

Create Easy and Efficient T+0 Queries with Open-source SPL
T+0 problems
T+0 queries refer to querying and summarizing data, including the latest data, in real-time. They can be easily handled directly based on the production database when the amount of involved data is relatively small. Yet, when data accumulates to a certain extent, a query on large tables in the production database will consume a lot of database resources, and when too much is used up, even business transactions are affected. This is unacceptable because transactions are the highest priority. In an effort to prevent transactions from being affected by query processing, the huge amount of historical data for analytical queries is usually moved out of the production database and stored and queried in a separate database. This is what we call the separation of cold data and hot data.
The separation results in T+0 problems. When data is stored in two separate databases, querying whole data involves cross-database queries. As we know, most production databases used for transactions are RDBs that support transaction consistency, but the specialized analytical database or data platform is preferred for storing the separated cold data (which is huge in size and remains static). Even if an RDB is used to store the cold data, it is probably of a different type. This also involves queries between different types of databases or data sources. Unfortunately, all cross-database/data-source technologies at present have their weaknesses.
Generally, databases’ own cross-database/data-source features (such as Oracle’s DBLink, MySQL’s FEDERATED and MSSQL’s Linked Server) retrieve data from the remote database to the local machine and perform most of the computation, including the filtering operation, locally. The whole process is extremely inefficient. The method also has other disadvantages, such as unstable data transmission, non-support of big object handling and low scalability.
Another way is the “almighty” hardcoding in a high-level language. It is flexible yet extremely difficult to use, especially when most of today’s applications use Java to write programs. The high-level language does not have enough class libraries for computing structured data and it is hard to handle computations after the cross-database query, except simple list style queries. All queries involving analysis and summarization are ridiculously complicated to achieve.
Actually, it is not that hard to solve T+0 query problems produced by separating cold data from hot data. A computing engine possessing certain abilities is enough. Such an engine should be able to connect to and access diverse data sources; have database-independent, all-around computational ability for data computing after data is extracted from different sources; have ways to tap database’s computing resources by making use of the database/data source’s strengths; provide simplistic data processing interface; and have at least satisfactory performance.
