

Remove duplicates when combining rows and columns
When performing such an operation, the key functions are pivot and group respectively, which are used to convert columns to rows, remove the duplicate records, and then convert rows to columns.
Example
There is a csv file csv1.csv, as follows:
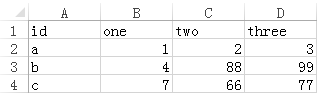
There is a csv file csv2.csv, as follows:

Now we need to merge the two tables in the order of csv2 and csv1, and keep the first value of all the duplicates. The results are as follows: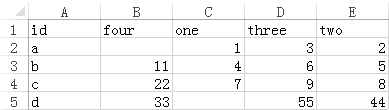
Write the SPL script:
A |
|
1 |
=file("csv1.csv").import@tc() |
2 |
=file("csv2.csv").import@tc() |
3 |
=A1.pivot@r(id;col,val) |
4 |
=A2.pivot@r(id;col,val) |
5 |
=(A3|A4).group@1(id,col) |
6 |
=A5.pivot(id;col,val) |
7 |
=file("result.csv").export@ct(A6) |
A1 Read data from csv
A2 Read data from csv
A3 Convert columns to rows
A4 Convert columns to rows
A5 After merging, group the data and take the first value in the group. Here pay attention to the order of merging, which will affect the final result. When there are multiple sets of data, use the conj function to merge them; here | is able to merge two sets
A6 Convert rows to columns
A7 Export results to result.csv
SPL Official Website 👉 https://www.scudata.com
SPL Feedback and Help 👉 https://www.reddit.com/r/esProc_Desktop/
SPL Learning Material 👉 https://c.scudata.com
Discord 👉 https://discord.gg/2bkGwqTj
Youtube 👉 https://www.youtube.com/@esProcDesktop
Linkedin Group 👉 https://www.linkedin.com/groups/14419406/

