

DCM: A New Member of Middleware Family
What is DCM?
Contemporary applications feed on data. Data computations are everywhere – reporting statistics, data analysis and business transaction to name a few. At present, relational databases and other related technologies constitute the mainstream data processing capabilities. Hardcoding in high-level languages like Java can achieve all computations, but it is not nearly as convenient as SQL-based-databases. The latter is still the backbone of today’s data processing systems.
On the other hand, progress in information technology is giving rise to new concepts and frameworks such as the separation between storage and computation, microservices, moving computations frontward and edge computing. The heavy and closed databases seem to become increasingly inconvenient in handling the new scenarios. Databases require loading data to them for further computations. The problem is that data loading presents inefficiencies, large resource consumption, and non-real-time-ness when diverse data sources are involved. Sometimes, data just needs to be used temporarily and storing it permanently in the database outweighs the advantages. Databases are also hard to embed for scenarios like microservices and edge computing that need to deploy the computing capability frontward at the application.
All those problems can be solved if there is a data computing & processing technology that is database-independent, has open computational capability and can be embedded and integrated in applications. Such a technology is called Data Computing Middleware (abbreviated as DCM). DCM is used in an extremely wide range of scenarios, and plays important roles in many aspects, such as application development optimization, microservice implementation, replacement of stored procedure, decoupling from databases, ETL facilitation, handling of diverse data sources and BI data preparation. It can work in almost all scenarios involving data exchange between applications to optimize framework and increase development and computing efficiencies.
What does DCM do?
Application development optimization
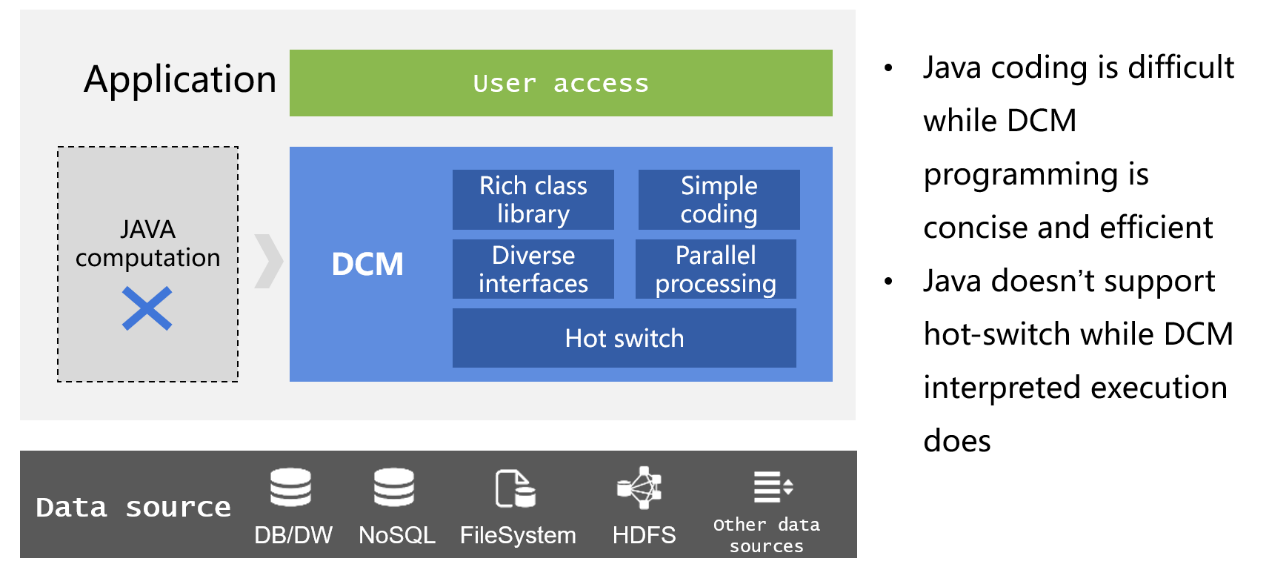
Coding is the only way to implement data processing logics in an application. Yet coding in the native Java is usually difficult because the high-level language lacks necessary class libraries for structured data computations. No noticeable improvements can be made even Java’s new additions Stream and Kotlin are used to do the job. The ORM technique helps to make the coding easier, but it is not convenient in handling set-oriented computations, produces too complicated code for database read/write and has difficulty achieving complex computations due to the absence of specialized structured data types. These ORM weaknesses often lead to little improvement, sometimes even big decrease, in development efficiency for business logic implementation. Besides, these coding tools can cause faulty framework. Business logics implemented in Java require being deployed together with the main application, which results in tight coupling, and are complicated to administer and maintain because of non-support of hot deployment.
DCMs have features of agile computing, ease of integration and hot swap. If we can use a DCM, instead of Java, to implement data processing logics in an application, we will get rid of all the above problems. This means better efficiency, optimized framework, decoupled computing module and hot-deploying ability.
