

Hot data caching routine
Overview
Data maintenance routine can implement regular maintenance and update of data. For real-time hot data, however, they can only be read instantly during query and then returned after being merged with historical data.
Based on this situation, the ability to quickly return results when querying real-time hot data and to handle frequent concurrent access is required, but this will impose a significant burden on the business system. If the real-time hot data can be stored separately in memory and read and returned directly from memory during query, it can greatly speed up the query speed and, it can also separate the real-time hot data from business system, which will not affect the normal operation of business system.
This routine provides a solution to such situation.
Related terms:
Data source: The original data storage or the source from which data is generated.
Hot data: Recently generated data.
Lifecycle: The length of time for which hot data needs to be retained. If it exceeds the length of time, the hot data will be automatically deleted.
Application scheme
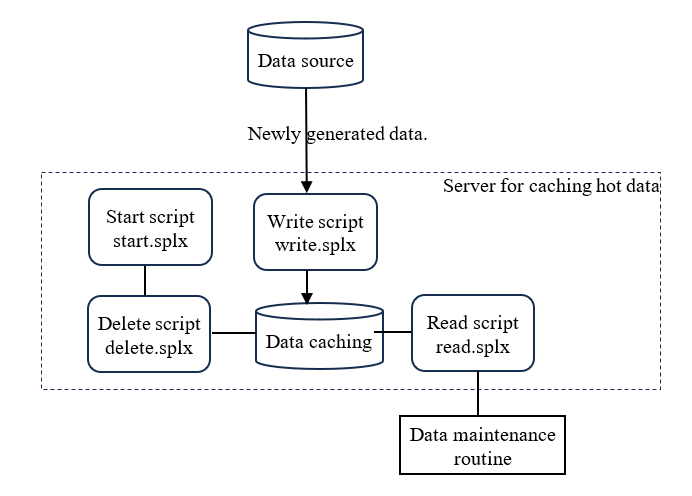
-
The write script ‘write.splx’ is used to add the newly generated hot data to the cache and back it up to file at the same time.
-
The delete script ‘delete.splx’ is executed regularly to automatically delete the data that exceeds the lifecycle, and the resulting data after deletion is also backed up synchronously to file.
-
The read script ‘read.splx’ uses the table name, filter condition and sort rule as input parameter to return the data that meets the conditions.
-
The start script ‘start.splx’ is executed at the startup of the server to read the configuration information and table data backed up on the hard disk into memory, and starts the backend thread to execute the delete script regularly.
Configuration information
The configuration information is stored in a file named “HotConfig.json”, which is located in the main directory.
[{ TableName:"one",
LifeCycle:60,
TimeField:"tdate",
SortField:"account,tdate"},
{……},
……]
TableName: table name.
LifeCycle: life cycle, in seconds.
TimeField: timestamp field, accurate to the millisecond.
SortField: sort field.
User interface
start.splx
This script is executed when the hot data caching service is started. It will read the configuration information into in-memory global variable, read the cached hot data backed up on hard disk into in-memory global variable, automatically read all files under the cache directory, and start the delete thread.
Input parameter:
None
Return value:
None
addConfig.splx
This script is used to add the configuration information of a new table to an in-memory global variable, and back up the information to file at the same time.
Input parameter:
config: the configuration information of a new table in the format of:
{TableName:"…",LifeCycle:…,TimeField:"…",SortField:"…"}
Return value:
None
write.splx
This script is used to add new data to an in-memory global variable. If the original variable does not exist, create a variable; if it exists, merge the new data by the sort field and back up the merged result to file at the same time.
Input parameters:
tbl: table name
data: new data
Return value:
None.
read.splx
This script is used to return data based on the filter conditions and sort rules. If the sort rules are empty, return the data according to its original order.
Input parameters:
tbl: table name
filter: filter conditions
sort: sort rules
Return value:
A sequence of data that meets conditions.
Storage structure

HotConfig.json is the file for storing configuration information.
The backup directory stores the backup data of all tables. For example:

