

Use Open-source Java Library esProc SPL to Run SQL on Files
esProc SPL is a powerful, open-source computing engine. It can run SQL statements that use SQL92 syntax on csv, txt, xls, xlsx and other file formats.
Download, installation and integration
Find source code of esProc SPL in github.com/SPLWare/esProc. As it takes time and effort to compile the source code, a ready-to-use installation package is offered by the vendor for users to download. You can also Google “esProc SPL” and find official website to download the installation package if necessary.
After esProc SPL is installed, three jar files for integrating it into Java are in place under [installation directory]\esProc\lib :
esproc-bin-xxxx.jar The driver package of esProc SPL and its JDBC
icu4j_60.3.jar Handle internationalization
jdom-1.1.3.jar Parse configuration file
Load these jars to your Java project and you can execute SPL code through JDBC driver:
Class.forName("com.esproc.jdbc.InternalDriver");
Connection conn =DriverManager.getConnection("jdbc:esproc:local://");
Statement statement = conn.createStatement();
ResultSet result = statement.executeQuery("=1");
result.next();
int IntResult=results.getInt(1);
The integration is successful if the above code is correctly executed and we can extract 1 from IntResult.
Run SQL on regular files
Now we can run SQL on a file through SPL.
Let’s run a simple SQL statement on a file with regular format. Below is the content of a csv file:
OrderID,Client,SellerId,Amount,OrderDate
26,TAS,1,2142.4,2009-08-05
33,DSGC,1,613.2,2009-08-14
84,GC,1,88.5,2009-10-16
To perform filtering on the file using where statement, the Java code is as follows:
PreparedStatement pstmt = conn.prepareStatement("$select * from d:/Orders.csv where Amount>? and Amount<=?");
pstmt.setInt(1,1000);
pstmt.setInt(2,3000);
ResultSet result =pstmt.executeQuery();
A SPL SQL statement begins with the sign $ yet uses same syntax as an ordinary SQL statement. It also uses the question mark ? to pass parameter. In the returned result, we can view the following result:
| OrderID | Client | SellerId | Amount | OrderDate |
| 26 | TAS | 1 | 2142.4 | 2009-08-05 |
| 133 | HU | 1 | 1419.8 | 2010-12-12 |
| 43 | KT | 3 | 2169 | 2009-08-27 |
This is a regular format csv file and does not need special handling for executing a SQL statement on it. Similarly, a SQL statement can be directly executed on a regular format txt file.
For example, we have a tab-separated txt file where the first row contains column names and that has same data as the above csv file. We are trying to perform a grouping & aggregation on it using group by…having…. The SQL statement is as follow:
$select year(OrderDate) y,Client,sum(Amount) amt,count(1) cnt from d:/Orders.txt group by year(OrderDate),Client having count(1)>=3
Computing result:
| y | Client | amt | cnt |
| 2009 | BSF | 13412 | 3 |
| 2009 | GAE | 5292 | 4 |
| 2009 | GC | 3084.5 | 4 |
A regular format xls/xlsx file has column names in the first row and records in all the other rows. A SQL statement can execute on such a file directly. Below is part of an xls file:
 |
A | B | C | D | E |
| 1 | OrderID | Client | SellerId | Amount | OrderDate |
| 2 | 26 | TAS | 1 | 2142.4 | 2009-08-05 |
| 3 | 33 | DSGC | 1 | 613.2 | 2009-08-14 |
| 4 | 84 | GC | 1 | 88.5 | 2009-10-16 |
Use group by…having… to perform grouping & aggregation on the file. Below is the SQL statement:
$select year(OrderDate) y,Client,sum(Amount) amt,count(1) cnt from d:/Orders.xls group by year(OrderDate),Client having count(1)>=3
The code returns same result as the above code.
SQL 92 syntax includes a lot of content, such as join\case\as\distinct\order by\with subclause\from subclause\in subclause\nested subquery and a variety of mathematical, string and date functions. Find more information in SQL Query over File Examples.
