

SPL: Reading and Writing Database Data
Most of the time, businesses store their data in RDBs. It is convenient and fast to read and write data in the database in SPL (Structured Process Language). Take the following employees table in MySQL MyCompany database as an example, and we’ll look at how SPL performs database data reading and writing.
Data reading
Using SQL
We get records of 100 employees according to the hire dates sorted in ascending order in SQL, and execute the following SPL script within esProc:
A |
|
1 |
=connect("MyCompany") |
2 |
=A1.query("select * from employees order by hire_date asc limit 100") |
3 |
>A1.close() |
A1: Connect to MyCompany database.
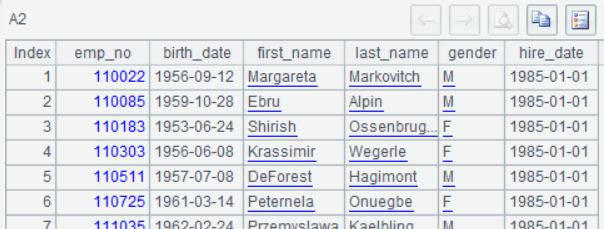
A2: Along A1’s connection, query() function executes the SQL and then we can select A2 to view result as follows:
A3: Close A1’s database connection. A database connection must be closed after execution is finished to avoid meaningless resource consumption.
Returning the first record
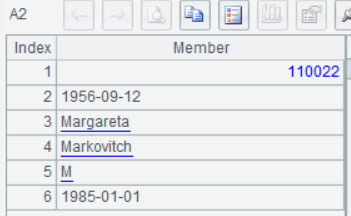
The query function works with @1 option to return the first eligible record. A sequence will be returned when the record has multiple fields.
A |
|
2 |
=A1.query@1("select * from employees order by hire_date asc") |
The above SPL script returns a result as follows:
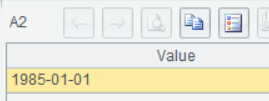
The field value will be returned when the record has only one field.
A |
|
2 |
=A1.query@1("select hire_date from employees order by hire_date asc") |
The above script returns a single value:
Adjusting degree of accuracy for numeric field values
By default, query() function returns the decimal type numeric field value. If an ordinary degree of accuracy is sufficient and your priority is performance increase, you can use @d option to change the data type to double, as shown in the following statement that queries salaries:
A |
|
2 |
=A1.query@d("select salary from salaries limit 100") |
Auto-closing database connection
We can achieve database connection, data query and connection close in one statement when we are trying to connect to the database for an ad hoc query. @x option enables auto-closing the database connection after the query is finished.
A |
|
1 |
=connect("MyCompany").query@x("select max(emp_id) from employees") |
A query through parameters
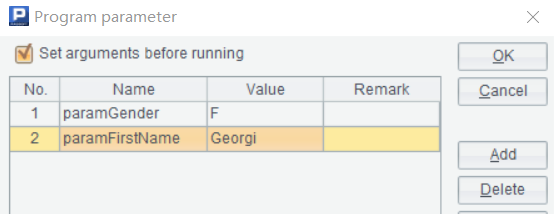
In a business system, the server-side Java program defines a SQL template to which parameter values are passed in for performing a database query. A SPL script can also receive parameter values.
A |
|
2 |
=A1.query("select * from employees where gender=? and first_name=? limit 10",paramGender, paramFirstName) |
The first parameter in the above query function is a SQL statement, where quotation marks are used in order to represent parameters whose values will be passed in. For the second parameter, dynamic values will be passed in in turn (Values can be predefined ones, or a SPL variable defined in a certain cell).
