

Why ETL Becomes ELT or Even LET?
ETL, the abbreviation of extract, transform and load, is the process of moving data from one or more sources to a target system through extraction, transformation and loading. A regular ETL process should stick to the order of extracting data, transforming data and then loading data into the target system (usually a database). The data finally loaded into the database should be the desired result. However, this reasonable order is often changed in the actual execution of the process. ETL becomes ELT or LET, where the source data is loaded to the target database before it is transformed or even extracted.
The source data may come from different sources, such as database, file and web, and has different levels of data quality. Both E and T are computation-intensive, and among a variety of data sources, databases have the best computing ability while others have a little or none. Loading source data into the database has become the first and convenient choice for accomplishing the computations. This leads to LET. Sometimes data originates from multiple databases. Cross-database data extraction and transformation is not as convenient as loading data to the target database for further handling. This also results in LET, or ELT.
But ELT/LET can bring about a series of problems.
One aspect is the time cost increase. It is already extremely time-consuming to load a huge amount of non-extracted and non-transformed original (or useless) data into the database, where computing resources are limited. Then it will be sure to take a long time to handle the extra E and T computations in the database, adding more time to the whole process. ETL is time-limited. It is generally performed during supposedly idle time per day, which is the commonly known ETL time window (from 22 o’clock to 5 o’clock in the next morning, for instance). If the ETL job cannot be finished within the specified period, the next day’s business will be affected. The time window becomes narrow if ETL process is too long, and business will be damaged.
The other is the database load increase. Storing a massive amount of non-extracted and non-transformed original data will take up too much database space, resulting in heavy database load and thus scalability pressure. To load the multilevel JSON or XML data much used by today’s applications, multiple related data tables need to be created in the database, further exacerbating the database capacity issue. As computations increase, database resources decrease and the time window becomes narrower. This gets the system caught in a vicious circle.
But why do we need to load data to the database before we can perform E and T? As previously mentioned, it is because non-database data sources have poor computing abilities and people want to make use of databases’ strong ability by first loading data into them. If we can provide satisfactory outside-database computing ability, we do not need to do the data loading anymore and the reasonable ETL process can be restored.
The open-source esProc SPL is an ideal tool for achieving outside-database computing ability.
SPL is an open-source, stand-alone data computing engine. It has a database-independent computational capability for connecting to and accessing various data sources and performing data processing. Its rich set of class libraries, agile syntax and support of procedural programming make it convenient to handle complex data computing tasks in the original order of the ETL process. It performs extraction (E) and transformation (T) outside the database and then loads the prepared data to the target database, completing the true ETL.
Outside-database computing engine enables true ETL
Support of diverse data sources and mixed computations
SPL can connect to and access various data sources, empowering each source – no matter it has or hasn’t any computing capacity – to deal with data extraction and transformation conveniently and efficiently through its methods and syntax.

One specific feature of SPL is its ability to achieve mixed computations between diverse data sources. It extracts data from different sources, transforms it and loads it into the database, without the need of database computing ability anymore. It provides convenient and efficient support particularly for multilevel data like JSON and XML. One simple function is enough for parsing them.
Here’s a simple example. To perform a specific operation on data coming from a JSON file and a database table:
A |
||
1 |
=json(file("/data/EO.json").read()) |
Parse JSON data |
2 |
=A1.conj(Orders) |
|
3 |
=A2.select(orderdate>=date(now())) |
Get data of the current date |
4 |
=connect(“sourcedb”).query@x(“select ID,Name,Area from Client”) |
Retrieve data from the database |
5 |
=join(A3:o,Client;A4:c,ID) |
Perform a join between JSON data and database data |
6 |
=A5.new(o.orderID:orderID,…) |
|
7 |
=connect(“targetdb”).update(A6,orders) |
Load result data to the target database |
Excellent computational ability and procedural control
SPL offers specialized structured data objects and numerous operations on them. It gives direct support for basic computations such as grouping & aggregation, loop and branch, sorting, filtering, and set-operations, as well as for complex computations like getting positions, order-based ranking and irregular grouping.