Computation of diverse data
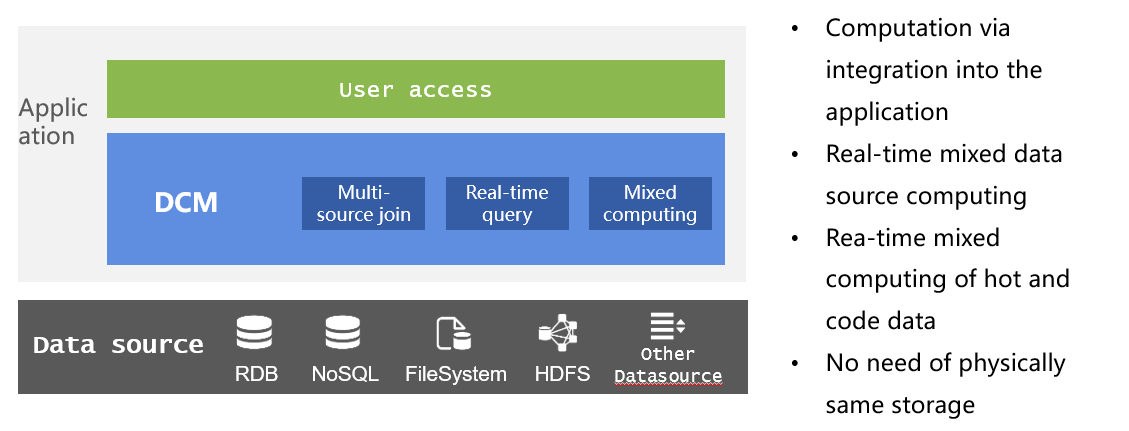
Diverse data sources are characteristic of contemporary applications. Dealing with different data sources in databases demands data loading, which is inefficient and cannot guarantee real-time-ness of data. On top of that, each data source has its strengths and weaknesses – RDB has strong computing ability but low I/O throughput; NoSQL offers high I/O rates but weak computing ability; and files like text data are very flexible to use but do not have any computing ability, and loading every type of data to databases wastes their strengths.
With DCM’s ability to perform diverse-data-source mixed computations, we can directly query data retrieved from any of RDB, text files, Excel, JSON, XML, NoSQL or through network interfaces. This can ensure the real-time-ness of data and computation and make full use of each source’s advantages.
Microservice implementation
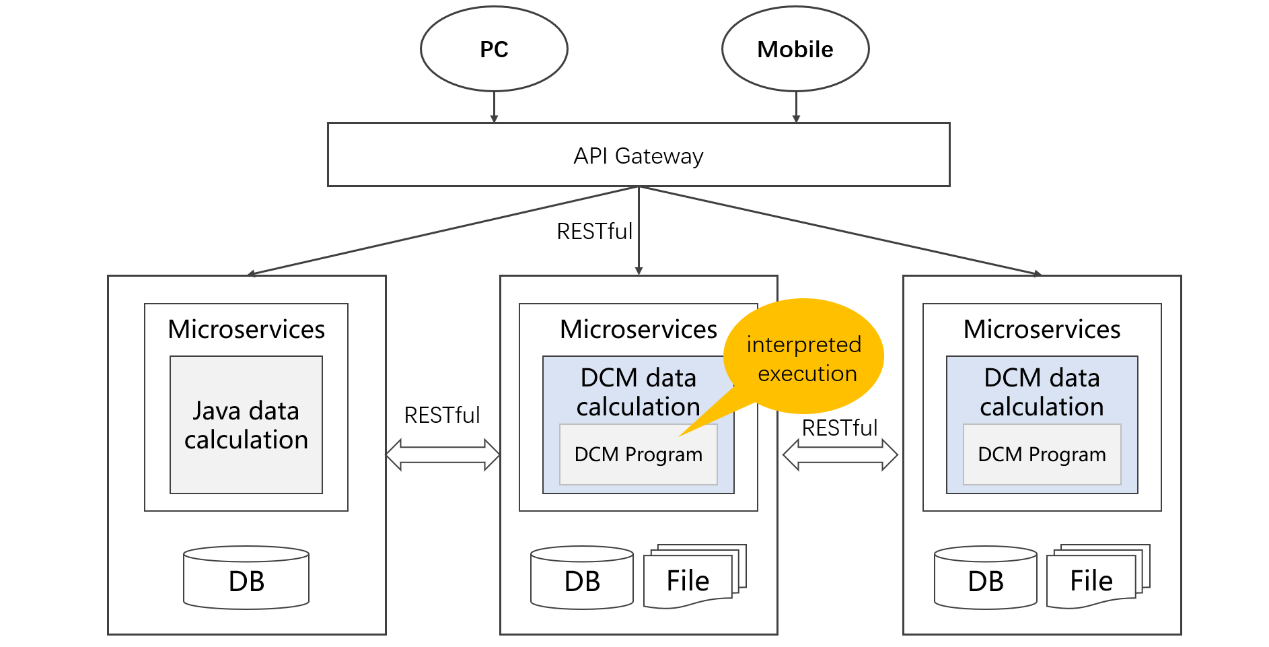
Now microservice implementation still depends heavily on Java and databases for data processing. Java produces too complicated code and does not support hot swap. Databases demand data loading from all types of sources because of the limits of “base”. This is inflexible and non-real-time, and cannot give full paly to each source’s advantages as well.
DCM is integration-friendly. By embedding the DCM in the middle ground or each stage of microservice implementation to perform data collection & cleansing, data processing and in-front data computing, the computing system becomes open and flexible so that each data source’s strengths can be brought into full play. At the same time, issues of diverse data source handling, real-time computing and hot-deployment are resolved.
