completed within a specified time window, and occur in a specified order, only in this way can we get an effective result. If this task is implemented in SQL, it will be very difficult, and has to implement with the help of multiple sub-queries (as many as the number of events) and repeated associations. As a result, the SQL statement will be very complex, and some data warehouses cannot even execute such complex statement, and even if they can, the performance is very low and it's more difficult to optimize.
Multi-step batch job involving large data volume. For complex batch job, SQL also doesn’t work well. In the stored procedure, SQL often needs to use the cursor to read data step by step. Since the cursor is very low in performance and unable to compute in parallel, it eventually leads to high resource consumption and low computing performance. Moreover, dozens of operation steps in stored procedure need thousands of lines of code, and it needs to repeatedly buffer the intermediate results during computing, this further decreases the performance, resulting in a phenomenon that a batch job cannot be accomplished on time occurs from time to time at the end of month/year when there are a large amount of data and many tasks.
Multi-index calculation on big data. Many industries need to calculate index. For example, in the loan business of bank, there are not only multiple tiers of classification dimensions and multiple guarantee types, but also many other dimensions such as customer type, lending way, currency type, branch, date, customer age range and education background. If we combine them freely, an extremely huge number of indexes will be derived. Aggregating these indexes needs to be done based on a large amount of detailed data, and the calculation will involve many types of mixed operations such as large table association, conditional filtering, grouping and aggregation, and de-duplication and counting. Such calculations feature flexible, large in data volume and complex, and are accompanied with high concurrency, which make it very hard to implement in SQL. If we adopt the pre-calculation solution, it is inflexible, while the real-time calculation is too slow.
Since these problems are difficult to be solved in SQL, extending the computing ability of SQL becomes the fourth solution following the cluster, pre-calculation and optimization engine. Nowadays, many data warehouses support using the user-defined function (UDF) to extend the ability, and allow users to write UDF to meet their own needs according to actual requirements. However, UDF is difficult to develop and requires users to have high technical skill. More importantly, UDF still cannot solve the computing performance problem of data warehouse because it is still limited by the storage of database, resulting in the inability to design more efficient data storage (organization) form according to computing characteristics. As a result, many high-performance algorithms cannot be implemented, and hence it naturally cannot achieve high performance.
Therefore, to solve these problems, we should adopt a non-SQL-based solution, and let programmers control the execution logic outside the database, so as to better utilize low-complexity algorithms and make full use of engineering means.
As we analyzed, some big data computing engines such as Spark emerged. Spark provides a distributed computing framework, and is still intended to meet the needs of computing ability through a large-scale cluster. Since the design based on all-in-memory operation is not friendly enough to the calculation on external storage, and RDD adopts the immutable mechanism, RDD will be copied after each calculation step, resulting in occupying and wasting a large amount of memory space and CPU resource and a very low performance, and the engineering means are not fully utilized. In addition, Spark is not rich in computing library, lacks high-performance algorithms, making it difficult to achieve the goal of “low-complexity algorithm”. Furthermore, Scala is very difficult to use, which makes it extremely difficult to code in the face of the complex computing problems mentioned above. Difficult to code and unable to achieve high performance may be one of the reasons why Spark turns to using SQL again.
Since traditional data warehouse doesn't work, and external programming (Spark) is difficult and slow, is there any other alternative?
From the above discussion, it is not difficult to conclude that to solve the performance problem of data warehouse, we do need a computing system independent of SQL (like Spark) but, this system should have the characteristics of easy in coding and fast in running. Specifically, this system should not be as complex as Spark when describing complicated computing logic, and should even be simpler than SQL; this system should not rely solely on a cluster in terms of computing performance, and should provide rich high-performance algorithms and engineering ability, so as to make full use of hardware resource and maximize the performance of a single node. In short, this system should have not only the ability to quickly describe low-complexity algorithm, but also sufficient engineering means. Moreover, it would be ideal if the system could be deployed, operated and maintained easily.
The esProc SPL solution
esProc SPL is a computing engine specially for processing the structured and semi-structured data, having the same ability with current data warehouses. However, unlike traditional SQL-based data warehouses, esProc doesn’t continue to adopt relational algebra but designs a brand-new computing system, based on which SPL (Structured Process Language) syntax is developed. Compared with SQL, SPL has many advantages. Specifically, it provides more data types and operations, richer computing libraries, and stronger description ability; with the support of procedural computing, it allows us to write algorithms according to natural thinking without having to code in a roundabout way, making SPL code shorter; it has sufficient ability to implement multi-step complex calculations mentioned earlier, which is simpler than SQL and other hard-coding methods.
