

What is the lightweight Java library to read and write Excel dynamically, unlike Apache POI?
To other questions:
How to easily handle text file calculations in Java?
How to easily consolidate data from different sources in Java?
What should a Java programmer do when it is too difficult to write complex SQL?
What would be a dynamic and flexible way to transform Json to Java object?
How to perform SQL-like queries on MongoDB in Java?
What should I do when it is difficult to implement code with Java Stream?
Solution: esProc – the professional computational package for Java
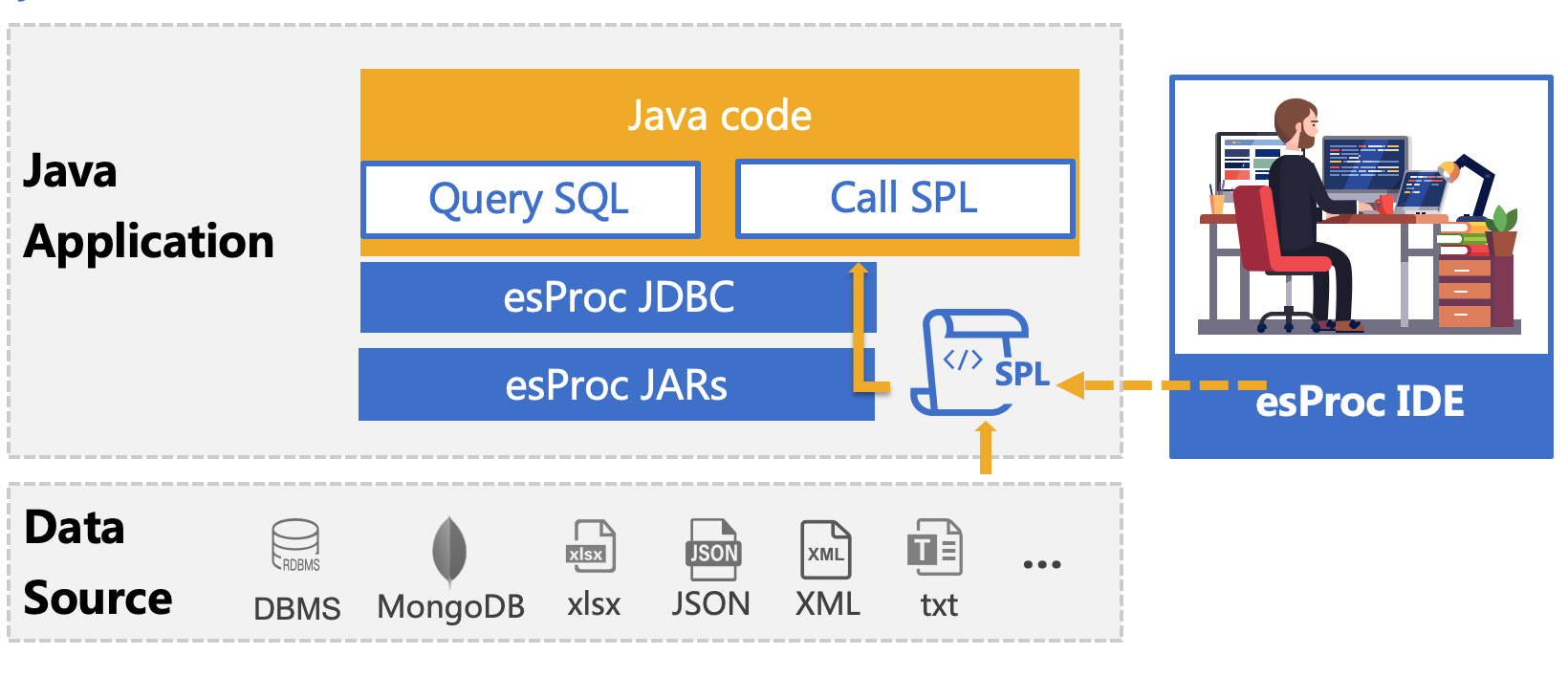
esProc is a class library dedicated to Java-based calculations and aims to simplify Java code. SPL is a scripting language based on the esProc computing package. It can be deployed together with Java programs and understood as a stored procedure outside the database. Its usage is the same as calling a stored procedure in a Java program. It is passed to the Java program for execution through the JDBC interface, realizing step-by-step structured computing. SPL is very lightweight and simple in syntax, similar to executing SQL to calculate Excel data and return a ResultSet object.