It indicates that there are the backup files of two tables, with table names ‘multi’ and ‘one’ respectively.
Application example
A certain company group designs a power monitoring and statistical system, which is used to collect real-time data measured on multiple sensors at a fixed frequency. About 200,000 pieces of data are generated every second, the company hopes to retain the new data for 30 seconds before deleting them.
The name of configuration file is signal.json, which include:
{ TableName:"signal",
LifeCycle:30,
TimeField:"sTime",
SortField:"id,sTime"}
- Start the hot data catching service to execute start.splx.
| A | |
| 1 | =call("start.splx") |
- Add the configuration information of the signal table.
| A | |
| 1 | { TableName:"signal", LifeCycle:30, TimeField:"sTime", SortField:"id,sTime"} |
| 2 | =call("addConfig.splx",A1) |
- Call write.splx to add new data regularly.
| A | |
| 1 | =call("write.splx","signal",newData) |
- Call read.splx to obtain the data that meets the conditions.
| A | |
| 1 | =call("read.splx","signal","sTime<1711987200 && sTime>=1711900800)") |
Global variables
HotConfig: configuration information.
tbl: Take the table name as a global variable to store all data of the table in memory.
tbl: Take the table name as a global lock, which is used to add data to the table or delete data in the table. Since both the data addition and deletion are directly assigned, which belongs to atomic operation, locking is not required when query.
Code analysis
start.splx
This script is executed when the hot data caching service is started. It will read the configuration information into in-memory global variable, read the cached hot data backed up on hard disk into in-memory global variable, automatically read all files under the backup directory, and start the delete thread.
Input parameter:
None
Return value:
None
| A | B | C | D | ||
| 1 | =file("HotConfig.json") | ||||
| 2 | if(A1.exists()) | >env(HotConfig, json(A1.read())) | |||
| 3 | for HotConfig | =file("backup/"+B3.TableName+".btx") | |||
| 4 | if(C3.exists()) | =C3.import@b() | |||
| 5 | >env(${B3.TableName},D4) | ||||
| 6 | else | >env(HotConfig,[]) | |||
| 7 | =call@nr("delete.splx") | ||||
A1: The file that stores configuration information.
A2: If the file exists:
B2: Read the configuration information and assign it to the global variable HotConfig.
B3: Loop by the rows of the configuration information, with each row corresponding to a table:
C3: The backup file of current table.
C4: If the backup file exists:
D4: Read the data of the backup file.
D5: Assign the data to the global variable named after the table name.
A6: Otherwise:
B6: Assign the empty sequence to the global variable HotConfig.
A7: Start the delete thread.
addConfig.splx
This script is used to add the configuration information of a new table to an in-memory global variable, and back up the information to file at the same time.
Input parameters:
config: the configuration information of the new table in the format of:
{TableName:"…",LifeCycle:…,TimeField:"…",SortField:"…"}
Return value:
None
| A | |
| 1 | =env(HotConfig,HotConfig|config) |
| 2 | =file("HotConfig.json").write(json(HotConfig)) |
A1: Add the configuration information of the new table to the global variable HotConfig.
A2: Back up the configuration information to file.
delete.splx
This script is used to automatically delete the data that exceeds the LifeCycle. It runs every n seconds, and the resulting data after deletion is backed up to file.
Input parameter:
n: deletion interval, in seconds.
Return value:
None
| A | B | C | |
| 1 | for HotConfig | ||
| 2 | if ifv(${A1.TableName}) | ||
| 3 | =${A1.TableName}.select(long(now())-${A1.TimeField}>${A1.LifeCycle}*1000) | ||
| 4 | =lock(A1.TableName) | ||
| 5 | =env(${A1.TableName},${A1.TableName}\C3) | ||
| 6 | =file("backup/"+A1.TableName+".btx").export@b(${A1.TableName}) | ||
| 7 | =lock@u(A1.TableName) | ||
| 8 | =sleep(n*1000) | ||
| 9 | goto A1 | ||
A1: Loop by the global variable HotConfig.
B2: If the global variable named after the current table exists:
C3: Select the data with a length of time exceeding LifeCycle.
C5: After deleting the data with a length of time exceeding LifeCycle, assign the remaining data to the global variable named after the current table.
C6: Back up the remaining data to file.
write.splx
This script is used to add new data to an in-memory global variable. If the original variable does not exist, create a variable; if it exists, merge the new data by the sort field and back up the merged result to file at the same time.
Input parameters:
tbl: table name
data: new data
Return value:
None
| A | B | |
| 1 | =HotConfig.select@1(TableName==tbl) | |
| 2 | if(A1) | =lock(tbl) |
| 3 | >if(!ifv(${tbl}),env(${tbl},data),env(${tbl},[${tbl},data].merge(${A1.SortField}))) | |
| 4 | =file("backup/"+tbl+".btx").export@b(${tbl}) | |
| 5 | =lock@u(tbl) | |
| 6 | else | end tbl+"not exist" |
A1: Select the configuration information of current table.
A2: If the current layer exists:
B3: If the global variable named after the name of current table exists, merge the new data with the original data by the sort field, and then assign the merged data to the global variable. Otherwise, assign the new data directly to the global variable.
B4: Back up the data in the global variables to file.
read.splx
This script is used to return data based on the filter conditions and sort rules. If the sort rules are empty, return the data according to its original order.
Input parameters:
tbl: table name
filter: filter conditions
sort: sort rules
Return value:
A sequence of data that meets conditions.
| A | B | C | |
| 1 | if ifv(${tbl}) | =${tbl}.select(${filterExp}) | |
| 2 | if(sortExp) | >B1=B1.sort(${sortExp}) | |
| 3 | return B1 | ||
| 4 | else | return null |
A1: If the global variable named after the current table exists:
B1: Filter the data of current table by the filter conditions.
B2: If the sort expression is not empty, re-sort the filtered results by the sort expression.
B3: Return the filtered and sorted results.
SPL Official Website 👉 https://www.scudata.com
SPL Feedback and Help 👉 https://www.reddit.com/r/esProc_SPL
SPL Learning Material 👉 https://c.scudata.com
SPL Source Code and Package 👉 https://github.com/SPLWare/esProc
Discord 👉 https://discord.gg/cFTcUNs7
Youtube 👉 https://www.youtube.com/@esProc_SPL


Chinese version