When it comes to the performance, esProc SPL provides many high-performance algorithms of “lower complexity” to ensure computing performance. We know that software cannot change the performance of hardware, the only way to achieve higher computing performance under the same hardware condition is to design algorithms of lower complexity so as to make computer execute fewer basic operations, which will naturally make the computing speed faster. However, it is not enough to design low-complexity algorithms, the ability to implement them is also required, and the simpler in coding, the better the performance. Therefore, easy in coding and fast in running are the same thing actually.
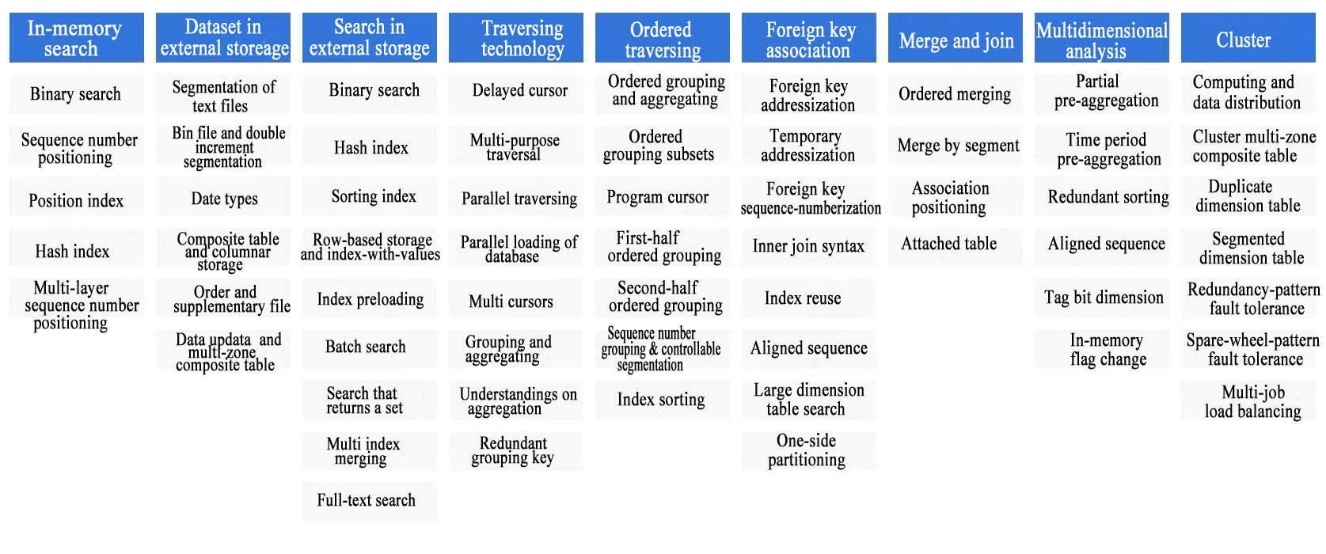
This figure shows part of SPL-provided high-performance algorithms, many of which are the original inventions of SPL.
Of course, a high-performance algorithm cannot do without good data organization (data storage schema). For example, the ordered merge and one-sided partitioning algorithms can be implemented only when data is stored in order. Yet, the storage of database is relatively closed, and cannot be interfered externally, resulting in a failure to design the storage according to calculation characteristics. For this reason, SPL provides its own binary file storage, that is, store the data in a file system outside the database so as to make full use of the advantages of multiple data storage schema such as columnar storage, ordering, compression, and parallel segmentation, and achieve the objective of flexibly organizing the data according to computing characteristics and fully utilizing the effectiveness of high-performance algorithm.
In addition to high-performance algorithms, esProc provides many engineering means to improve computing performance, such as columnar storage, coding compression, large memory and vector-based computing. As mentioned above, although these engineering means cannot change the computing complexity, they can often improve the performance by several times. With these means, along with many low-complexity algorithms built in SPL, a performance improvement of one or two orders of magnitude becomes the norm.
As mentioned above, if we want to achieve high performance based on a non-SQL system, we have to control the execution logic, adopt low-complexity algorithms, and make full use of various engineering means. Unlike SQL, the theory system of SPL brings us a strong description ability, and a simpler coding method without the need to code in a roundabout way, and allows us to use its rich high-performance algorithm libraries and corresponding storage mechanisms directly, thereby achieving the goal of making full use of engineering optimization means while adopting low-complexity algorithm, as well as the effect of simply in coding and fast in running.
For example, the TopN is regarded as an ordinary aggregation operation in SPL. Whether it is to calculate the TopN of full set or grouped subsets, the processing method of SPL is the same, and there is no need to do a big sorting. In this way, the goal of “using lower-complexity algorithm” is achieved, along with high performance.