Let’s look at a very simple file: the first row is the column headings, and the second row until the last row is the data row. The content of the file is as follows:
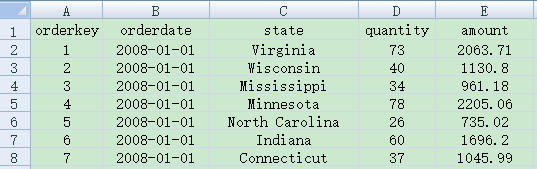
To use Java to call POI to read the data, we have the following program:
DataSet ds = null; //A user-defined class that stores data read from the Excel file;
HSSFWorkbook wb = new HSSFWorkbook( new FileInputStream( "simple.xls" ) );
HSSFSheet sheet = wb.getSheetAt( 0 ); //Assume the to-be-read data is stored in the first sheet
int rows = sheet.getLastRowNum();
int cols = sheet.getRow(0).getLastCellNum();
ds = new DataSet( rows, cols );
for( int row = 0; row <= rows; row++ ) {
HSSFRow r = sheet.getRow( row );
for( int col = 0; col <= cols; col++ ) {
HSSFCell cell = r.getCell( col );
int type = cell.getCellType();
Object cellValue; //Cell value object
switch( type ) { //Switch cell value to corresponding Java object according to its type
case HSSFCell.CELL_TYPE_STRING:
......
case HSSFCell.CELL_TYPE_NUMERIC:
......
......
// The cell value handling code is omitted
}
if( row == 0 ) ds.setColTitle( col, (String)cellValue );
else ds.setCellValue( row, col, cellValue );
//Set cell values of as column headers if they are in the 1st row, otherwise set them as a data set
}
}
The program can only read in an Excel file having the simplest format. It is quite long even the cell value handling part is omitted. It will be longer and more complicated if the Excel file has a complex format, such as merged cells, complicated multi-row table headers & footers, multi-row records, and crosstab. Even with such a powerful open-source package as POI, it’s still rather complicated to parse an Excel file in Java.
Moreover, java provides only low-level functions and lacks special functions for structured data computations like filtering, sorting, grouping & aggregation, and join over data sets. Programmers need to write theirs specifically. So there is still a lot of work to do even after data is read and parsed.
If you could use SPL to read the file, it is very simple, just write two lines of code:
A |
|
1 |
=file("simple.xls").xlsimport@t() |
2 |
=A1.select(amount>500 && amount<=2000) |
This block of code can be debugged or executed in esProc IDE, or stored as a script file (like condition.dfx) for invocation from a Java program through the JDBC interface. Below is the code for invocation:
package Test;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
public class test1 {
public static void main(String[] args)throws Exception {
Class.forName("com.esproc.jdbc.InternalDriver");
Connection connection =DriverManager.getConnection("jdbc:esproc:local://");
Statement statement = connection.createStatement();
ResultSet result = statement.executeQuery("call condition()");
printResult(result);
if(connection != null) connection.close();
}
…
}
This is similar to calling a stored procedure. SPL also supports the SQL-like way of embedding the code directly into a Java program without the need of storing it as a script file. Below is the code for embedding:
…
ResultSet result = statement.executeQuery("
=file(\"D:\\data\\simple.xls\").xlsimport@t().select(amount>500 && amount<=3000)");
…
For details on integration with Java programs, please refer to How to Call an SPL Script in Java
In fact, the esProc calculation library also encapsulates Apache POI, but provides a way to read Excel files more easily. Through the SPL professional data processing syntax, not only can read and write Excel very concisely, but also can perfectly support various subsequent calculations.
Read and write structured tables
The structured Excel table is more standardized, and the SPL can be read and written with the xlsimport/xlsexport function.