Mixed file processing
SPL SQL can achieve computations on same/different-format file, such as set operations (like intersection, union and difference), subqueries and join queries. An xlsx file stores employee records as follows:
|
A | B | C | D | E | F | G |
| 1 | EId | State | Dept | Name | Gender | Salary | Birthday |
| 2 | 18 | Florida | Administration | Jonathan | M | 7000 | 1971-03-07 |
| 3 | 20 | Florida | Administration | Alexis | F | 16000 | 1977-08-07 |
| 4 | 26 | Florida | Administration | Timothy | M | 5000 | 1977-12-24 |
We are trying to perform a join on this xlsx file and the previous csv file containing orders:
$select e.Dept dept,o.CLient client, sum(o.amount) amt from d:/Orders.csv o left join d:/Employees.xlsx e on o.SellerId=e.EId group by e.Dept ,o.Client
Computing result:
| dept | client | amt |
| Administration | BSF | 2670.4 |
| Administration | DY | 517.8 |
| Administration | GAE | 2008.8 |
Writing data to file
SPL SQL supports using select …into… to write a computing result to a file. For instance, we are trying to group and summarize a txt file and write result to result.csv:
$select year(OrderDate) y,Client,sum(Amount) amt,count(1) cnt into d:/result.csv from d:/Orders.txt group by year(OrderDate),Client having count(1)>=3
Open result.csv and we can view the result:
y,Client,amt,cnt
2009,BSF,13412.0,3
2009,GAE,5292.0,4
2009,GC,3084.5,4
SPL supports writing a result to four types of regular format file, including csv\txt\xls\xlsx. If the target file already exists, SPL checks whether it has same structure as the result, and append data to it if the checking result is true and won’t perform appending if the checking result is false.
Irregular format file processing
SPL SQL can also process irregular format file. This involves its native syntax.
Suppose a txt/csv file does not have column names in the first row, and we are trying to query the file using SQL:
$select * from {file("d:/noColName.csv").import@c()} where _4>1000 and _4<=3000
In the above code, _4 is the default column name representing column 4; {…} contains native SPL syntax, which boasts powerful parsing and computing abilities. A single import() function possesses a series of functionalities, such as using user-defined separator, specifying data type of user-defined format, skipping N rows, and handling parentheses, double/single quotation marks.
Suppose we have a file separated not by the commonly seen tab but the double vertical lines ||, we can query the file using SPL SQL in the following way:
$select * from {file("d:/sep.txt").import@t(;,"||")} where Amount>1000 and Amount<=3000
And its date type is not the default one such as "2012-01-01" but one like "01-01-2012", we can query the file using SPL SQL as follows:
$select * from {file("style.txt").import@t(orderid,client,sellerid,amount,orderdate:"dd-MM-yyyy")} where Amount>1000 and Amount<=3000
Find more uses of import function HERE.
The cooperation of native SPL syntax and SQL also can be used to handle an irregular xls/xlsx file. With an xlsx file where the detail data begins directly from the first row:
$select * from {file("D:/Orders.xlsx").xlsimport()} where _4>1000 and _4<=3000
To skip the title zone in the first two rows:
$select * from {file("D:/Orders.xlsx").xlsimport@t(;,3)} where Amount>1000 and Amount<3000
To read a sheet named "sheet3":
$select * from {file("D:/Orders.xlsx").xlsimport@t(;"sheet3")} where Amount>1000 and Amount<3000
The xlsimport() function makes it possible to parse files of more complicated formats, such as reading rows the Mth to Nth and opening an xls file using the password. Find the function’s more uses HERE.
Complicated format file processing
If a file has even more irregular and complicated format, more native SPL syntax will be involved to pre-process the file. SQL is undebuggable, and holding more native SPL code results in lower development efficiency. In this case we can use SPL script plus SPL IDE. Use multi-step native SPL code to do the pre-processing, reference the pr-processing result in SQL, and invoke the SPL script file in the Java program.
