

SPL Programming - 10.2 [Association] Foreign key
With a primary key, we can uniquely identify a record. Then, we can establish the association between the records of different data tables.
First, generate two tables with primary key for experiments. For simplicity, we use integers as primary key, but the order is deliberately disrupted.
| A | B | C | |
|---|---|---|---|
| 1 | [HR,R&D,Sales,Marketing,Admin] | =A1.len().sort(rand()) | =100.sort(rand()) |
| 2 | =A1.new(B1(#):did, ~:name, C1(#):manager ).keys(did) | [CHN,USA] | |
| 3 | =100.new(C1(#):eid,C2(rand(2)+1):nation,rand(5)+1:dept).keys(eid) | ||
| 4 | =A2.run(A3(manager).dept=did) | ||
A2 is a department table, each record corresponds to a department, the did field is the department number, which is used as the primary key, and the name field is the department name; A3 is the employee table, each record corresponds to an employee, eid field is the employee number, which is used as the primary key, and the nation field is the employee’s nationality. The employee table usually has a name field, but it’s useless here, so we won’t generate it.
The key points are the dept field of A3 and the manager field of A2. dept stores an integer representing the department to which the employee belongs. The department of the employee corresponding to record e in the employee table is the department corresponding to record d with e.dept as the primary key in the department table. We will also say that record e is associated with record d.
The manager field of A2 indicates the manager of the department. The manager is also an employee and will also appear in the employee table. The manager of the department corresponding to record d in the department table is the employee corresponding to record e with d.manager as the primary key in the employee table. We also say that the two records d and e are associated.
Understanding this relationship makes the role of A4 clear. Because the randomly generated data can not guarantee that the manager’s department is his own department, it should be adjusted in A4 so that this data can be used.
Now we want to list all the people in the R&D department.
This is a simple selection problem, and we should use the select() function. However, there is no department name in the employee table, and there is only the department number. The selection can only be done by using the number to find the department name in the department table.
| A | B | C | |
|---|---|---|---|
| … | … | ||
| 5 | =A3.select(A2.find(dept).name==“R&D”) | ||
Similarly, we can also list all departments where the manager is American:
| A | B | C | |
|---|---|---|---|
| … | … | ||
| 5 | =A2.select(A3.find(manager).nation==“USA”) | ||
In this way, we associate the employee table with the department table, and can jointly use the information of the two tables for operation. The dept field in the employee table is always the primary key of a record in the department table, and it is also used to represent this record in the department table. We call this field a foreign key, and a more complete saying is the foreign key pointing to the department table in the employee table. Through the foreign key, we can refer to some fields of the associated record in another table in the operation of a table, and the two tables are associated by the foreign key.
Similarly, the manager field in the department table is also a foreign key pointing to the employee table.
The primary key may consist of multiple fields, correspondingly, a foreign key may also have multiple fields, but it is relatively uncommon, and we won’t give an example here.
When there is a foreign key relationship between two tables, for example, a field in table A is a foreign key pointing to table B. We also need to know two terms: table B is the dimension table of table A, and table A is called the fact table. The relationship between the dimension table and the fact table is relative. When we care about the foreign key dept of the employee table, the department table is the dimension table of the employee table, while when we care about the foreign key manager of the department table, the employee table is the dimension table of the department table.
Dimension table and fact table are often used by programmers when discussing database operations. We don’t use this kind of technical vocabulary in daily data processing, but it’s better to know.
In the terminology of database, it is also said that foreign key association is many to one association, that is, multiple fact table records may be associated with the same dimension table record.
Foreign key is not an unfamiliar concept. Dimension table is the code table we often use. We list some frequently referenced attributes of things in a code table and give a code (i.e., primary key) to identify them. When referencing, we only use this code (i.e., foreign key), for more detailed information, we use this code to query the code table.
For example, the owner’s name, address,… and other information will be listed with the phone number, while there is only the phone number in the call record. The phone number is the primary key of the phone book. The phone number in the call record is the foreign key pointing to the phone book. The phone book is the dimension table of call record, and call record is the fact table. In the calculations of call records, it is often possible to use information related to phone numbers, such as querying the number of calls made in Beijing, which uses foreign keys to find the fields of associated records.