SPL as solution
Open-source SPL is the data computing engine we wish for. It provides a wealth of functions for structured data computations, has a complete set of computational abilities, supports mixed computations between diverse sources, and can connect to the production database storing the hot data and the historical database storing cold data at the same time for performing T+0 queries on the full data.
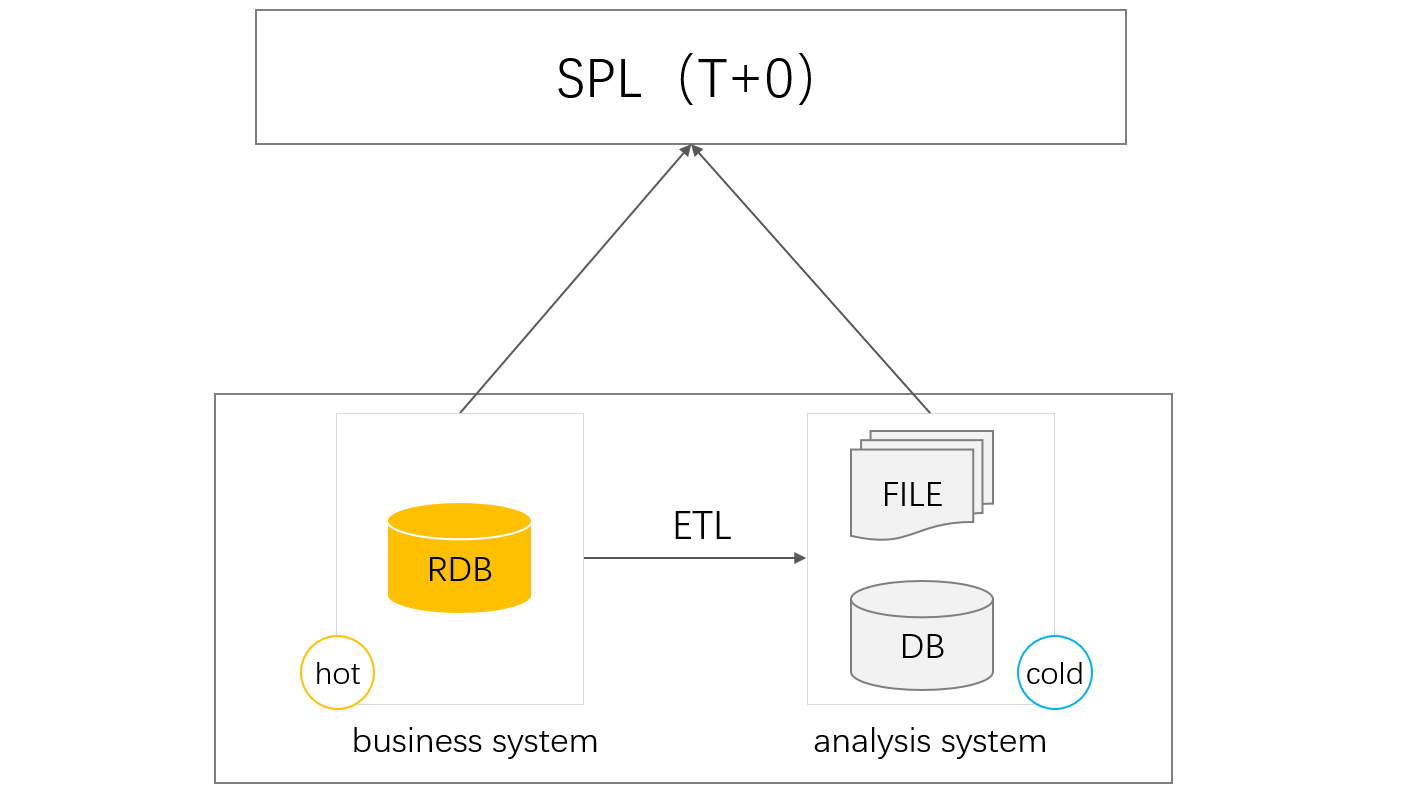
With independent and all-around computational capability, SPL can retrieve data from different databases respectively, making it really suitable for handling scenarios involving different types of databases, and determining where the computation will be performed – in the database or in the outside-database SPL – as needed. In terms of implementation, SPL can greatly simplify complex computing logics in T+0 queries and speed up development with its agile syntax and procedural programming. Also, it is interpreted execution and supports hot swap. Furthermore, SPL can deal with ETL tasks on separated cold and hot data using its powerful computing capacity.
SPL offers proprietary high-performance binary storage format. With scenarios having high demand for performance, you can store the historical cold data in files and use SPL’s high-performance algorithms and convenient parallel processing techniques to increase query efficiency. SPL encapsulates standard application interfaces (JDBC, ODBC and RESTful) for integration and invocation by an application. The SPL code can also be embedded into an application, conveniently enabling the latter to have the ability to handle T+0 queries and complex data processing tasks. SPL makes it easy to cater to the needs of today’s application framework where computation and storage are separated.
Mixed computations between cold and hot data
It is simple to handle a T+0 query on cold and hot data stored in separately databases. Here’s an example:
A |
B |
|
1 |
=[[connect@l("oracle"),"ORACLE"],[connect@l("mysql"),"MYSQL"]] |
|
2 |
=SQL="select month(orderdate) ordermonth,sellerid,sum(amount) samount,count(amount) camount from sales group by month(orderdate),sellerid" |
|
3 |
fork A1 |
=SQL.sqltranslate(A3(2)) |
4 |
=A3(1).query(B3) |
|
5 |
=A3.conj().groups(ordermonth,sellerid;sum(samount):totalamount,sum(camount):totalcount) |
For this example, Oracle is used as the production database to store currently hot data and MySQL is used to store the historical cold data. When a standard SQL (A2) is passed in from the frontend, SPL translates it to the syntax of corresponding database using its sqltranslate function (B3) and sends it to the database to query (B4), and finally, merge intermediate result sets and perform the desired aggregates (A5). The SPL code tries to become more efficient by using multithreaded processing (A3) to execute the SQL with two threads.
