

Perform Merge Group and Then Count over the 1st Group
【Question】
Group values in each field and count members in the first group. Based on the following data, the result is 2,3,1,2 (two As in field 1, three Cs in field 2, one D in filed 3, and two As in field 4).
ID field 1 field 2 field 3 field 4
1 A C D A
2 A C A A
3 B C E E
4 C E C E
5 B F C F
6 B G E F
7 C A C F
8 B A C F
9 A E E G
【Answer】
The job needs a nested subquery plus a window function, which makes the SQL query difficult to understand. Doing it in SPL (Structured Process Language) contains only one core line. It also applies to a scenario where the number of fields isn’t uniquely specified.
| A |
|
| 1 |
$select ID,field1,field2,field3,field4 from tb order by ID |
| 2 |
=to(2,5) |
| 3 |
=A2.(A1.(~.field(A2.~)).group@o(~)(1).len()).concat@c() |
A1: Get fields ordered by ID in SQL;
A3: Group field values by comparing each value with its next neighbor, count members in the first group and write the result in a specified format. To perform such a computation in a reversed order, just use order by ID desc.
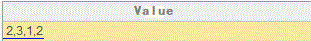
SPL Official Website 👉 https://www.scudata.com
SPL Feedback and Help 👉 https://www.reddit.com/r/esProcSPL
SPL Learning Material 👉 https://c.scudata.com
SPL Source Code and Package 👉 https://github.com/SPLWare/esProc
Discord 👉 https://discord.gg/2bkGwqTj
Youtube 👉 https://www.youtube.com/@esProc_SPL