There are also others, such as bank accounts and bank transaction records, commodity information and trading records.
It is very common to use dimension table information in the operations of fact table. Why don’t we directly copy the dimension table fields to the fact table?
Readers who have experience with this code table will know the answer. There are many information contents in the dimension table. If they are copied into the fact table, the fact table will be very large and occupy a lot of storage space, resulting in low performance; Moreover, the dimension table is likely to change, such as department name and owner’s address. If they are copied into the fact table, once they change, the fact table will be updated, and the fact table is usually much larger, and it is very troublesome and inefficient. If it is an independent dimension table, you can always get the latest information by modifying the dimension table and temporarily fetching the dimension table fields during the operation of the fact table.
Having understood the concept, let’s continue. Now list the employee id (replaced by the id field without generating the name field) and the department name into a table:
| A | B | C | |
|---|---|---|---|
| … | … | ||
| 5 | =A3.new(eid,A2.find(dept).name:dept) | ||
This is very similar to the VLookup function in Excel. That’s how the code table is used.
However, it is obviously very troublesome to always use find()to write, and the efficiency is very poor to calculate every time. For example, if we want to list the id of the manager of the employee’s department, we have to write this find() twice.
| A | B | C | |
|---|---|---|---|
| … | … | ||
| 5 | =A3.new(eid,A2.find(dept).name:dept,A2.find(dept).manager) | ||
This is more like VLookup. Excel has to write VLookup twice to reference two columns of the associated table.
SPL obviously won’t fail to take this problem into consideration. This kind of routine operation for structured data can’t be so troublesome. SPL provides the switch() function to realize the association operation of foreign key:
| A | B | C | |
|---|---|---|---|
| … | … | ||
| 5 | >A3.switch(dept,A2) | ||
| 6 | =A3.new(eid,dept.name:dept,dept.manager) | ||
The switch() function will switch the foreign key field to the corresponding dimension table record. The A5 code is equivalent to executing the following statement:
A3.run(dept=A2.find(dept))
Before executing A5, look at the value of A3 (debugging function can be used). It is as follows, and the dept field is an integer:
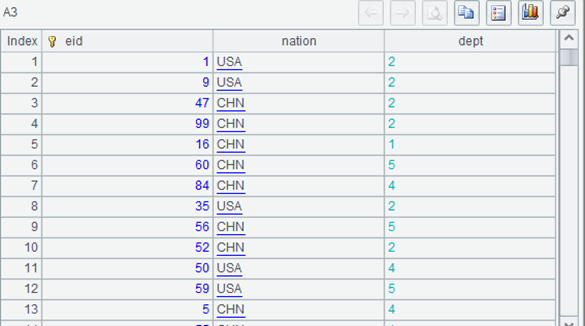
After execution, look at A3. The dept field still looks like an integer, but it changes color and is displayed on the left:
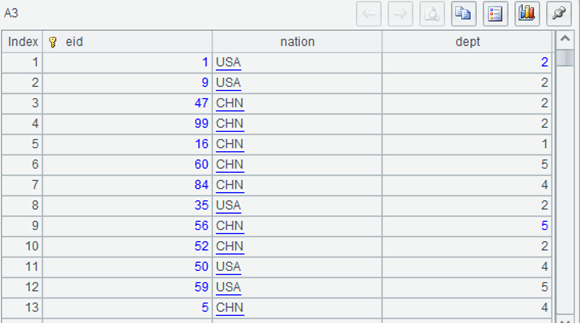
Double click the value of a dept, and the following result may appear in the value display area:

The value of dept field has become a record. Double clicking it will display the details of this record. The just displayed value with changed color is actually the primary key of this record.
Since it is a record, of course, its fields can be referenced, and dept.name and dept.manager in A6 can be calculated normally.