Replacement of stored procedure
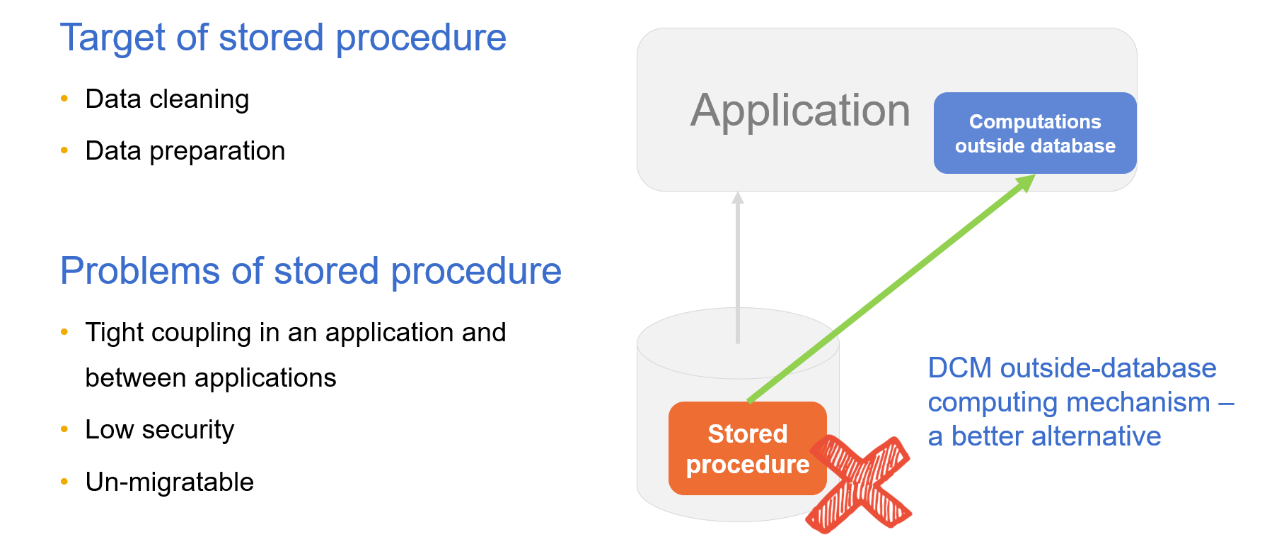
Stored procedures are traditionally used to clean data or achieve complex computations thanks to its advantages in database computation. But their disadvantages are noticeable, too. Stored procedures are hard to migrate, edit and debug. Creating and using stored procedures require high database privilege that poses data security threats. Stored procedures serving the front-end application can cause tight coupling between the database and the application.
With DCM, we can place the stored procedure in the application to create “outside-database stored procedure” and use the database mainly for storage. Decoupling stored procedures from the database eliminate various problems caused by them.
Data preparation for BI reporting
Preparing data source for report development is DCM’s important task. The conventional practice of doing the job in the database has a series of problems like complicated implementation procedure and tight coupling. Reporting tools themselves cannot handle complex computations due to their weak computing abilities. DCMs offer database-independent, powerful computation capacity to create a special data computing layer for report development, which decouples computations from the database and reduces the database’s workload and makes up for the shortage of reporting tool’s computing ability. Besides, the logically separate computing layer helps to make development and maintenance light and convenient.
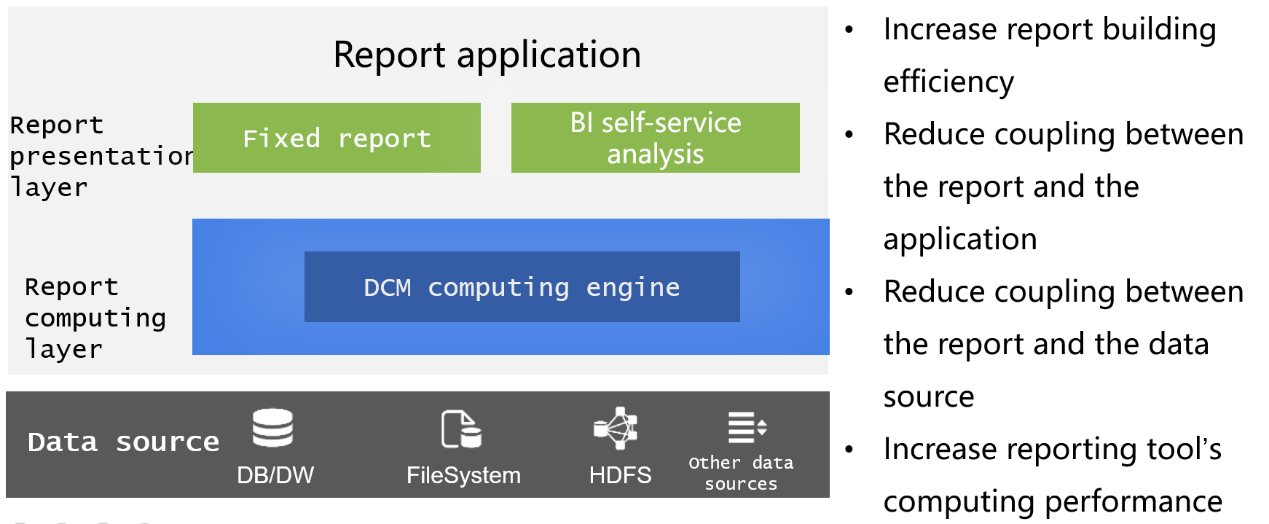
Elimination of intermediate tables
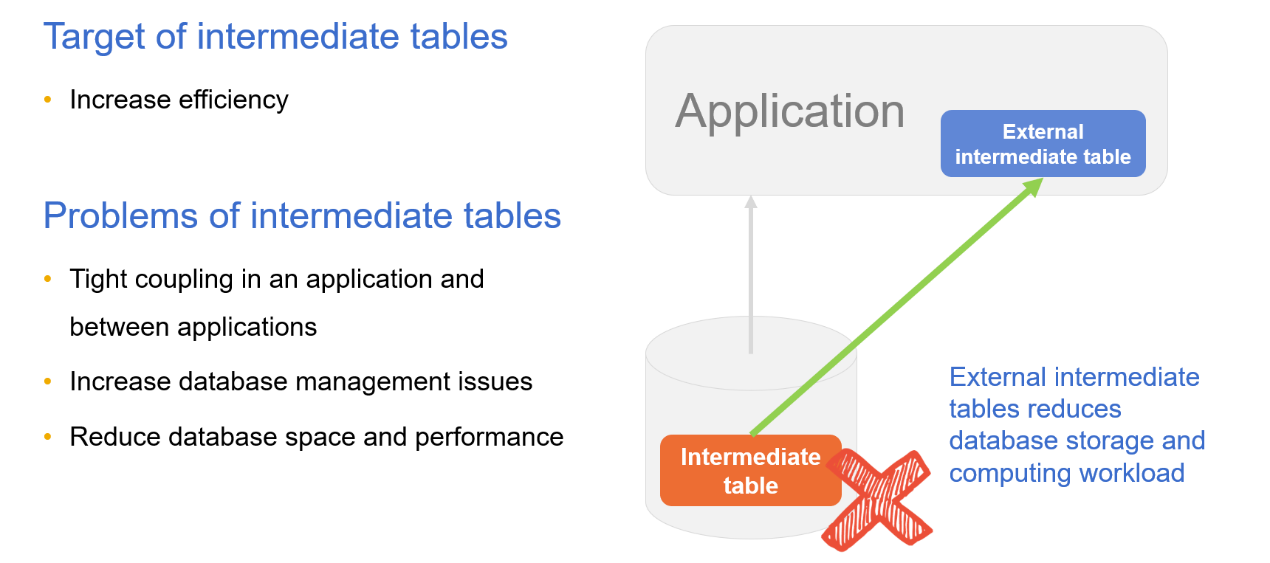
Sometimes, we pre-process the to-be-queried data and store the result in the database as tables in order to speed up future queries. These database tables are called intermediate tables. Some complex computations need to retain intermediate results and they are stored in the database as intermediate tables. Data retrieved from different sources needs to be stored in intermediate tables before being computed in the database. Similar to stored procedures, intermediate tables are probably shared by multiple applications or modules after they are created, resulting in tight coupling between application and database. Worse still, intermediate tables are inconvenient to delete and thus accumulate over time. The accumulation will cause database capacity and performance problems because intermediate tables occupy too much space and generating them needs computing resources.