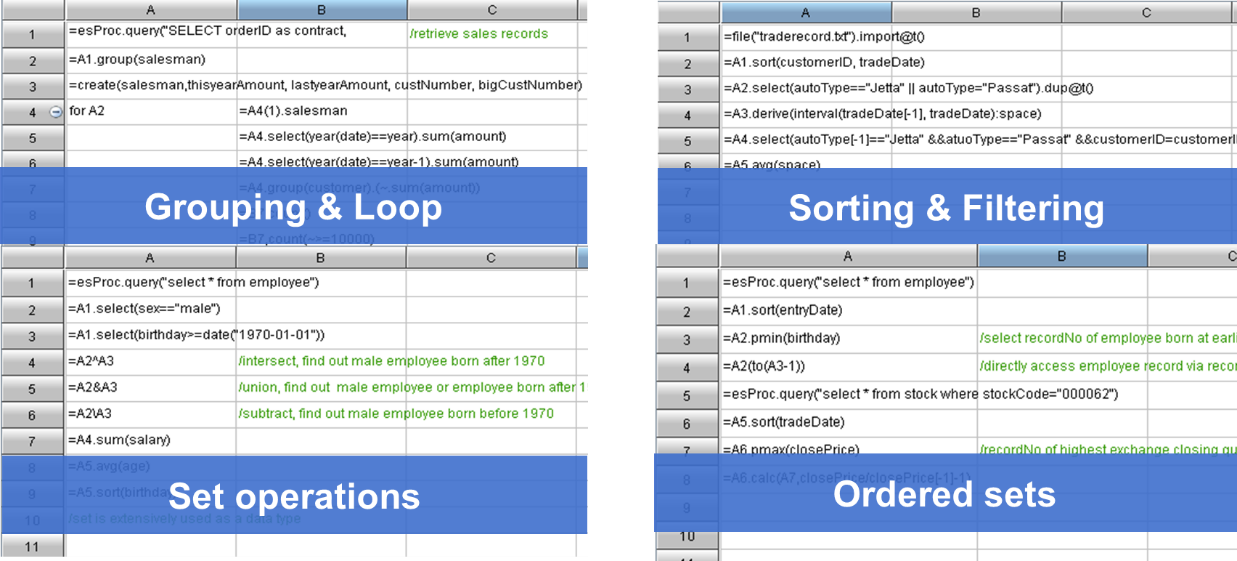
SPL not only accomplishes the cross-database query between two databases but uses the SQL translation method for the convenience of the frontend application and has the ability to handle subsequent computations, grouping and aggregation in this example, after merging the result sets of querying two databases. SPL also offers specialized structured data objects and numerous operations on them. It gives direct and convenient support for basic computations such as grouping & aggregation, loop and branch, sorting, filtering, and set-operations, as well as for complex computations like getting positions, order-based ranking and irregular grouping.
Besides RDBs, SPL supports other sources like NoSQL and Hadoop, too. Its diverse source mixed computing ability lets it achieve T+0 queries on mixed data sources. To perform a query on both MongoDB and MySQL, for instance:
A |
|
1 |
=mongo_open("mongodb://127.0.0.1:27017/mongo") |
2 |
=mongo_shell(A1,"Orders.find()") |
3 |
=A2.new(Orders.OrderID:orderid,Orders.Client:client,Dept:dept,Amount:amount).fetch() |
4 |
=mongo_close(A1) |
5 |
=mysql.query@x(“select ordered,client,dept,amount from orders”) |
6 |
=[A3,A5].conj() |
7 |
…Subsequent computations |
With its remarkable computing ability, SPL can handle ETL tasks and transfer hot data to the historical database, often accompanied by certain conversion operations. For instance, sometimes we need to convert certain code fields to another type of code according to a specific reference table (in an effort to use a consistent code rule, increase performance by tidying up data types, etc.). But the reference table usually isn’t stored in the production database, so you cannot perform the computation directly within the database. Here we need to face the cross-data-source computation.
A |
|
1 |
>source=connect@l(“oracle”),target=connect@l(“mysql”) |
2 |
=source.cursor(“select * from orders”) |
3 |
=target.query(“select oldCode,newCode from codeComp”).keys@i(oldcode) |
4 |
=A2.run(pid=A3.find(pid).newcode) |
5 |
>target.execute(A2,"insert into orders values(?,?,?,?,?)",#1,#2,#3,#4,#5) |
6 |
>source.close(),target.close() |
High performance
Probably the size of historical cold data is massive. Using an RDB to store it is liable to be affected by many factors, like resource capacity, and, moreover, data retrieval is extremely slow. File storage, however, has the edge. It boasts faster data retrieval, can use multiple mechanisms like compression and parallel processing to increase performance, and is not as vulnerable to resource capacity as databases are. Yet, the open text format is inefficient (because it isn’t compressed and data parsing for it is slow), and a binary file is mostly used. The biggest problem about file storage is that files do not have computing ability, and hardcoding is difficult. Databases, in this aspect, can handle data processing with SQL conveniently.