The parameter can be of date type, such as date(1990,1,1), or of string type in a date format, such as "1990-12-31". The following statement finds the number of employees who are hired in the year 1990:
A |
|
2 |
=A1.query("select count(*) from employees where hire_date>=? and hire_date<=?" , date(1990,1,1) , "1990-12-31") |
The set parameter in IN operator
The SQL IN operator usually has multiple parameters, which are represented by quotation marks and whose values are written after them, as shown below:
A |
|
2 |
=[500000,500001,500002] |
3 |
=A1.query("select * from employees where emp_id in (?,?,?)",A2(1),A2(2),A2(3)) |
Below is the simpler way of writing parameters. There is only one quotation mark and the sequence of parameters as a whole is treated as one parameter:
A |
|
2 |
=[500000,500001,500002] |
3 |
=A1.query("select * from employees where emp_id in (?)",A2) |
Big data reading with cursor
There are millions of rows of data in salaries table. Loading them all into the memory could result in overflow. So, cursor function is used to do the loading. The function has similar uses to query function except that it won’t load data immediately. Instead, we use fetch(n) function to retrieve data part by part for processing. To get 100 rows each time, sum salaries cumulatively, and count rows until all data is retrieved and loop is stopped, for instance, we have the following SPL script, where A6 calculates the average salary:
A |
B |
C |
D |
|
1 |
=connect("MyCompany") |
|||
2 |
=A1.cursor("select * from salaries") |
|||
3 |
>all=0,count=0 |
|||
4 |
For |
=A2.fetch(100) |
if (B4==null) |
break |
5 |
>all+=B4.sum(salary) |
>count+=B4.count() |
||
6 |
=all/count |
|||
7 |
>A1.close() |
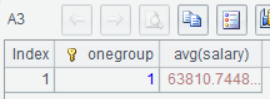
The above script uses the cursor in a rather roundabout way in order to display the process as clear as possible. In practice, we can directly user related cursor functions. The following script, for instance, uses groups and avg functions to calculate the average salary. These functions have a built-in mechanism to calculate data while do the loading. Even if the original table is huge, the memory usage is small.
A |
|
1 |
=connect("MyCompany") |
2 |
=A1.cursor("select * from salaries") |
3 |
=A2.groups(1:onegroup;avg(salary)) |
4 |
>A1.close() |
Data writing
SPL execute function executes writing operations towards the database (including SQL INSERT/UPDATE/DELETE). It has almost the same uses as query function.
Update database by executing SQL
In execute(sql, paramValue1, paramValue2, paramValue3,……), parameters after the sql statement are passed in in order. To insert new data to the database, for instance:
A |
|
2 |
=A1.execute("insert into employees (emp_no,birth_date,first_name,last_name,gender,hire_date) values (?,?,?,?,?,?)",10007,"1957-05-23","Tzvetan","Zielinski","F","1989-02-10") |
Continuous parameters, as the above shows, in a SQL statement can be written simply as one quotation mark, and parameter values after them can be written in one sequence, as shown below:
A |
|
2 |
=A1.execute("insert into employees (emp_no,birth_date,first_name,last_name,gender,hire_date) values (?)",[10007,"1957-05-23","Tzvetan","Zielinski","F","1989-02-10"]) |
To update database data:
A |
|
2 |
=A1.execute("update employees set gender=? where emp_no=?","M",10007) |
To delete database data:
A |
|
2 |
=A1.execute("delete from employees where emp_no=?",10007) |
Batch database update
emps.txt stores data that will be inserted into employees table:
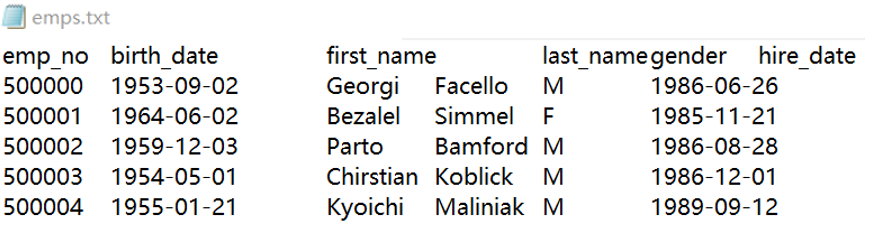
We can use for statement to insert the data to the database row by row. An alternative is to perform batch update using execute function. In the script below, A2 import data from emps.txt into the memory and store it as a SPL table sequence. A3 uses execute function to update A2’s table sequence. Parameters #1,#2,#3… in execute function represent the first, second, third… fields in A2’s table sequence. You can also use the field names directly as A4 does.