DCMs enable storing intermediate data in files. And performing computations with a DCM decouples computing logics from the database, which reduces the computational and data storage load for databases. The biggest benefit of using a DCM is that files are enabled to have computational capacity, making it possible to store intermediate data outside databases. The main purpose of storing intermediate results in databases is to use databases’ computing ability. Now that we have DCM’s computing capability, there are more ways of storing intermediate data and the best choice is to put it in a file system.
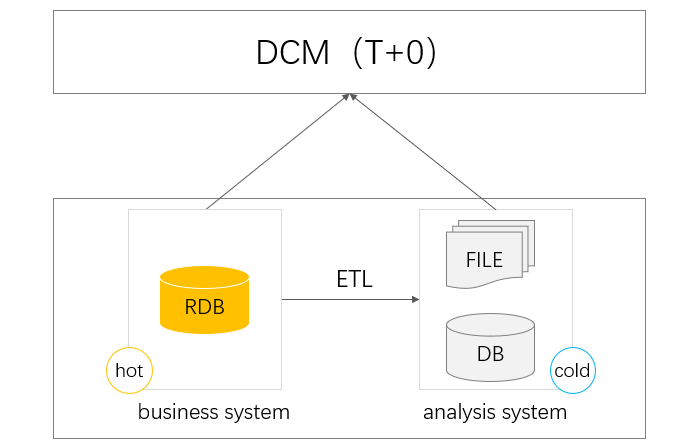
T+0 queries
When data accumulates to a relatively large size, performing queries based on production database could affect transactions. To address this issue, the large amount of historical data will be split away and stored in a separate, special database. This is the separation of cold data from hot data. Now querying the whole data get cross-database computations and routing between hot data and cold data involved. Databases have troubles dealing with cross-database queries, particularly those between different database products, which leads to inefficiency. There are other problems like instable data transmission and low extensibility that prevent convenient and efficient T+0 queries.
DCMs can solve all those problems. With independent and all-around computational capacity, they can retrieve data from different databases respectively and thus handle scenarios involving different types of data sources well. With DCMs, we can select the best place where the computation will be handled, the DCM or the database, according to the database’s resource load. This is flexible. In the aspect of logic implementation, DCMs ‘s agile computing ability can streamline complex computing procedures for T+0 queries and increase development efficiency.
