

SPL Programming - 4.1 [Sequence] Sequence
In the previous programs we wrote, there are only a few original input data. The data processed by loop code is also calculated by code according to some rules, not the original data. In practice, the original data we need to process is often a large number of data, and we need to use the concept of set.
However, most programming languages do not retain the term set, but use array to represent batch data. SPL uses the term sequence to emphasize the order between batch data. Sequence and array can be understood as the same thing, only that the idiom is different, and sequence is mainly used in this book.
A batch of data in order can form a sequence, which can be stored and named by a variable name. The data forming the sequence is called the members of the sequence, and the number of members forming the sequence is called the length of the sequence.
In SPL, write the data in turn in square brackets and separate them with commas to get the sequence constants, such as:
| A | |
|---|---|
| 1 | [1,2,3,4,5] |
| 2 | =[3,9,0,2,2.3,9.8] |
| 3 | =[] |
A1 and A2 are sequences, where A1 is a constant cell and A2 is a calculation cell. A3 is also a calculation cell, and its result is an empty sequence, that is, a sequence without members. The length of an empty sequence is 0. However, an empty sequence is not a null value.
In many programming languages, the members of an array must be of the same data type. However, there is no such requirement in SPL. Members of a sequence can have different data types, but in most cases, the sequence is composed of members of the same data type.
Sequence members can use other variables or expressions:
| A | B | C | D | |
|---|---|---|---|---|
| 1 | 3 | =4+8 | =pi() | =3*C1 |
| 2 | =[3,A1,D1,3*B1] | =[B1,C1+A1,0] |
A2 and B2 can also define a sequence, but the sequence that needs to be calculated must be defined by the calculation cell, and it needs to be executed before it has a value.
SPL can also use a cell range to define a sequence like Excel:
| A | B | C | D | |
|---|---|---|---|---|
| 1 | 4 | 8 | 3 | 2 |
| 2 | 5 | 2 | 0 | -5 |
| 3 | =[A1:D2] |
A sequence of length 8 is calculated in A3. The members are arranged from left to right and from top to bottom in the order of cells. This sequence is equivalent to [4,8,3,2,5,2,0, - 5].
You can access the member corresponding to a sequence number by adding the number in parentheses after the sequence variable. You can either get the value or assign the value:
| A | B | C | D | |
|---|---|---|---|---|
| 1 | 4 | 8 | 3 | 2 |
| 2 | 5 | 9 | 0 | -5 |
| 3 | =[A1:D2] | =A3(2) | =A3(5) | >A3(4)=3 |
| 4 | =A3(1)+A3(3) | =A3(A3(4)) | =A3(A4) |
After execution, the cell values of B3 and C3 is 8 and 5 respectively. After D3 is executed, the fourth member of A3 will be changed to 3(was 2 before), but the value of D1 will not be changed. When A3 is assigned, the value of D1 has been copied to the member of A3. When A3 is changed, it has nothing to do with D1.
Sequence members can participate in operations, and can also refer to other members of the sequence as sequence numbers. A4 will be calculated as 7, B4 will be calculated as 8, C4 will be calculated as 0.
The sequence number of a sequence member, sometimes is referred to as its position in the sequence.
If you click the cell where the sequence is located, the development environment can also display the value of the sequence, which will be listed as a table, such as A3 of the above code:
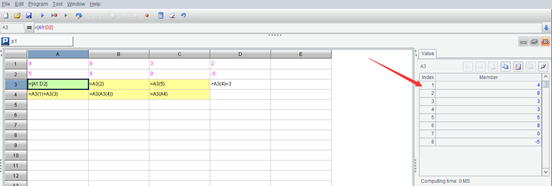
In SPL, the sequence number of sequence members starts from 1, and the reference of a member uses parentheses. In some programming languages, the sequence number of array members starts from 0, and the reference of a member uses brackets. This should also be noted when learning programming language.
In fact, a sequence variable can be simply understood as a group of variables with the same name, which should be distinguished by sequence numbers. Each member can be regarded as an independent variable. If the sequence number exceeds the limit, it is equivalent to referring to a non-existent variable, and the program will report an error.
The above-mentioned method of generating a sequence needs to write out the members one by one (in fact, it is the same when generating sequence with cell range). If we want to generate a sequence with hundreds or thousands of members, this method is obviously out of the question.
In SPL, the syntax of the expression [x]*n can be used to generate a sequence of length n and each member is x. For example, [0]*100 will return a sequence with 100 zeros as members, so we can create a sequence of any length.
The sequence created by this method will have an initial value for all members. So, can there be a sequence with no initial value, just with vacant positions?
In fact, this is meaningless. Any variable in a computer program will always occupy some memory space, and there will always be some data in the space. The only difference is how to interpret the data according to the variable type. There is no “vacuum” value that does not occupy the space. We usually say the null value, that is, null, is also a data type, it also takes up some storage space. You can also use [null]*n to generate a sequence, but it is not much different from [0]*n in space occupation.
