

SPL: Access HBase
HBase is the K-V database based on HDFS with similar concepts to the relational database: namespace, table, row, column, field value, primary key and so on.
However, HBase accesses data quite differently from the relational database: it does not support SQL but provides several operations such as get, scan, filter, etc. So it stores and retrieves data simply without any calculations of grouping, aggregation, sorting, sub-query and so on. The calculating engine SPL can easily access HBase data by encapsulating Java API and Rest API offered by HBase, making up for the computational disadvantages of HBase.
Create/close HBase connection
Similar to the JDBC connection of relational database, SPL also uses paired “create/close” to connect HBase.
hbase_open(hdfsUrl, zkUrl1,zkUrl2…), the first parameter is HDFS URL, and the parameter behind it is Zookeeper URL which can be multiple in number.
hbase_close(hbaseConn), hbaseConn is the HBase connection to be closed.
Code sample: A1 creates the connection, and A3 closes the connection after some other calculations in the middle steps.
A |
|
1 |
=hbase_open("hdfs://192.168.0.8", "192.168.0.8") |
2 |
…… |
3 |
=hbase_close(A1) |
Query single row of data
HBase uses the “get” and “scan” operations to query the single row and multiple rows of data respectively. Here we first introduce the SPL function of single row query:
hbase_get(hbaseConn,tableName,rowName,family1:column1:type1:alias1,family2:column2:type:alias2,... ; filter:f,timeRange:[t1,t2],timeStamp:t). In this function, the parameters are divided into two parts by the semicolon:
In the first part: hbase is the created connection; tableName is the name of the table; and rowName is the key values of the to-be-queried row. If the retrieved columns need to be specified, the parameters can be followed with many definitions of the retrieved columns. The full definition of each column is family:column:type:alias, respectively the name of column family, the name of column, the data type of the column (automatically loading strings from HBase into the data type specified here) and the alias of the column.
There are three parameters in the second part: “filter” is the filtering conditions; “timeRange” is the timestamp range of the data version to be queried; and “timeStamp” is the timestamp that explicitly specifies the certain data version to be queried. SPL offers many functions like hbase_filter() to package many “filters” of HBase, which is described in the specific section below. Please note that apart from “filter” that filters row, HBase also has “filters” that filter family, column and timestamp, therefore, “filter” may be useful when using row key value to “get” the single row of data.
Code sample:
A |
|
1 |
=hbase_open("hdfs://192.168.0.8", "192.168.0.8") |
2 |
=hbase_get(A1,"Orders","row1") |
3 |
=hbase_get(A1,"Orders","row1","datas:Amount":number:amt,"datas:OrderDate":od) |
4 |
=hbase_filter("ColumnCountGetFilter",2) |
5 |
=hbase_get(A1,"Orders","26";filter:A4) |
6 |
=hbase_get(A1,"Orders","26";timeStamp:1641785173116) |
7 |
=hbase_get(A1,"Orders","26";timeRange:[1641388111781,1642388111782]) |
8 |
=hbase_close(A1) |
With only the table name and row key value, other parameters are omitted, thus A2 queries the new version data of the whole row.

A3 queries the Amount and OrderDate columns of the “datas” family and specifies the data type as number and date. The columns in the result also have alias as amt and od:
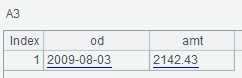
A4 generates a “filter” to retrieve the first two columns, and A5 uses the “filter” of A4 to query:
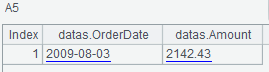
A6 queries this column with timestamp 1641785173116 (milliseconds) and finds out the field value updated by this timestamp if there exists one.

A7 queries the data with timestamp in [1641388111781,1642388111782).