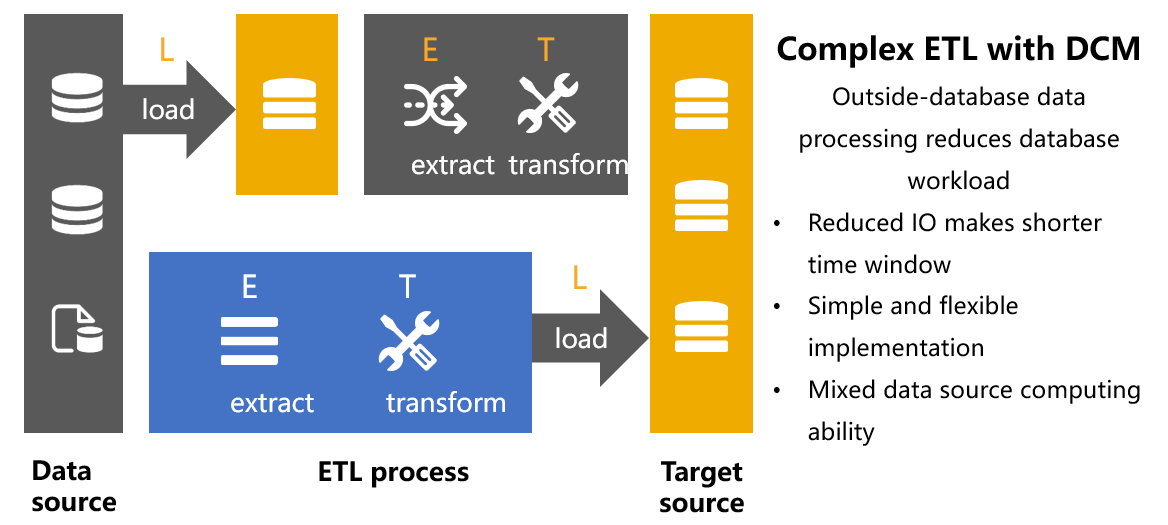
ETL
ETL extracts, transforms and loads data to the target side. Data at the source side may have different origins (text file, database or web) and different levels of data quality, so both E and T phases involve a large volume of computations. As no data sources have better computational capacity than databases, loading data to databases is necessary for performing those computations. As a result, ETL becomes LET. Data piles up in the database, taking up a large amount of space and causing capacity crisis. Assigning data extraction and transformation jobs to the database prolongs the data processing time. This, together with the time spent in loading large amounts of uncleansed and untransformed raw data to the database probably make the limited ETL time window even tighter. Being unable to complete the ETL task in the specified time period will affect businesses the next day.
Introducing DCM to the ETL process ensures the reasonable order of E (Extract), T (Transform) and L (Load), and addresses problems LET has. With its open computational capability, DCM extracts and transforms data retrieved from different data sources. The powerful computational capacity enables DCM to handle various complex computations conveniently and load the prepared data to the target side, achieving true ETL.
What features a good DCM should have?
As a variety of application scenarios are available to DCMs, an excellent DCM should have certain features to be able to handle them well.
Compatible
First, it should be highly compatible to operate across platforms. Working well with various operating systems, cloud platforms and application servers is a prerequisite for a wide field of application.
Second, it should be fully compatible with diverse data sources. Directly dealing with any data source and performing mixed computations between them require a DCM to be highly open.
Hot-deploy
Data processing activities are frequent and volatile. During business processes, computing tasks are often added or modified. A hot deployable DCM can handle any changes of data processing logic in real-time without restarting the application (service).
Efficient
Performance is an important or sometimes key aspect of data computing scenarios. After all, speed gives the edge. A good DCM is able to handle data efficiently by offering high-efficiency mechanisms like high-performance libraries, storage strategies and convenient techniques for implementing parallel processing.
Agile
DCMs should be agile enough to implement data processing logics, including complex ones, conveniently, simply and quickly with their all-around computing capacity, and run the code efficiently. To be agile, a DCM needs to have flexible programming mechanism and easy to use development environment.
Scalable
DCMs should have flexible scalability to make up for the shortage of computing resources as needed. Scalability is very important for today’s applications as it determines the upper limit of DCM’ capacity.
Embeddable
DCMs should be embeddable so that they can be seamlessly embedded in applications to act as computing engine and packaged and deployed as part of the application. This way the application obtains powerful computational capacity, becomes independent of databases, and can handle scenarios where storage and computation are separated, microservices and edge computing smoothly. Besides, ease of integration is another aspect of being agile. The lightweight DCM can be embedded and integrated in the application anytime, anywhere.
If we connect the first letters of these DCM features, we get CHEASE, which is very similar to CHEESE. The role of DCMs is like the cheese sandwiched between a hamburger (as the following picture shows). Without cheese (CHEASE), hamburgers (computations) won’t be so tasty (convenient) and nutritious (efficient).

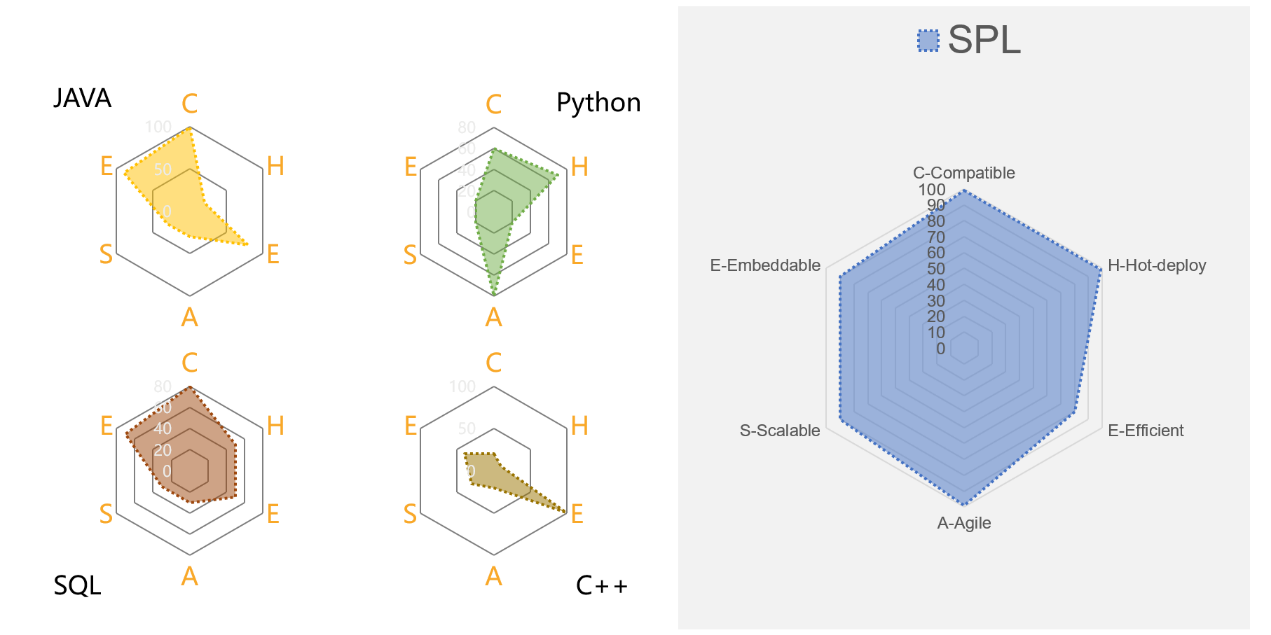
So, we can evaluate a DCM according to the CHEASE standard. Now let’s look at to what extent does each mainstream technology meet the CHEASE standard.
