

k-means cluster filling
K-means clustering, also known as fast clustering, is a clustering method that requires the number of categories to be determined in advance. K-means clustering can be used to divide all samples into several groups. If variables containing missing values are assumed to have different values in different groups, the mean value of the non-missing part of the variable in each group can be used to fill in the missing value of the corresponding position.
The kmeans() function is provided in SPL for fast clustering
For example, use k-means to fill in the "Age" variable in Titanic data.
Due to the existence of character variables in the titanic.csv data, which could not be directly used the k-means algorithm. So the categorical data were processed in advance and the processed data was titanic_impute.csv.
A |
|
1 |
=file("D://titanic_impute.csv").import@qtc() |
2 |
=A1.fname().delete(4).concat@c() |
3 |
=A1.new(${A2}) |
4 |
=A3.array().to(2:) |
5 |
=kmeans(A4,2,A4).conj() |
6 |
=A1.derive(A5(#):kmeans) |
7 |
=A6.groups(kmeans;avg(Age):avg_age) |
8 |
=A6.run(Age=if(!Age,if(kmeans>0,A7(2).avg_age,A7(1).avg_age),Age)) |
A1 Import titanic_impute.csv
A2-A3 Remove the variable Age
A4 Turn the sequence table with the Age variable removed into vector form
A5 Using kmeans() modeling and prediction, the data samples are divided into 2 categories.
A6 Add the classification results for each sample to the table A1
A7 Calculate the Age average for each group of categories.
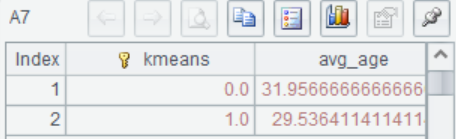
A8 Use the average of each group to fill in the missing values within that group. As shown in the figure, different groups of samples have different filling values.
SPL Official Website 👉 http://www.scudata.com
SPL Feedback and Help 👉 https://www.reddit.com/r/esProc
SPL Learning Material 👉 http://c.scudata.com
SPL Source Code and Package 👉 https://github.com/SPLWare/esProc
Discord 👉 https://discord.gg/ydhVnFH9
Youtube 👉 https://www.youtube.com/@esProc_SPL