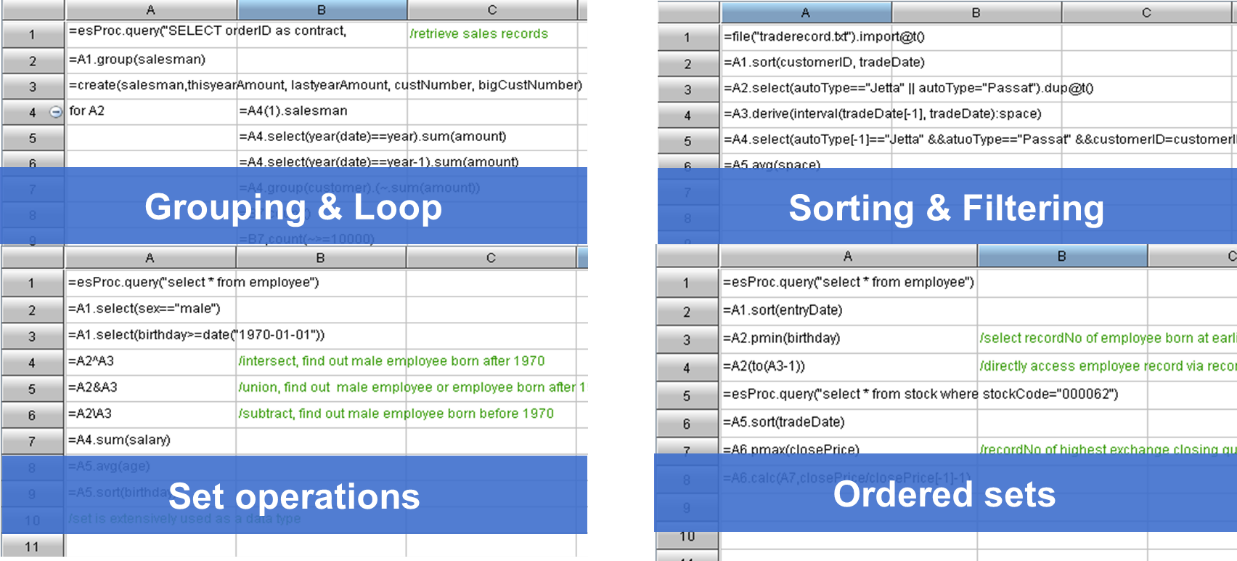
SPL supports cursor specifically for big data computing. It can handle a large amount of data that exceeds the memory capacity through the cursor using almost the same way of computing data that can fit into the memory. To retrieve data from a file and group and summarize it using the cursor, for instance:
=file(“persons.txt”).cursor@t(sex,age).groups(sex;avg(age))
Below is the code for retrieving memory data:
=file(“persons.txt”).import@t(sex,age).groups(sex;avg(age))
In addition, SPL supports procedural programming that enables coding a computation step by step according to familiar ways of thinking. This makes it suitable for handling complex ETL computations that are conventionally achieved with stored procedures in databases. The outside-database SPL computations are flexible and high-performance and as effective as stored procedures while imposing no workload on databases. The “outside-database stored procedure” can be the ideal replacement for the conventional stored procedure. Reducing database load as much as possible is what SPL computations are good at. Both E and T computations traditionally handled in databases are now performed outside databases. This avoids consuming database computing resources, and storing a large volume of non-extracted and non-transformed original data, which helps reduce space usage. With SPL, there will be no such problems as database resource and capacity shortages.
SPL has more agile syntax than both SQL and Java. It achieves E and T computations, especially complex computations, with more concise algorithms and much shorter code. This considerably increases development efficiency. We have a case where SPL is used to perform ETL to implement vehicle insurance policy for an insurance company. SPL achieves the computation with less than 500 cells of code (in SPL grid-style code) while it is originally handled with 2000 lines of code using the stored procedure. The workload is reduced by over one-third (See Open-source SPL optimizes batch operating of an insurance company from 2 hours to 17 minutes).