The status quo of technology ecosystem
SQL
Databases are the bastion of SQL and usually have strong computing capacity. Some leading database products deliver powerful computing performance that can meet the strong needs for high efficiency (E). However, databases are closed and data needs to be loaded into them for further computations. This falls short of the needs of diverse-data-source scenarios and leads to poor compatibility (C)。
In regard to embeddability (E), most databases are designed as stand-alone systems. A very few embeddable ones, such as SQLite, simply can’t cut the mustard in the aspects of functionality and performance. Databases, in an overall sense, are not embeddable.
As the language specially used for performing set-oriented computations, SQL is convenient to use in handling simple scenarios but it takes a ridiculously roundabout route to achieve complex computations by resorting to nested queries. Long SQL with thousands of lines is not a rare thing in real-world businesses. These SQL statements are hard to write and inconvenient to maintain. In view of this, SQL is not agile (A).
Similar Hadoop and related technologies have same problems. The closed system is incompatible, clumsy and un-embeddable. Though more scalable than databases, they, in a general way, do not meet the DCM CHEASE standard. Spark shows a higher degree of fitness, but it isn’t hot deployable and is not convenient for achieving complex computations. And Spark SQL also has SQL problems. All these technologies are too heavyweight to satisfy the DCM standard of agility, embeddability and hot-deployment.
Java
Java, as a native programming language, is good at cross-platform computations and able to achieve diverse-source computing tasks through coding. So, it is highly compatible (C). Besides, as most applications are written in Java, the high-level language has good embeddability (E).
Yet, Java’s weaknesses are also noticeable. As a compiled language, it is non-hot-deployable (H). Without the necessary class libraries for structured data computations, Java produces even dozens of lines of code to accomplish a simple grouping & aggregation computation and its code for achieving a complex computation is tortuous. Microservice frameworks use Java hardcoding to handle data processing tasks because the SQL-based databases become unavailable when computations are moved frontward. The implementations of computing logics in Java are difficult and complicated, which means the language is not agile (A) at all. Though Java8 introduced Stream, its computational capacity remains essentially similar (Kotlin has same problems, too).
In theory, Java can achieve various high-performance algorithms, but the costs of encapsulating the Java implementations for a certain application or project are too high. From the practical point of view, Java cannot achieve high efficiency (E). It is also not scalable (S). On the whole, Java is not suitable for implementing the DCM.
Python
Python is too popular to be ignored. The programming language has high compatibility (C) by supporting both cross-platform computations and direct access of diverse sources. And having a rich set of data processing packages enables it to be widely applicable.
Python, compared the previously-mentioned technologies, has a lot of advantages for computing structured data, but it also has weak points, including going a circuitous way to handle order-based grouping computations. This leaves Python down in agility (A).
Also, Python library Pandas falls short of the demand for high efficiency (E), especially in big data computing scenarios. The inefficient implementation of algorithms is an important cause. It is hard to implement high-performance algorithms without agile syntax. Scalability (S) is another pain point with Python. The fact is that, same as Java, Python needs large amounts of development resources in order to have good scalability.
Python’s biggest problem is poor embeddability (E). It is integration-unfriendly with today’s applications. Though certain architectures like sidecar pattern can be used to achieve invocation between services, it is a far cry from the embedded integration (which forms one process) the DCM standard requires. Yet Python’s major application scenarios are not enterprise application development that Java is intended for. Each has its purpose and putting them to other uses is ineffective. Eventually, professional tools are necessary for a certain undertaking.
SPL – the specialized DCM -
The open-source esProc SPL is a professional, specialized DCM that boasts all-around, database-independent computing capacity. The open computing capability allows it to directly compute data retrieved from different sources. SPL is interpreted execution and intrinsically hot-deployable. It is so integration-friendly that it can be conveniently embedded in an application to empower the latter with great computing ability while at the same time bringing DCM’s competence into full play.
Excellent compatibility
SPL is written in Java and so it has Java’s cross-platform capacity that enables it to operate under various operating systems and cloud platforms. SPL’s highly open computing compacity permits it to directly access diverse data sources, including RDB, NoSQL, CSV, Excel, JSON/XML, Hadoop, RESTful and Webservice, and perform mixed computations between any of them, which makes data loading unnecessary and ensures real-time-ness of data retrieval and computation.

Giving direct access to diverse data sources eliminates database problems of being unable to handle cross-source computations and outside-database data. Together with its complete set of computational capabilities and simpler-than-SQL syntax, SPL gives applications computing capacity equal to, even greater than, databases.