For example, the business meaning of each column of the first sheet in ordersNT.xlsx is order ID, customer number, sales ID, order amount, and order date. Part of the data is as follows:
A |
B |
C |
D |
E |
|
1 |
26 |
TAS |
1 |
2142.4 |
2009/8/5 |
2 |
33 |
DSGC |
1 |
613.2 |
2009/8/14 |
3 |
84 |
GC |
1 |
88.5 |
2009/10/16 |
4 |
133 |
HU |
1 |
1419.8 |
2010/12/12 |
5 |
32 |
JFS |
3 |
468 |
2009/8/13 |
6 |
39 |
NR |
3 |
3016 |
2010/8/21 |
7 |
43 |
KT |
3 |
2169 |
2009/8/27 |
Sort the table from small to large in alphabetical order of the customer number, and then sort the same customer number from large to small according to the order amount, and finally save the original format to the new Excel.
To calculate the above results, the following SPL script can be used:
A |
|
1 |
=file("D:/data/ordersNT.xlsx").xlsimport() |
2 |
=A1.sort(_2,-_4) |
3 |
=file("D:/data/ordersNT_sort.xlsx").xlsexport(A2) |
A1, A3: Read and write the first sheet of excel. If you want to read the specified sheet, you can use xlsimport (;sheet number or sheet name). If you want to write into the specified sheet, you can use xlsexport (A2; sheet number or sheet name)
SPL can also handle structured tables with column names (titles) in a similar way to text files. For example, some data of orders.xlsx is as follows:
A |
B |
C |
D |
E |
|
1 |
OrderID |
Client |
SellerId |
Amount |
OrderDate |
2 |
26 |
TAS |
1 |
2142.4 |
2009/8/5 |
3 |
33 |
DSGC |
1 |
613.2 |
2009/8/14 |
4 |
84 |
GC |
1 |
88.5 |
2009/10/16 |
5 |
133 |
HU |
1 |
1419.8 |
2010/12/12 |
6 |
32 |
JFS |
3 |
468 |
2009/8/13 |
7 |
39 |
NR |
3 |
3016 |
2010/8/21 |
8 |
43 |
KT |
3 |
2169 |
2009/8/27 |
Sort the file, and write the result into a new file with column names. You can use the following SPL script:
A |
|
1 |
=file("D:/data/orders.xlsx").xlsimport@t() |
2 |
=A1.sort(Client,-Amount) |
3 |
=file("D:/data/orders_sort.xlsx").xlsexport@t(A2) |
Sometimes we need to append new data with the same structure to the original table. In this case, we only need to use the @a option, like:
=file(""D:/data/orders_sort.xlsx").xlsexport@at(A2) |
If the appearance attribute is set for the last row of the original table with content, the additional data will inherit the style of the row. For example, the style of column D of the original table is #,##0.00, and the style of column E is mmm-dd-yyyy. The following table:
A |
B |
C |
D |
E |
|
1 |
OrderID |
Client |
SellerId |
Amount |
OrderDate |
2 |
26 |
TAS |
1 |
2,142.40 |
Aug-05-2009 |
3 |
33 |
DSGC |
1 |
613.20 |
Aug-14-2009 |
4 |
84 |
GC |
1 |
88.50 |
Oct-16-2009 |
After adding data, the results are as follows:
A |
B |
C |
D |
E |
|
1 |
OrderID |
Client |
SellerId |
Amount |
OrderDate |
2 |
26 |
TAS |
1 |
2,142.40 |
Aug-05-2009 |
3 |
33 |
DSGC |
1 |
613.20 |
Aug-14-2009 |
4 |
84 |
GC |
1 |
88.50 |
Oct-16-2009 |
5 |
133 |
HU |
1 |
1,419.80 |
Dec-12-2010 |
6 |
32 |
JFS |
3 |
468.00 |
Aug-13-2009 |
If the style attribute is set in the first blank row after the last row with content in the original table, the additional data will inherit the style attribute of the row. Using this feature, we can output data from scratch in a specified format. For example, create a blank Excel first, set the style of column D in row 2 to #,##0.00, and the style of column E to mmm-dd-yyyy.