In SPL, null and 0 are different, that is, null!=0 will be evaluated as true, similar to SQL; But in some programming languages, null and 0 are the same thing (such as C).
We’ll talk about how to generate and process a sequence with uncertain length later.
Having learned sequence, we can change the previous example of calculating the Narcissus numbers and write all the Narcissus numbers into a sequence:
| A | B | C | D | E | F | |
|---|---|---|---|---|---|---|
| 1 | =0 | =[0]*100 | ||||
| 2 | for 9 | =100*A2 | =A2*A2*A2 | |||
| 3 | for 0,9 | =B2+10*B3 | =C2+B3*B3*B3 | if C3<D3 | break | |
| 4 | for 0,9 | =C3+C4 | =D3+C4*C4*C4 | |||
| 5 | if D4==E4 | >A1+=1 | >B1(A1)=D4 | |||
| 6 | else if D4<E4 | break |
Assuming that there are at most 100 Narcissus numbers (actually far less than 100), generate a sequence of length 100 in B1. A1 is the number of Narcissus numbers currently found. For each one found, let A1 increase by 1, and then fill in the corresponding member in B1. Finally, those members in the front of B1 that are not 0 are all the Narcissus numbers.
We will reform the problem of prime factorization later.
Let’s use sequence to implement a classic algorithm: bubble sorting.
Giving a group of numbers, or a sequence, we need to rearrange the members of the sequence from small to large.
The algorithm process of bubble sorting is as follows: scan the sequence from head to end, if the size of adjacent members is not appropriate, such as the previos number is larger than the next one, then exchange the two numbers. After a scan, if an exchange action has occurred, it is necessary to scan again until no exchange has occurred in a scan, and the sorting is completed.
| A | B | C | D | |
| 1 | =[3,4,12,4,6,9,3,5] | =A1.len()-1 | =true | |
| 2 | for D1 | >D1=false | ||
| 3 | for C1 | if A1(B3)>A1(B3+1) | =A1(B3) | |
| 4 | >A1(B3)=A1(B3+1) | |||
| 5 | >A1(B3+1)=D3 | |||
| 6 | >D1=true | |||
The data to be sorted is in A1. After the outer loop starts, D1 is set to false to assume that this is the last loop, and then the sequence is scanned. If the size of adjacent members is not appropriate, the exchange is implemented, and D1 is set to true, so that the next outer loop can be carried out. If there is no exchange, D1 remains false and the outer loop ends.
There is another common variant of bubble sorting:
| A | B | C | D | |
| 1 | =[3,4,12,4,6,9,3,5] | =A1.len() | =C1-1 | |
| 2 | for D1 | for A2+1,C1 | if A1(A2)>A1(B2) | =A1(A2) |
| 3 | >A1(A2)=A1(B2) | |||
| 4 | >A1(B2)=D2 | |||
Please try to understand the principle of it by yourself.
With sequence and its sorting ability, we can simplify the previous problem of black hole number, and use the variant of bubble sorting to sort (from large to small here):
| A | B | C | D | E | |
| 1 | 1234 |
||||
| 2 | for |
=[A1\1000,A1\100%10,A1\10%10,A1%10] |
>C6=D6=0 |
||
| 3 | for 3 |
for B3+1,4 |
if B2(B3)<B2(C3) |
=B2(B3) |
|
| 4 | >B2(B3)=B2(C3) |
||||
| 5 | >B2(C3)=E3 |
||||
| 6 | for 4 |
=C6*10+B2(B6) |
=D6*10+B2(5-B6) |
||
| 7 | >output(A1) |
=C6-D6 |
if C7==A1 |
break |
|
| 8 | >A1=C7 |
||||
With sequence, we can use loop (B6:D6) to calculate the four-digit number. Before that, we need to fill C6 and D6 with 0(cell E2), and then we can correctly calculate the maximum and minimum four-digit numbers through the loop of B6:D6. In cell E2, as mentioned before, a=x is also regarded as a calculation expression, and will have a value. D6=0 will be calculates as 0 at the same time of assigning 0 to D6, and then it is assigned to C6. As a result, both C6 and D6 become 0.
SPL Programming - Preface
SPL Programming - 3.4 [Doing loop] Endless loop
SPL Programming - 4.2 [Sequence] Loop of sequence
SPL Official Website 👉 https://www.scudata.com
SPL Feedback and Help 👉 https://www.reddit.com/r/esProcSPL
SPL Learning Material 👉 https://c.scudata.com
SPL Source Code and Package 👉 https://github.com/SPLWare/esProc
Discord 👉 https://discord.gg/2bkGwqTj
Youtube 👉 https://www.youtube.com/@esProc_SPL