From the angle of technology stack, SPL uses a consistent style of syntax that enables a uniform computational ability for diverse data sources during ETL handling. Besides the universal technology approach, SPL enables convenient to develop and maintain programs. The cost of learning is reduced as programmers do not need to know different ways of handling data coming from diverse sources. One important thing is that the uniform technology approach makes SPL code very easy to migrate. Programmers only need to change the data retrieval code when trying to switch to a different source during ETL computations, while maintaining the essential computing logic.
Sufficient ETL time window thanks to high-performance computations
It is convenient to retrieve data from a source with parallel processing in SPL, giving full play to the advantages of multiple CPUs for speeding up data retrieval and computations. To retrieve data with multiple threads, for instance:
A |
B |
|
1 |
fork to(n=12) |
=connect("sourcedb") |
2 |
=B1.query@x("SELECT * FROM ORDERS WHERE MOD(ORDERID,?)=?", n, A3-1) |
|
3 |
=A1.conj() |
You can also use multithreaded processing to retrieve data from a huge file:
=file(“orders.txt”).cursor@tm(area,amount;4)
SPL offers @m option to create a parallel multicursor, automatically handles the parallel processing and summarizes the result set. Many SPL functions, such as A.select()for filtering and A.sort() for sorting, support working with @m option to enable an automated parallel processing.
An ETL process often involves data persistence – by this we mean storage – of intermediate results or the final result. SPL provides two binary storage formats. They store data types to avoid data parsing and increase efficiency, use reasonable and appropriate compression mechanisms to balance CPU load and disk access time, support both row-wise storage and column-wise storage to cater to more diverse scenarios, and offers unique double increment segmentation technique to implement segmentation on an append-able single file for facilitating parallel processing. These high-performance storage mechanisms are basic guarantees of computing performance – the right storage mechanism and efficient algorithm are cornerstones of high-performance computing, as we know.
SPL supplies a large number of high-performance algorithms. In the previously mentioned article, Open-source SPL optimizes batch operating of an insurance company from 2 hours to 17 minutes, SPL not only reduces code amount to the original’s one-third, but shortens computing time from 2 hours to 17 minutes using its exclusive multi-purpose traversal technique. The technique enables multiple operations during one traversal of a huge data table, effectively decreasing external storage accesses. RDBs, however, cannot do the same thing in SQL. They need multiple traversals for multiple operations. In the above article, there is a computation involving three joins and aggregates on one large table. SQL will traverse the table three times, but SPL needs one traversal only. That’s why SPL can enhance performance significantly.
Often there are joins between huge primary table and subtable during an ETL process, like the one between the Orders table and the OrdersDetail table. For such a join, tables are associated through primary keys (or the key in the primary table and part of the key in the subtable) and they have a one-to-many relationship. If we order tables by their primary keys in advance, we can use order-based merge algorithm to perform the join. Compared with the traditional HASH JOIN algorithm, order-based merge can reduce the computation’s degree of complexity from O(N*M) to O(M+N) and greatly boost performance. Databases are based on the theory of unordered sets and it is hard for SQL to exploit ordered data to increase performance. In the same article, SPL remarkably improves the performance a primary-sub table join computation using the order-based merge algorithm.
So, using the computing expert SPL as the ET engine to separate and decouple the data computing part from both the source end and the target end during the ETL process enables highly flexible and easy to migrate code and moderate pressure on both source and target. The conveniences of outside-database computations help achieve the ETL process in its original order. SPL also ensures efficient ETL processes with its high-performance storage formats and algorithms and parallel processing techniques, completing as many ETL tasks as possible within a limited time window.
SPL Official Website 👉 https://www.scudata.com
SPL Feedback and Help 👉 https://www.reddit.com/r/esProcSPL
SPL Learning Material 👉 https://c.scudata.com
SPL Source Code and Package 👉 https://github.com/SPLWare/esProc
Discord 👉 https://discord.gg/2bkGwqTj
Youtube 👉 https://www.youtube.com/@esProc_SPL


Chinese version