The function name switch() is used because it can also switch the field valued as a record back:
| A | B | C | |
|---|---|---|---|
| … | … | ||
| 5 | >A3.switch(dept,A2) | ||
| 6 | =A3.select(dept.name==“R&D”) | ||
| 7 | >A3.switch(dept) | ||
A5 switches the foreign key to the record of the dimension table, and A6 can use it to reference the field of the dimension table record. A7 switches the field now valued as the record back. A7 is equivalent to executing
A3.run(dept=dept.key())
However, switching back is rare.
After being processed by switch(), it seems that the records of the two tables are really connected. The field value of this table is the record of another table. You can reference the fields of another table through this field. This is much more convenient than VLookup.
Accordingly, the manager field in the department table is also a foreign key and can also be switched to the record in the personnel table.
For example, we want to count how many American employees have a Chinese manager:
| A | B | C | |
|---|---|---|---|
| … | … | ||
| 5 | >A3.switch(dept,A2) | >A2.switch(manager,A3) | |
| 6 | =A3.count(nation==“USA” && dept.manager.nation==“CHN”) | ||
Foreign key relationships may have multiple layers. In this case, it will be difficult to describe if we still use the find()method (Interested readers can also try to think about how to use VLookup to realize this multi-layer association in Excel). For the foreign key switched by the switch() function, the point operator can be vividly interpreted as “’s”. The dept.manager.nation in A6 can be interpreted as the department’s manager’s nationality of the current employee. You will not find it difficult even if there are many levels. Such a syntax is simple to write and easy to understand.
Generally, the value of the foreign key field must be within the range of the primary key value of the dimension table, but sometimes it may exceed the range. For example, before the department of a new employee is determined, the dept field is filled with 0, and there is no corresponding record in the department table.
| A | B | C | |
|---|---|---|---|
| … | … | ||
| 4 | =A2.run(A3(manager).dept=did) | >C1.to(90,).run(A3(~).dept=0) | |
| 5 | =A3.switch(dept,A2) | =A5.count(dept.name==null) | |
| 5 | =A3.switch@i(dept,A2) | =A5.count(dept.name==null) | |
| 5 | =A3.switch@d(dept,A2) | =A5.count(dept.name==null) | |
In the code B4 for generating data, we deliberately find some employees’ dept and fill it in as 0, and then we can observe the calculation results of the three A5. Note that it should be executed separately, not sequentially, because A3 will be changed after execution, and it is meaningless to continue to execute another A5.
When the switch() cannot find the dimension table record corresponding to the foreign key, it will fill in the foreign key as null, and the subsequent reference of its field will not report an error, but will return null, and the corresponding B5 will not be 0. The @i option will delete the fact table records that cannot find the record corresponding to the foreign key, ensuring that all the foreign keys of the fact table records after switch are correctly switched to dimension table records, and the corresponding B5 will return 0. While the @d option only retains the fact table records that cannot find the corresponding record of the foreign key, and cannot perform the foreign key switch, and the corresponding B5 will report an error.
Using foreign key to associate two data tables is often used to temporarily concatenate some fields of the dimension table to the fact table (that is, what VLookup does). In most cases, it is not intended to change the field of the fact table. Although the switch() function is convenient for association operation, it will change the foreign key field value of the original fact table. If we only want to append dimension table fields, we need to do another step of switching the foreign key that has become a record back to the foreign key, which is troublesome. Moreover, if we encounter the situation that there is no correspondence that we just mentioned, the foreign key will be filled in as null, and the information has been lost and cannot be switched back.
SPL provides the join() function to achieve this goal:
| A | B | C | |
|---|---|---|---|
| … | … | ||
| 4 | =A2.run(A3(manager).dept=did) | >C1.to(90,).run(A3(~).dept=0) | |
| 5 | =A3.join(dept,A2,name:deptname,manager:manager) | ||
A5 will add deptname and manager fields on the basis of table sequence A3, and fill in the employee’s department name and manager id respectively. The dept field will remain the same. If the corresponding dimension table record cannot be found, the newly added fields will be filled with null.
The join() function will generate a new table sequence, and the original A3 will not change.
The join() function can also support multi field primary keys and foreign keys. Because they are not common, we won’t give examples here. When you need to use them, you can consult the relevant SPL documents and understand the necessity of multi-layer parameters.