Besides the native syntax, SPL also supports SQL syntax based on SQL92 standard. It allows developers accustomed to SQL to use their familiar language to query data originated from non-RDB sources like text, Excel and NoSQL.

Note that an open computing system is the foundation of strong compatibility and a wide range of applications.
Hot-deployment
The interpreted execution mechanism gives SPL the natural hot-deploy ability. This makes it really suitable for handling volatile tasks involving frequent additions and modifications of business logics (like reporting and microservices).
High efficiency
SPL offers a lot of high-performance algorithms and storage strategies to increase efficiency. In the previous discussions of using DCM to eliminate intermediate tables and facilitate ETL, data needs to be stored in outside-database files. Storing data in SPL’s exclusive file formats can achieve much higher performance than the open formats like text.
SPL provides two high-performance storage formats – bin file and composite table. A bin file is compressed (to occupy less space and allow fast retrieval), stores data types (to enable faster retrieval without parsing), and supports the double increment segmentation technique to divide an append-able file, which facilitates parallel processing in an effort to further increase computing performance. The composite table uses column-wise storage to have great advantage in handling scenarios where only a very small number of columns (fields) is involved. A composite table is also equipped with the minmax index and supports double increment segmentation technique, letting computations both enjoy the advantages of column-wise storage and be more easily parallelly processed to have better performance.
SPL offers high-performance algorithms for a variety of computations, such as getting TopN. It treats calculating TopN as a kind of aggregate operation, which successfully transforms the highly complex full sorting to the low-complexity aggregate operation while extending the field of application.
A |
||
1 |
=file(“data.ctx”).create().cursor() |
|
2 |
=A1.groups(;top(10,amount)) |
Get records of orders whose amounts rank in top 10 |
3 |
=A1.groups(area;top(10,amount)) |
Get records of orders whose amounts rank in top 10 in each area |
The SPL statements do not involve any sort-related keywords and will not trigger a full sorting. The statement for getting top N from a whole set and that from grouped subsets are basically the same and both have high performance. SPL boasts many more such high-performance algorithms.
It is easy to implement parallel processing in SPL and fully bring into play the advantage of multiple CPUs. Many SPL functions, like file retrieval, filtering and sorting, support parallel processing. It is simple and convenient for them to automatically implement the multithreaded processing only by adding the @m option. They support writing parallel program explicitly to enhance computing performance.
Great agility
SPL offer its native syntax and concise and easy to use IDE that enables convenient code writing and debugging as well as real-time viewing of result of each step of the procedural programming. The grid-style coding produces tidy code and allows referencing an intermediate result by cell name without the need of specifically defining a variable – which is simple and convenient.

It is convenient to implement structured data computations with SPL’ rich set of class libraries that cover grouping & aggregation, loop computations, filtering, and set-oriented and order-based computations, etc.

SPL is particularly good at achieving complex logics. It is simple and easy to implement them using SPL while SQL needs nested queries. To count the longest days when a stock rises continuously based on the stock record table, for instance, SPL solution is far simpler than the SQL one.
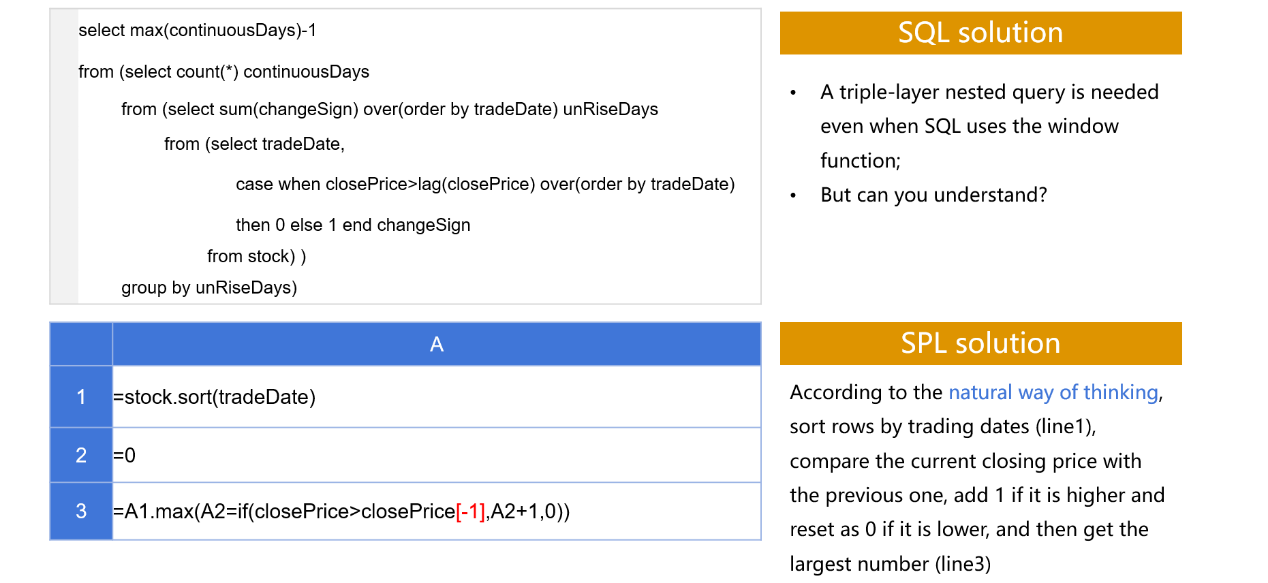
The SQL code contains a triple-layer nested query. It is hard to read and even harder to write. The SPL code has only three lines written according to the natural way of reasoning. It is obvious to get which is better.