A |
B |
C |
D |
E |
|
1 |
OrderID |
Client |
SellerId |
Amount |
OrderDate |
2 |
Then append data to the blank table, and the results are as follows:
A |
B |
C |
D |
E |
|
1 |
OrderID |
Client |
SellerId |
Amount |
OrderDate |
2 |
133 |
HU |
1 |
1,419.80 |
Dec-12-2010 |
3 |
32 |
JFS |
3 |
468.00 |
Aug-13-2009 |
Read and write cells
The previous content is to read and write Excel in units of tables or sequences, and sometimes we also read and write Excel in units of fine cells.
For example, the following table has the editor and edit date in line 1.
A |
B |
C |
D |
E |
|
1 |
editor:emily |
date:Dec-30-2011 |
|||
2 |
OrderID |
Client |
SellerId |
Amount |
OrderDate |
3 |
26 |
TAS |
1 |
2,142.40 |
Aug-05-2009 |
4 |
33 |
DSGC |
1 |
613.20 |
Aug-14-2009 |
5 |
84 |
GC |
1 |
88.50 |
Oct-16-2009 |
6 |
|||||
7 |
Copy the editor and edit the date to the corresponding position on line 7. The result should be as follows.
A |
B |
C |
D |
E |
|
1 |
editor:emily |
date:Dec-30-2011 |
|||
2 |
OrderID |
Client |
SellerId |
Amount |
OrderDate |
3 |
26 |
TAS |
1 |
2,142.40 |
Aug-05-2009 |
4 |
33 |
DSGC |
1 |
613.20 |
Aug-14-2009 |
5 |
84 |
GC |
1 |
88.50 |
Oct-16-2009 |
6 |
|||||
7 |
editor:emily |
date:Dec-30-2011 |
To calculate the above results, the following SPL script can be used:
A |
B |
|
1 |
=file("D:/data/cell.xlsx") |
|
2 |
=A1.xlsopen() |
|
3 |
=str=A2.xlscell("A1") |
=A2.xlscell("A7";str) |
4 |
=str=A2.xlscell("E1") |
=A2.xlscell("E7";str) |
5 |
=A1.xlswrite(A2) |
A2: Open the Excel file as an object.
A3: Read the A1 cell and assign the variable str. The default is to read from the first sheet. If you want to read the A1 cell in the specified sheet, you can use A2.xlscell("A1", sheet serial number or sheet name)
B3: Write cell A1 into cell A7. Similarly, if you want to write cell A7 in the specified sheet, you can use A2.xlscell("A7", sheet serial number or sheet name; str)
A4-B4: Read E1 and write to E7
A5: Write the result into the Excel file.
In the above example, the A1-E1 that needs to be read are continuous cells, and the A7-E7 that needs to be written is also continuous cells. For this continuous cell reading and writing, SPL can be implemented with a more simplified code. For example, the code in the above example can be changed to:
A |
|
1 |
=file("cell.xlsx") |
2 |
=A1.xlsopen() |
3 |
=arry=A2.xlscell@w("A1":"E1") |
4 |
=A2.xlscell("A7":"E7";arry) |
5 |
=A1.xlswrite(A2) |
A3: Read consecutive cells in sequence format
A4: Write a sequence to consecutive cells. Each member of the sequence corresponds to a cell. You can either use a sequence to write data to consecutive cells or use a string separated by \t or \r, where \t means horizontal(columnar) separation, and \r means vertical (cross-line) separation.
Multi-sheet processing
Using Excel objects, not only can read and write cells but also can process multiple sheets, as illustrated below.
An Excel uses multiple sheets to store order. Each sheet has the same format, but the number and name are variable. Now we need to sort these orders into the new Excel, and each sheet will store one year's data.
To calculate the above results, the following SPL script can be used:
A |
|
1 |
=file("orders_sheet.xlsx").xlsopen() |
2 |
=A1.(stname).(A1.xlsimport@t(;~)).conj() |
3 |
=A2.group(string(year(OrderDate)):name;~:content) |
4 |
=file("orders_result.xlsx").xlsopen@w() |
5 |
=A3.(A4.xlsexport@t(~.content;string(~.name))) |
6 |
=A4.xlsclose() |
A1: Open the source Excel file as an object.