A |
|
1 |
=connect("MyCompany") |
2 |
=file("d:/emps.txt").import@t() |
3 |
=A1.execute(A2,"insert into employees (emp_no,birth_date,first_name,last_name,gender,hire_date) values (?,?,?,?,?,?)",#1,#2,#3,#4,#5,#6) |
4 |
/=A1.execute(A2,"insert into employees (emp_no,birth_date,first_name,last_name,gender,hire_date) values (?,?,?,?,?,?)",emp_no,birth_date,first_name,last_name,gender,hire_date) |
5 |
>A1.close() |
Batch table-based writing
The batch writing can only perform on action (batch insert, batch update or batch delete). Imagine you have a scenario, where you read some records, store them in a table, and edit them. The editing may involve addition, deletion and modification. Then you need to write the edited table data back to the database. This is a complicated process where you compare data with the original, generate INSERT, DELETE, or UPDATE statement accordingly, or need to handle the self-increment primary key. SPL has update function to handle the scenario more conveniently by encapsulating all those operations. Only one statement is sufficient to achieve the batch table-based data writing.
Retrieve data to be modified from the database and store it in emp_old.xlsx:
Then we modify data as required and store the modified data in emps.xlsx. In the following desired result, the first three rows in red are modified data; the original rows where emp_no is 500003 and 500004 are deleted; and the last two rows in green are newly added.
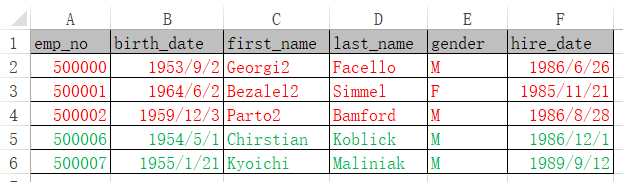
In the SPL script below, A4’s update function updates the database table employoees by comparing the new data (A3) with the old data (A2). The updated fields are emp_no, birth_date, first_name, last_name, gender, and hire_date. The last semicolon specifies the emp_no as the primary key. We compare the primary key values in the old data and the new data to identify the to-be-added, to-be-modified, and the to-be-deleted.
A |
|
1 |
=connect("MyCompany") |
2 |
=file("d:/emps_old.xlsx").xlsimport@tx() |
3 |
=file("d:/emps.xlsx").xlsimport@tx() |
4 |
=A1.update(A3:A2,employees,emp_no,birth_date,first_name,last_name,gender,hire_date;emp_no) |
5 |
>A1.close() |
update function can add new data, delete data and modify data at the same time. It can also perform only one of them by working with the specific option. @i option is for adding new data, @u for modifying data, and @d for deleting data.
A |
|
=A1.update@i(...) / For adding new data only |
|
=A1.update@u(...) / For modifying data only |
|
=A1.update@d(...) / For deleting data only |
Besides the three options for controlling update style, there is another @a option for clearing up the target table and inserting new data.
A |
|
=A1.update@a(...) / Clear up the database table and insert new data |
Some database tables have self-increment primary keys. SPL has @1 option to indicate that the first field is such a primary key. In this case, you do not need to specifically specify the primary key (emp_no) in the update function. In the modified A3’s table sequence, a row where emp_no is null, empty string, or where the value is not included in A2’s old table sequence will become the newly-added, and the new emp_no values are the results of automatic database increment.
A |
|
4 |
=A1.update@1(A3:A2,employees,emp_no,birth_date,first_name,last_name,gender,hire_date) |
It is convenient to use update function to update the database. Yet, it is slower than executing function that executes simple updates due to its complicated built-in actions. You need to be really careful to select the appropriate function for your task.
Transaction control
Both update function and execute function can work with @k option to not to submit a transaction automatically. Instead, we can check whether there are any errors after a series of operations are finished and, if there are any, decide whether we should submit the transaction using db.commit()or execute rollback with db.rollback() to cancel all updates according to the error type.
The program, after database is connected, will automatically terminate the execution if an error happens to any of the multiple writing operations. If you do not want to terminate the program when error occurs, just use @e option in connect function in A1’s database connection action and then in the subsequent A2, A3 and A4, use @k in execute and update functions to disable auto-submission in case that processed data has been submitted when error appears, and thus dirty data is avoided. A5 uses db.error()to check whether there are errors within the database connection, and execute db.commit() in B5 if there are not, or db.rollback() in B6 to cancel all writing operations if there are any.
A |
B |
|
1 |
=connect@e("MyCompany") |
|
2 |
=A1.execute@k("insert into …") |
|
3 |
=A1.update@k(...) |
|
4 |
=A1.execute@k("delete…") |
|
5 |
if A1.error()==0 |
>A1.commit() |
6 |
else |
>A1.rollback() |
7 |
>A1.close() |
Calling a stored procedure
Suppose we have a predefined stored procedure proc 1 that has two input parameters – the string type param1 and the integer type param2:
delimiter $
create procedure proc1 (
in param1 varchar(100)
,in param2 int
) begin
update employees set first_name=param1 where emp_no=param2;
end$
delimiter ;
In SPL, we can use the execute function to perform the update by passing in two parameter values "Kyoichi", 500001 to it.