In a file, for instance, three rows correspond to one record and the second row contains three fields, and we are trying to filter the file according to the fourth field. Below is part of the file:
26
TAS 1 2142.4
2009-08-05
33
DSGC 2 613.2
2009-08-14
84
GC1 1 88.5
2009-10-16
First, execute [installation directory]\esProc\bin\esproc.exe (which is esproc.sh under Linux\Mac), open SPL IDE, and edit the following script file:
|
A |
| 1 | =file("D:\\threeLines.txt").import@si() |
| 2 | =A1.group((#-1)\3) |
| 3 | =A2.new(~(1):OrderID, (line=~(2).split@p("\t"))(1):Client,line(2):SellerId,line(3):Amount,~(3):OrderDate) |
| 4 | $select * from {A3} where Amount>? and Amount<=?; arg1,arg2 |
Below is the SPL script in SPL IDE:
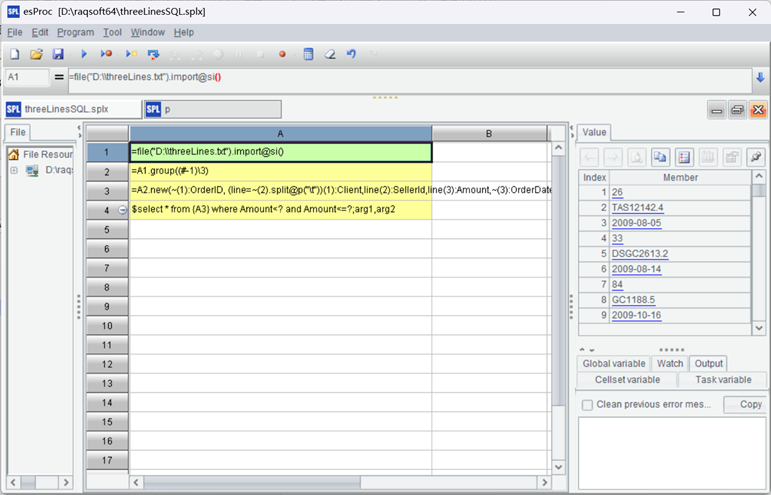
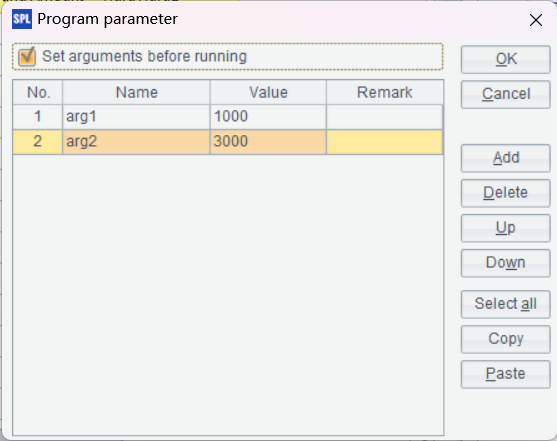
In the SPL code, arg1 and arg2 are parameters. They can come from Java JDBC or the reporting tool. Define the parameters through Program->Parameter on menu bar:
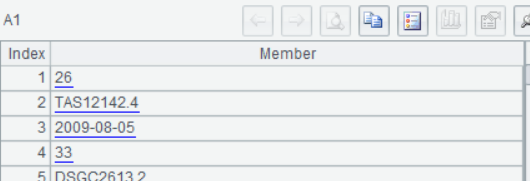
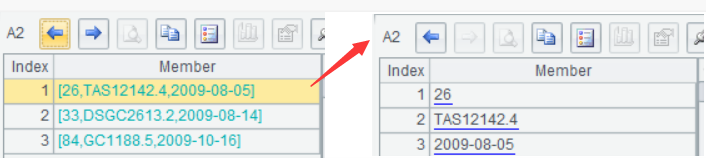
After executing or debugging the SPL script, click A1-A4 and we can view the result of each step in the Value Viewing Section on the right side:
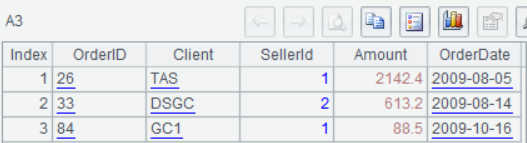
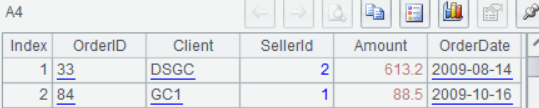
Now we invoke the SPL script in the Java. First save the SPL script as a file, like threeLinesQuery.splx, and reference the file name in a Java program as invoking a stored procedure.
Class.forName("com.esproc.jdbc.InternalDriver");
Connection connection =DriverManager.getConnection("jdbc:esproc:local://");
CallableStatement statement = connection.prepareCall("{call threeLinesQuery (?,?)}");
statement.setInt(1, 1000);
statement.setInt(2, 3000);
ResultSet result= statement.executeQuery();
Find explanations of native SPL syntax in SPL Programming. The SPL syntax is more concise and more convenient to use than SQL in handling complicated computing tasks.
Extended reading:
Open-source SPL That Can Execute SQL without RDB
Open-source SPL Helps JAVA Handle Files of Open Formats (txt/csv/json/xml/xls)
SPL Official Website 👉 https://www.scudata.com
SPL Feedback and Help 👉 https://www.reddit.com/r/esProcSPL
SPL Learning Material 👉 https://c.scudata.com
SPL Source Code and Package 👉 https://github.com/SPLWare/esProc
Discord 👉 https://discord.gg/2bkGwqTj
Youtube 👉 https://www.youtube.com/@esProc_SPL