Query multiple rows of data
Next we introduce the SPL function of the “scan” operation that queries multiple rows of data:
hbase_scan(hbaseConn,tableName,family1:column1:type1:alias1,family2:column2:type:alias2,... ; rowPrefix:x,startRow:startrow,stopRow:stoprow,filter:f,timeRange:[t1,t2],timeStamp:t). The parameters are similar to those in hbase_get function, which are divided into two parts by the semicolon. And here only the differences are described:
In the first part, the row key value “rowNmae” is no longer needed because the calculation is multi-row query.
There are three more parameters in the seconds part: rowPrefix is the prefix of the primary key of the to-be-queried row; startRow and stopRow are used to achieve the paging functionality, which retrieves the rows from startRow to stopRow out of all eligible data rows.
The result of hbase_scan function is an in-memory table sequence of SPL by default. However, @c option can be used to return a cursor if the result data are too large to be loaded in memory at a time. In this way, the data are fetched from the cursor batch by batch conveniently, which enables the function to calculate while fetching data.
Code sample:
A |
|
1 |
=hbase_open("hdfs://192.168.0.8", "192.168.0.8") |
2 |
=hbase_scan(A1,"Orders") |
3 |
=hbase_scan@c(A1,"Orders") |
4 |
=A3.fetch(3) |
5 |
=hbase_scan(A1,"Orders";rowPrefix:"row") |
6 |
=hbase_scan(A1,"Orders";startRow:2,stopRow:4) |
7 |
=hbase_close(A1) |
A2 queries the new version data of the whole table with only the table name parameter, and other parameters are all omitted.
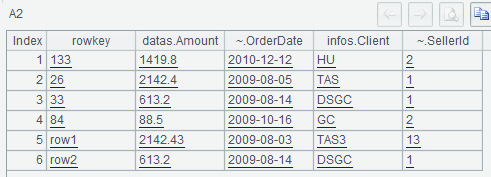
A3 uses @c option to get the SPL cursor of the query result, and A4 fetches 3 rows of data from the A3 cursor:
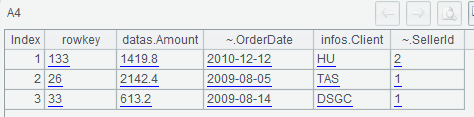
A5 queries the rows with “row” as the prefix of the row key value:
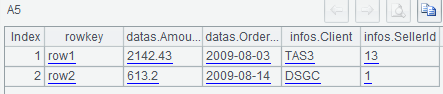
The return result of A6 query is the rows of [2,4), that is, the data from the 2nd (inclusive) to the 4th (exclusive) rows.

Filtering
HBase provides a variety of filters with the syntax of FilterName(argument1,argument2,...), and each filter has its own fixed name such as:
ColumnCountGetFilter(3);
FirstKeyOnlyFilter()
QualifierFilter(">=",'binary:xyz')
…
As we can see, the number and type of parameters vary from filter to filter. To be more specific, the parameter of ColumnCountGetFilter is the number of column(s) to be retrieved, i.e., the constant variable parameter of number type; FirstKeyOnlyFliter only retrieves the column of row key value and does not require parameters; FamilyFilter is to filter by the name of family, and the first parameter is comparison operator (>, >=, =, !=, <, <=), the second parameter is comparator (BinaryComparator, BinaryPrefixComparator, RegexStringComparator, SubStringComparator, etc.).
There are also situations where multiple filters are used in combination, for example, the combination relations include AND, OR, SKIP, WHILE and nestable parentheses.
SPL uses hbase_filter()to achieve filter, hbase_cmp() to achieve comparator, and hbase_filterlist() to achieve the combination of multiple filters.
Filter
hbase_filter(filterName,argument1,argument2,…), filterName is the name of filter, and dozens of other filters are introduced in detail on the “official website of HBase”. Different filters require different number and type of parameters, which can just follow after the name.
Code sample:
A |
|
1 |
=hbase_open("hdfs://192.168.0.8", "192.168.0.8") |
2 |
=hbase_filter("ColumnCountGetFilter",2) |
3 |
=hbase_scan(A1,"Orders";filter:A2) |
4 |
=hbase_filter("FirstKeyOnlyFilter") |
5 |
=hbase_scan(A1,"Orders";filter:A4) |
6 |
=hbase_filter("FamilyFilter","=",hbase_cmp@p("inf")) |
7 |
=hbase_scan(A1,"Orders";filter:A6) |
8 |
=hbase_close(A1) |
The ColumnCountGetFilter of A2 retrieves the first two columns, and A3 uses the filter of A2 to query:
The FirstKeyOnlyFilter of A4 only retrieves the column of row key value, and A5 uses the filter of A4 to query:

The FamilyFilter of A6 retrieves the column whose family name begins with “inf”, in which the comparator function hbase_cmp() used will be explained later. And A7 uses the filter of A6 to query:
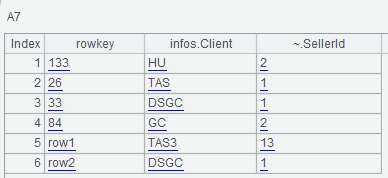
The parameters of these above three filters are more representative, and other filters are quite similar to them, so we won’t illustrate them one by one in this section.
Comparator
hbase_cmp(compareValue,comparatorArgument), compareValue is the threshold value to be compared, and some comparators require an additional control parameter comparatorArgument. As for using which comparator, the choice depends on the option in the function, and BinaryComparator is used by default when there is no option;
hbase_cmp@p(compareValue), the @p option indicates to use the BinaryPrefixComparator.
hbase_cmp@s(compareValue), the @s option indicates to use the SubstringComparator.
hbase_cmp@l(compareValue), the @l option indicates to use the LongComparator.
hbase_cmp@d(compareValue), the @d option indicates to use the BigDecimalComparator.
hbase_cmp@r(compareValue,comparatorArgument), the @r option indicates to use the RegexStringComparator, and the control parameter comparatorArgument can include i, m, d, u, q, x, l, and c. i means the parameters are case-insensitive; m means multiple rows can be matched; d means “.” can represent any character; u means Unicode characters are case-insensitive; q means to match the fully regular parsing function; x means the line break is unix-style; l means plain text mode; and c means the comment mode.
For example, hbase_cmp@r("ab.c\nd","idx") means that the parameters are case-insensitive, that “.” represents any characters; and that line break is unix-style when matching the regular expression.
In hbase_cmp@b(compareValue,,comparatorArgument), @b option means to use BitComparator. And this expression is about bit-wise comparison, so the ComparatorArgument parameter can be “and”, “or”, and “xor”, indicating Bitwise and, Bitwise or and Bitwise exclusive or respectively.
In hbase_cmp@c(compareValue,comparatorArgument), @c option means to use BinaryComponentComparator; comparatorArgument is an integer value, indicating the offset when matching bytes.
For example, hbase_cmp@r("abc",10) means to match “abc” starting from the 10th byte of the matched value.
From the above code samples in this section, the control parameters of the filters may use these comparators.
Combined filtering
(filter1 AND filter2) OR (filter3 AND filter4)
As stated above, when combining several conditions with “and” or “or”, we can use hbase_filterlist(filterA, filterB, …) in SPL, in which the “filter” of the parameter can be either hbase_filter()or nested hbase_filterlist(). In A6 of the following example, the two inner hbase_filterlist()s combine filter1-filter4 in pairs with AND, and the @o option of the outermost hbase_filterlist()indicates to combine the two inner hbase_filterlist()s with OR.
A |
|
1 |
=hbase_open("hdfs://192.168.0.8", "192.168.0.8") |
2 |
>filter1=hbase_filter("FamilyFilter","=",hbase_cmp@p("datas")) |
3 |
>filter2=hbase_filter("ColumnPrefixFilter","Amo") |
4 |
>filter3=hbase_filter("FamilyFilter","=",hbase_cmp@p("infos")) |
5 |
>filter4=hbase_filter("ColumnPrefixFilter","Cli") |
6 |
=hbase_listfilter@o(hbase_listfilter(filter1,filter2), hbase_listfilter(filter3,filter4)) |
7 |
=hbase_scan(A1,"Orders";filter:A6) |
8 |
=hbase_close(A1) |
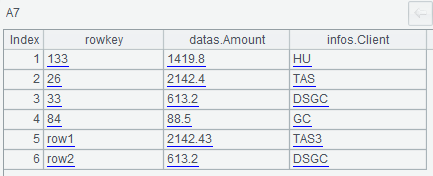
The query condition is (family name equals to “datas AND” and the column name is prefixed with “Amo”) OR (family name equals to “infoss AND” and the column name is prefixed with “Cli”), and A7 queries to get the results that match the condition:
General function of RestAPI
The RestAPI of HBase can obtain the cluster information, add, delete, and change “namespace” and “table”, use “get” and “scan” to query data, and use “put” to add, delete, and change data. SPL provides the following function to achieve RestAPI:
hbase_rest(restUrl, method, content; httpHeader1, httpHeader2, …), the first parameter rest is the url address; the second one is HTTP method whose value may be GET/PUT/POST/DELETE; the third one is the content submitted by the HTTP request, but some operations may submit no content, then this parameter can be omitted. There are many HTTP headers behind the semicolon, and can be omitted as well if there is none of them. The HTTP request of each Rest, which “method” to adopt, what content to submit, what HTTP header to set, all these above details are illustrated on the official website “Rest Documentation”.
To call the hbase_rest() function will perform a full HTTP request independently without creating an HBase connection in advance.
Code sample:
A |
|
1 |
=hbase_rest("http://127.0.0.1:3456/namespaces","GET") |
2 |
=A1.Content.split("\n") |
3 |
'<?xml version="1.0"encoding="UTF-8"?> <TableSchema name="Orders"> <ColumnSchema name="infos" /> <ColumnSchema name="datas" /> </TableSchema> |
4 |
=hbase_rest("http://127.0.0.1:3456/Orders/schema","PUT",A3;"Content-Type: text/xml","Accept: text/xml") |
5 |
=hbase_rest("http://127.0.0.1:3456/namespaces/default/tables","GET") |
6 |
=A5.Content.split("\n") |
7 |
=$[<?xml version="1.0" encoding="UTF-8" standalone="yes"?><CellSet><Row key=${"\""+base64("row1":"UTF-8")+"\""}><Cell column=${"\""+base64("infos:Client":"UTF-8")+"\""}>${base64("TAS":"UTF-8")}</Cell> ...... </Row></CellSet>] |
8 |
=hbase_rest("http://127.0.0.1:3456/Orders/fakerow","PUT",string(A7);"Content-Type: text/xml","Accept: text/xml") |
9 |
=hbase_rest("http://127.0.0.1:3456/Orders/row1","GET";"Accept:text/xml") |
10 |
=xml@s(A9.Content) |
11 |
=A10.CellSet.Row.derive(base64(Cell,"UTF-8"):CellValue,base64(column,"UTF-8"):columnName) |
12 |
=hbase_rest("http://127.0.0.1:3456/Orders/scanner/","PUT","<Scanner batch=\"1\"/>";"Content-Type:text/xml","Accept:text/xml") |
13 |
=hbase_rest(A12.Location,"GET") |
The hbase_rest() function returns all the information responded from HTTP. Among all the “rest” operations, most of the important information is in the Content of HTTP, but it may also be in the Message, or the later Location. For example, A1 gets all the “namespace”:

In A1, the multiple return “namespace” is a string which can be easier to observe after being converted into a sequence using the split function in A2.

The xml in A3 defines a table with two families, respectively “infos” and “datas”; A4 uses the hbase_rest() function to submit the table definition of A3, and the result is “Created”, meaning the table is successfully created:

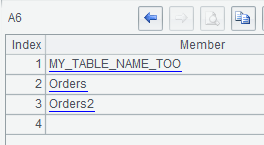
A5 queries the table under “default”namespace:

A6 observes the Content in A5 result and the new Orders table created before is already shown:
A7 defines the data (in xml format) to be inserted in Orders table whose column names and data are required to be encoded in base64. Use the base64() function of SPL to encode the required part, and the xml string with base64 code can be seen after execution:

A8 uses the hbase_rest() function to submit the table data in A7 and the execution result is “OK”:

A9 uses the hbase_rest() function to execute the “GET” operation of HBase to query the data whose row key value is row1, and the result is:

The result of A9 is in xml format which is difficult to check and calculate, and A10 uses the xml() function of SPL to convert it into a nested table sequence:

The row data of A10 are in table sequence CellSet.Row, but its column value (Cell field) and column name (column field) are both encoded in base64. A11 uses the derive()function to calculate two new fields, CellValue and columnName, and gets the values of the new columns using base64() function to decode base64.
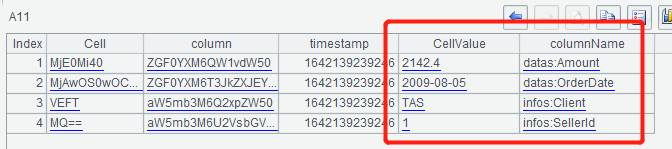
A12 creates a SCAN operation of HBase, and the url of the return Location contains SCAN ID:

A13 uses the SCAN ID of A12 to retrieve the query data. The SCAN operation in A12 specifies batch=1, so one piece of data is retrieved at a time:

SPL Official Website 👉 https://www.scudata.com
SPL Feedback and Help 👉 https://www.reddit.com/r/esProcSPL
SPL Learning Material 👉 https://c.scudata.com
SPL Source Code and Package 👉 https://github.com/SPLWare/esProc
Discord 👉 https://discord.gg/2bkGwqTj
Youtube 👉 https://www.youtube.com/@esProc_SPL


Chinese version