All problems can be solved with SPL. SPL provides two high-performance binary storage formats – bin file and composite table. Together with SPL’s independent computational capability, this enables high-efficient T+0 queries through mixed computations directly on file and database. Take the previous case, we can use a SPL file to store historical cold data and perform a mixed query on it and the hot data in the production database.
A |
|
1 |
=connect("oracle") |
2 |
=A1.query@x("select sellerid, sum(amount) totalamount, count(amount) countamount,max(amount) maxamount,min(amount) minamount from sales group by sellerid") |
3 |
=file(“his_sales.btx”).cursor@b() |
4 |
=A3.groups(sellerid;sum(amount):totalamount,count(amount):countamount,max(amount):maxamount,min(amount):minamount) |
5 |
=[A3,A4].conj().groups(sellerid;sum(totalamount):totalamount,sum(countamount):countamount,max(maxamount):maxamount,min(minamount):minamount) |
Store the historical data in files and perform a mixed query between file and production database. SPL also supports using cursor to handle big data computing scenarios where the size of historical data to be queried is huge. A4 groups and summarizes A3’s file cursor. A5 merges result sets of A2 and A4 and performs grouping & aggregation on the merged set. The code uses SPL binary bin file (btx) to obtain higher efficiency. A bin file is compressed (to occupy less space and allow fast retrieval), stores data types (to enable faster retrieval without parsing), and employs the double increment segmentation technique to divide an append-able file and facilitate parallel processing so that high computing performance can be ensured.
The composite table is the other high-efficiency storage format SPL provides. It displays great advantage in handling scenarios where only a very small number of columns (fields) is involved. A composite table is equipped with the minmax index and supports double increment segmentation technique, letting computations to both enjoy the advantages of column-wise storage and be more easily parallelly processed to have better performance.
SPL offers high-performance algorithms for a variety of computations, such as getting TopN. It treats calculating TopN as a kind of aggregate operation, which successfully transforms the highly complex full sorting to the low-complexity aggregate operation while extending the field of application.
A |
||
1 |
=file(“data.ctx”).create().cursor() |
|
2 |
=A1.groups(;top(10,amount)) |
Get records of orders whose amounts rank in top 10 |
3 |
=A1.groups(area;top(10,amount)) |
Get records of orders whose amounts rank in top 10 in each area |
The SPL statements do not involve any sort-related keywords and will not trigger a full sorting. The statement for getting top N from a whole set and that from a subset are basically the same and both have high performance. SPL boasts many more such high-performance algorithms.
It is easy to implement parallel processing in SPL and fully bring into play the advantage of multiple CPUs. Many SPL functions, like file retrieval, filtering and sorting, support the parallel processing mechanism. It is simple and convenient for them to implement the multithreaded processing only by adding one @m option.
Ease of integration
SPL encapsulates the standard JDBC driver and ODBC driver to allow invocation by other applications. For Java applications specifically, the SPL code can be embedded into them for execution. This enables data-source-independent implementation of T+0 queries at the application side, completely decoupling the application and the data source and creating easy to migrate and scalable code.
Below is an example of invoking SPL code through JDBC:
Class.forName("com.esproc.jdbc.InternalDriver");
Connection conn =DriverManager.getConnection("jdbc:esproc:local://");
Statement st = connection.();
CallableStatement st = conn.prepareCall("{call splscript(?, ?)}");
st.setObject(1, 3000);
st.setObject(2, 5000);
ResultSet result=st.execute();
SPL is interpreted execution and naturally support hot swap. Data computing logics written in SPL and their modification take effects in real-time without the need of restarting the application, making programs’ development, operation and maintenance convenient and efficient.
Compared with other technologies of implementing T+0 queries, SPL is more convenient thanks to its independent, powerful computational capability and cross-data-source mixed computing feature; more capable of achieving high query efficiency with its high-performance storage formats and algorithms; and has more ease of integration to empower the application side to have those strengths. In short, SPL is the best and most ideal tool for implementing T+0 queries.
SPL Official Website 👉 https://www.scudata.com
SPL Feedback and Help 👉 https://www.reddit.com/r/esProcSPL
SPL Learning Material 👉 https://c.scudata.com
SPL Source Code and Package 👉 https://github.com/SPLWare/esProc
Discord 👉 https://discord.gg/2bkGwqTj
Youtube 👉 https://www.youtube.com/@esProc_SPL


Chinese version