The switch() function does not support a dimension table with multi field primary keys. It can only switch single field foreign key.
It is very common to use a foreign key to find the corresponding record in the dimension table to reference some fields of the associated record. However, the business is complex. Sometimes the associated records cannot be determined simply by a foreign key, but need a condition related to the interval.
Go back to the personnel table often used in the previous chapter and create a BMI comparison table:
| A | B | |
|---|---|---|
| 1 | =100.new(string(~):name,if(rand()<0.5,“Male”,“Female”):sex,50+rand(50):weight,1.5+rand(40)/100:height) | |
| 2 | =A1.derive(weight/height/height:bmi) | |
| 3 | [null,20,25,30] | [UnderWeight,Normal,OverWeight,Fat] |
| 4 | =A3.new(~:low,~[1]:high,B3(#):type) | |
Now we want to add a field to the personnel table A2 with BMI information to list everyone’s weight type.
If the BMI comparison table A3 is used as a dimension table (with fields to be referenced), it has low and high fields to represent the BMI interval of a weight type, but does not have a field suitable for primary key (although low and high are unique). It also appears that there is no field in personnel table A2 that can act as a foreign key. However, it is obvious that there is an association between A2 and A4, and each record of A2 will correspond to a record of A4.
Interval association is also a common association. How should it be implemented?
We can of course simply use the select()function, just like using find() at the beginning of this section.
| A | B | |
|---|---|---|
| … | … | |
| 5 | =A2.derive(A4.select@1(low<=bmi && (!high || high>bmi)).type) | |
Here, we need to judge whether high is null (indicating the last segment), and low does not need to be judged, because SPL stipulates that null is the smallest, and null<=bmi will always get true.
In fact, interval association can also be understood as foreign key association. If we modify the BMI comparison table and add the BMI segment number calculated by pseg() function to the personnel table, we can see the foreign key relationship.
| A | B | |
|---|---|---|
| … | … | |
| 3 | [null,20,25,30] | [UnderWeight,Normal,OverWeight,Fat] |
| 4 | =A3.new(#:no,~:level,B3(#):type).keys(no) | |
| 5 | =A2.derive(A4.(level).pseg(bmi)+1:bmitype) | |
| 6 | =A5.switch(bmitype,A4) | |
The modified BMI comparison table A3 has a primary key and can be used as a dimension table. The bmitype field added in A5 is the foreign key pointing to A3. We can also use switch() to establish association.
Interval association is also a foreign key association in essence.
It’s really troublesome to create a foreign key for the personnel table. Actually, we wrote the code as above to help you understand that the concept of foreign key can be extended to this situation. In fact, we can directly spell the target field with pseg().
| A | B | |
|---|---|---|
| … | … | |
| 3 | [null,20,25,30] | [UnderWeight,Normal,OverWeight,Fat] |
| 4 | =A3.new(~:level,B3(#):type) | |
| 5 | =A2.derive(A4(A4.(level).to(2,).pseg(bmi)+1).type) | |
Generally, interval association processe does not generate a foreign key, but the concept of dimension table and fact table can still be used.
If, like this example, only the type field needs to be referenced, we will not even generate the comparison table, but directly use the sequence and pseg() to calculate and reference.
| A | B | |
|---|---|---|
| … | … | |
| 3 | [20,25,30] | [UnderWeight,Normal,OverWeight,Fat] |
| 4 | =A2.derive(B3(A3.pseg(bmi)+1):type) | |
Like all foreign key associations, interval association is also many to one relationship. Even if the dimension table is not generated, this association relationship still exists logically.
SPL Programming - Preface
SPL Programming - 10.1 [Association] Primary key
SPL Programming - 10.3 [Association] Merge
SPL Official Website 👉 https://www.scudata.com
SPL Feedback and Help 👉 https://www.reddit.com/r/esProcSPL
SPL Learning Material 👉 https://c.scudata.com
SPL Source Code and Package 👉 https://github.com/SPLWare/esProc
Discord 👉 https://discord.gg/2bkGwqTj
Youtube 👉 https://www.youtube.com/@esProc_SPL