High agility boosts development efficiency and enables convenient implementation of high-performance algorithms as well. An algorithm is efficient only when it is successfully and simply achieved. SPL can both make and achieve great algorithms.
Good scalability
SPL can deploy the computing service specifically for scenarios having high demand for performance on multi-node distributed cluster that uses load balancing and fault tolerance mechanisms. The mechanisms enable scaling out to expand capacity when computing resources reaches the maximum limit. This makes SPL have good scalability.
The SPL distributed computing allows users to design data distribution and redundancy plans according to the features of the current data and computation so that the amount of data transmission between nodes can be effectively reduced, higher performance is obtained, flexible control of data allocation is achieved.
A SPL cluster is centerless. There isn’t a permanent master node in a cluster. SPL lets programmers control nodes participating in the computation through coding. This can effectively avoid the single point of failure. Meanwhile, SPL assigns tasks according to whether a node is available or not (the number of running threads on it), trying to maintain balance between workload and resources.
SPL supplies two types of fault-tolerance mechanisms – redundancy-based fault tolerance for disk data and “spare tire”-style fault tolerance for in-memory data. The systems enable automatically transferring the computing tasks to another available node if the current one malfunctions.
Easy embeddability
SPL offers standard JDBC/ODBC/RESTful driver to be embedded in an application. The latter can send a request to get the result of executing the SPL code as it invokes a stored procedure.
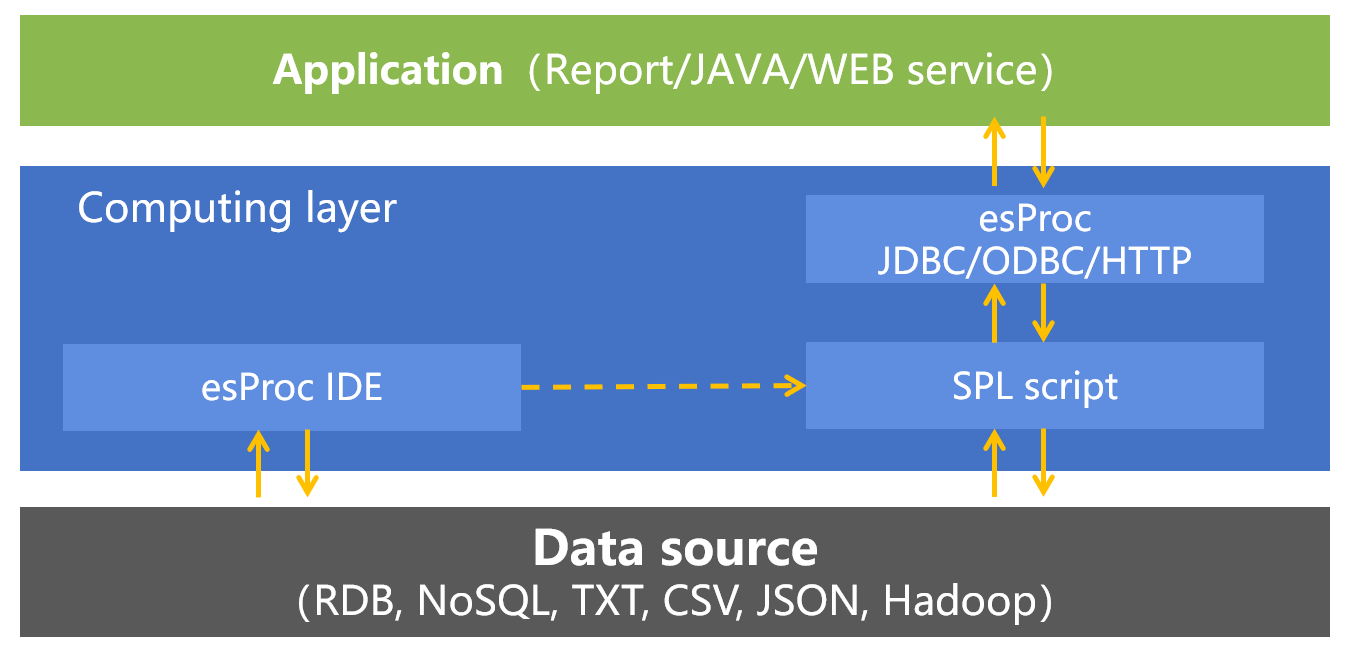
Logically, SPL, as a DCM, inserts itself between the application and the data source to perform data processing. It provides computing service to the higher level and smooths away differences of data sources for the lower level. It is such a position that the importance of a DCM is highlighted.
Below is a code sample of invoking SPL code through JDBC:
Class.forName("com.esproc.jdbc.InternalDriver");
Connectionconn=DriverManager.getConnection("jdbc:esproc:local://");
CallableStatementst=conn.prepareCall("{callsplscript(?,?)}");
st.setObject(1,3000);
st.setObject(2,5000);
ResultSetresult=st.execute();
SPL has balanced, strong ability for each of the six aspects of DCM standard (CHEASE) and exhibits remarkable overall performance – far better than any of the other technologies mentioned above. It is thus the ideal candidate for acting as the DCM.
SPL Official Website 👉 https://www.scudata.com
SPL Feedback and Help 👉 https://www.reddit.com/r/esProcSPL
SPL Learning Material 👉 https://c.scudata.com
SPL Source Code and Package 👉 https://github.com/SPLWare/esProc
Discord 👉 https://discord.gg/2bkGwqTj
Youtube 👉 https://www.youtube.com/@esProc_SPL