A2: Traverse each sheet, read the order of each sheet, and then merge all the orders. A1. (stname) means to take out all sheet names from the Excel object A1.
A3: Group the orders by year.
A4: Open the target Excel file as an object. @w means write mode, and a new file will be created if the file does not exist.
A5: Traverse each group (yearly) orders of A3 and write them into the new sheet of A4 in turn.
A6: The Excel object opened in @w mode must be closed with the function xlsclose.
Multi-file processing
- Associative calculation
Perform correlation calculations on the data in the two data tables.
Example: The sales order information and product information are stored in two Excel files, respectively, and the sales amount of each order is calculated. The data structure of the two files is as follows:

A |
|
1 |
=T(“e:/orders/sales.xlsx”) |
2 |
=T(“e:/orders/product.xlsx”).keys(ID) |
3 |
=A1.join(ProductID,A2,Name,Price) |
4 |
=A3.derive(Quantity*Price:amount) |
A1 Read sales order data.
A2 Read product information data, set ID as the primary key
A3 associates A1 with the primary key in A2 according to ProductID , and at the same time takes out Name and Price column data.
A4 A3 adds a new column of amount, and its value is the sales quantity Quantity multiplied by the product price Price.
- Associative query
Perform an associated query on the data in the two data tables.
Example: Still use the two files in the previous section to query sales orders with product prices greater than 20 yuan.
A |
|
1 |
=T(“e:/orders/sales.xlsx”) |
2 |
=T(“e:/orders/product.xlsx”).select(Price>20).keys(ID) |
3 |
=A1.switch@i(ProductID,A2) |
A1 Read sales order data.
A2 Read the product information data, select the product information with a price greater than 20, and then set the ID as the main key.
A3 according to ProductID, A1 to be associated with the primary key of A2, the option @i represents A2 is not found in the ProductID match the product ID, then this record was filtered off.
- query main table and subtable
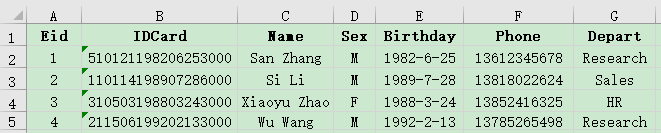
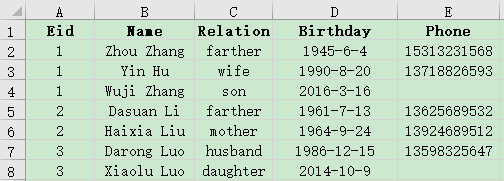
Associative query on the main table and detailed table data, Example: Some data in the employee information table employee.xlsx and employee family member table family.xlsx are as follows. Please query the information of employees who have an elderly person over 70 years old at home.
A |
|
1 |
=T("e:/work/employee.xlsx") |
2 |
=T("e:/work/family.xlsx").select(age(Birthday)>=70) |
3 |
=join(A1:employee,Eid;A2:family,Eid) |
4 |
=A3.conj(employee) |
A1 Read employee data.
A2 Read employee family member data and select members over 70.
A3 associates A1 and A2 according to Eid, deletes unmatched records, and names A1 as employee and A2 as family.
A4 takes out the employee column in A3 and joins it as a table sequence
Know more
General table operations, refer to SPL general table operations
Examples of manipulating data for Excel, refer to Manipulating data for Excel
SPL parsing and exporting Excel, refer to SPL parsing and exporting Excel.pdf
SPL Official Website 👉 https://www.scudata.com
SPL Feedback and Help 👉 https://www.reddit.com/r/esProc_SPL
SPL Learning Material 👉 https://c.scudata.com
SPL Source Code and Package 👉 https://github.com/SPLWare/esProc
Discord 👉 https://discord.gg/cFTcUNs7
Youtube 👉 https://www.youtube.com/@esProc_SPL