A |
|
2 |
=A1.execute("{call proc1(?,?)}","Kyoichi",500001) |
The stored procedure is successfully executed as the employee record’s first_name is modified into Kyoichi after execution.
The above method only applies to stored procedures without return values. To execute a stored procedure with one or more returned values, SPL has proc function. The following stored procedure has two input parameters and two output parameters:
delimiter $
create procedure proc2 (
in param1 varchar(100)
,in param2 int
,out param3 int
,out param4 int
) begin
SELECT count(*) into param3 FROM employees WHERE first_name=param1 and emp_no>param2;
SELECT count(*) into param4 FROM employees WHERE first_name<>param1 and emp_no>param2;
end$
delimiter ;
In the following SPL script, A2 executes the stored procedure. Two output parameters return two variables r1 and r2. r1 stores the number of employees records where emp_id is greater than 400000 and where first_name is Kyoichi. r2 stores that of employees records where emp_id is greater than 400000 and where first_name isn’t Kyoichi.
A |
|
1 |
=connect("MyCompany") |
2 |
=A1.proc("{call proc2(?,?,?,?)}","Kyoichi":11:"i":,400000:11:"i":,"@r1":11:"o":r1,"@r2":11:"o":r2) |
3 |
>A1.close() |
Once the script is executed, values of r1 and r2 are calculated and displayed under Cellset variable.
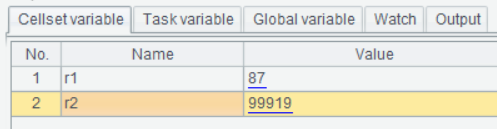
The format of parameters in proc function is complicated. Each parameter has four values separated by three colons - {input value}:{data type}:{parameter type}:{output value variable name}.
Input value: The value of an input parameter. For an output parameter, the value is a variable name (MySQL) or a null (Oracle). When it is null, the colon after it must be retained;
Data type: Refer to Stored Procedure Data Type Definition;
Parameter type: "i" represents an input parameter and "o" represents an output parameter;
Output value variable name: The SPL variable corresponding to a stored procedure’s output parameter. In the above scripts, we can view the two output tables in A3 and A4 through the corresponding variables. If it is an input parameter, the value is null but the colon before it must be retained.
Below are two MySQL stored procedures. Oracle has a different way to execute the stored procedure. The database supports cursor data type for an output parameter, making it convenient to return multiple multirow result sets, as shown in the following code, where two returned result sets contain eligible, complete employees records instead of numbers of employees.
create or replace procedure proc3 (
param1 in varchar2
,param2 in int
,param3 out sys_refcursor
,param4 out sys_refcursor
) as
begin
open param3 for select * from FROM employees WHERE first_name=param1 and emp_no>param2;
open param4 for select * from FROM employees WHERE first_name<>param1 and emp_no>param2;
end proc3;
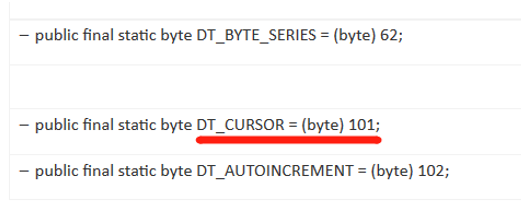
SPL uses 101 to define a cursor data type. In the following script, A2 calls the cursor to execute:
A |
|
1 |
=connect("MyCompany") |
2 |
=A1.proc("{call proc3(?,?,?,?)}","Kyoichi":11:"i":,400000:11:"i":,:101:"o":r1,:101:"o":r2) |
3 |
>A1.close() |
SPL Official Website 👉 https://www.scudata.com
SPL Feedback and Help 👉 https://www.reddit.com/r/esProcSPL
SPL Learning Material 👉 https://c.scudata.com
SPL Source Code and Package 👉 https://github.com/SPLWare/esProc
Discord 👉 https://discord.gg/2bkGwqTj
Youtube 👉 https://www.youtube.com/@esProc_SPL