Again, let's take the above conversion funnel as an example to feel the difference between SQL and SPL.
SQL code:
with e1 as (
select uid,1 as step1,min(etime) as t1
from event
where etime>= to_date('2021-01-10') and etime<to_date('2021-01-25')
and eventtype='eventtype1' and …
group by 1),
e2 as (
select uid,1 as step2,min(e1.t1) as t1,min(e2.etime) as t2
from event as e2
inner join e1 on e2.uid = e1.uid
where e2.etime>= to_date('2021-01-10') and e2.etime<to_date('2021-01-25')
and e2.etime > t1 and e2.etime < t1 + 7
and eventtype='eventtype2' and …
group by 1),
e3 as (
select uid,1 as step3,min(e2.t1) as t1,min(e3.etime) as t3
from event as e3
inner join e2 on e3.uid = e2.uid
where e3.etime>= to_date('2021-01-10') and e3.etime<to_date('2021-01-25')
and e3.etime > t2 and e3.etime < t1 + 7
and eventtype='eventtype3' and …
group by 1)
select
sum(step1) as step1,
sum(step2) as step2,
sum(step3) as step3
from
e1
left join e2 on e1.uid = e2.uid
left join e3 on e2.uid = e3.uid
SPL code:
A |
|
1 |
=["etype1","etype2","etype3"] |
2 |
=file("event.ctx").open() |
3 |
=A2.cursor(id,etime,etype;etime>=date("2021-01-10") && etime<date("2021-01-25") && A1.contain(etype) && …) |
4 |
=A3.group(uid).(~.sort(etime)) |
5 |
=A4.new(~.select@1(etype==A1(1)):first,~:all).select(first) |
6 |
=A5.(A1.(t=if(#==1,t1=first.etime,if(t,all.select@1(etype==A1.~ && etime>t && etime<t1+7).etime, null)))) |
7 |
=A6.groups(;count(~(1)):STEP1,count(~(2)):STEP2,count(~(3)):STEP3) |
As we can see that SPL code is shorter with the support of ordered computing, because SPL allows us to code step by step (procedural computing) according to natural thinking. Moreover, this code can handle a funnel analysis involving any number of steps (3 steps in this example). When the number of steps increases, we only need to modify the parameter. Therefore, SPL is obviously more advantageous than SQL that needs to add one subquery for each additional step, which benefits from the “simple in coding” of SPL.
In terms of performance, SPL still has obvious advantages. This example is actually a simplified real case. In the real case, SQL code has almost up to 200 lines. The user did not get the result after 3 minutes running on Snowflake's Medium server (equivalent to 4*8=32 cores), while the user got the result in less than 10 seconds when executing SPL code on a 12-core and 1.7G low-end server. This benefits from SPL’s high-performance algorithms and corresponding engineering means.
With these mechanisms, esProc SPL can make full use of hardware resources, and maximize the performance of a single node. As a result, not only can esProc SPL solve many original performance problems of a single node effectively, but even many calculations that originally required to be solved with cluster can now be solved with a single node (possibly faster), thereby achieving the computing effect of cluster by only using one node. Of course, a single node is limited in computing ability. In order to cope with this problem, SPL also provides the distributed technology, allowing us to scale out the computing capability through a cluster when a single node cannot meet the computing requirement in any case, which is SPL's high-performance computing philosophy: first improve the performance of a single node to the extreme, and turn to a cluster when the computing ability of one node is insufficient.
For sure, any technology has shortcomings, SPL is not an exception. SQL has been developed for decades, and many databases already have strong optimization engines. For simple operations that are suitable to be implemented in SQL, the optimization engines have the ability to optimize slow statements written by ordinary programmers and achieve better performance. In this sense, the requirements for programmers are relatively low. Certain scenarios, such as multidimensional analysis, have been optimized for years, and certain SQL engines already have the ability to implement such scenarios quite well, and achieve extreme performance. In contrast, SPL did little in automatic optimization., and depends almost entirely on programmers to write low-complexity code to achieve high performance. In this case, programmers need receive some training to familiarize themselves with SPL’s philosophy and library functions before getting started with SPL. Although this is an extra step in comparison with SQL, it is usually worthwhile as it enables us to improve the performance by order of magnitude, and reduce the cost by several times.
SPL Official Website 👉 http://www.scudata.com
SPL Feedback and Help 👉 https://www.reddit.com/r/esProc
SPL Learning Material 👉 http://c.scudata.com
SPL Source Code and Package 👉 https://github.com/SPLWare/esProc
Discord 👉 https://discord.gg/ydhVnFH9
Youtube 👉 https://www.youtube.com/@esProc_SPL

