

Open-source SPL optimizes bank pre-calculated fixed query to real-time flexible query
Problem description
The index query system of Bank W is used to calculate and display various aggregate indexes, which is an important support tool of this bank’s operating index system. Since the volume of detailed data is too large, this query system has been adopting a pre-calculation method. However, as the index system advances, this method cannot meet the needs of the rapid growth of index numbers, and gradually becomes a bottleneck restricting the index system.
When facing a huge amount of data, the pre-calculation is a method you have to adopt. Bank W has tens of millions of customers, generates tens of millions of deposit details and millions of loan details every day. The data are stored in the database, and when the business staff puts forward a requirement for the calculation of index, the software engineer will code SQL statements to calculate. However, SQL code is very long and complex, and the amount of data to be calculated is large, if such SQL code is submitted to database to calculate in the daytime, it will overburden the database and even lead to a failure to respond to normal business requests. Therefore, the index query system stores the written SQL code in advance, and submit it to database in batches every night to execute. The execution result is stored in an index result table. In this way, the business staff can quickly query when they come to work the next day.
With the increase of index number, the pre-calculation method is unable to meet the needs. Taking loan balance as an example: if it is classified into 5 tiers of dimensions, five indexes will be derived, namely “tier 1 loan balance, tier 2 loan balance...”; if four types of guarantees are added, 20 indexes are derived: “tier 1 and category A guarantee balance, tier 1 and category B guarantee balance...tier 3 and category C guarantee balance...”; if ten kinds of customers and four kinds of lending ways are added, a total of 800 indexes are derived. The number of derived indexes is particularly huge, providing other dimensions like currency type, branch, date, customer age range and education background are included. This is only the case with loan, and other items such as deposit and customer should also be considered. If all these indexes are to be pre-aggregated, it’s impossible to store all results!

Is there a method to calculate out the required index in real time directly from detailed data?
The biggest difficulty faced in real-time calculation based on detailed data is the performance. The calculation of index involves a variety of mixed operations such as large table association, conditional filtering, grouping and aggregating, de-duplication and counting. Now let’s take the example of calculating “the number of de-duplicated customers who deposit on a certain day”, and there are 20 million records in the customer table, and 30 million records in the deposit table that day. This calculation task sets two fixed conditions: multiple branches and currency type, and multiple dynamic conditions: deposit category, customer age range, gender, education background, product, etc. We do this task in 3 steps, i)associate the two tables on customer no.; ii) filter out the records that meet fixed and dynamic conditions; iii) de-duplicate the customers based on customer number and then count. When this task ends, we find that it takes a long time for the database to calculate just one index.
 In fact, one page defined at will by users through the index query system may contain dozens or hundreds of indexes, see the figure below:
In fact, one page defined at will by users through the index query system may contain dozens or hundreds of indexes, see the figure below:
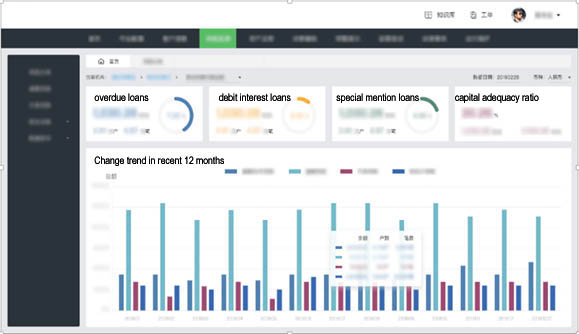
Let’s take the index block “change trend in recent 12 months” in the lower part of the figure as an example. On the last day of each month (inclusive), it needs to calculate 4 indexes including 90 days overdue loans, overdue loans, non-performing loans and nonaccrual loans, and it also needs to calculate three indexes under each index, namely balance, number of transactions and number of de-duplicated users, totaling 13×4×3=156 indexes. Moreover, four index blocks located above this index block also have 4x2x4=32 indexes, so there are a total of 188 indexes to calculate throughout the page. If high-concurrency query is considered, for example, 10 users query this page simultaneously, then nearly two thousand indexes need to be calculated at the same time.
The simultaneous calculation of thousands of indexes with one database means that the large tables with tens of millions of records have to be associated, filtered, de-duplicated and aggregated thousands of times. As a result, the database will be in overload, and the business staff have to wait for the result for a long time, which is unacceptable to the bank.
This bank's server is a virtual machine with mainstream configuration (64-core CPU, 256G RAM, 1T HDD). Obviously, a single-node database is unable to implement the simultaneous calculation of thousands of indexes. In this case, you will naturally come up with the cluster solution, does it work? Suppose there are 20 concurrent access users, it needs to calculate 4000 indexes at the same time, and a second-level response time is required. If each database computes 100 indexes, a total of 40 servers are required. Querying only one index needs such a large-scale cluster, the building and maintaining costs are unacceptable to the bank.
Analysis and solution
To solve performance problem, we need to carefully analyze the characteristics of data and calculation first, and then determine key points, and finally gradually optimize through changing the data storage and calculation methods.
Performance optimization 1. We know, after estimation and verification, that more than 30G of memory space is required for loading just one day's data into memory, so the solution of loading all data into memory is unfeasible. Instead, we should store large tables like deposit/loan detailed table and customer table externally, and store small dimension tables like organization and employee tables into memory.
Take deposit as an example. The deposit table has dozens of columns of data. When calculating one index, only a few columns are used. Since the query won’t involve all columns, we consider using ordered columnar storage as follows:

The columnar storage avoids reading the entire file, and only needs to read the involved columns. The use of columnar storage makes the values of customer number field adjoin each other, orderly and have more repeated values, which helps to improve compression ratio. A high compression ratio can reduce the disk space occupied by data, and the time in reading files.
Performance optimization 2. The customer table and deposit table are associated on customer no. We regard them as a primary-sub relationship, and can speed up calculation through ordered merging as shown below:

Since both tables in primary-sub relationship are stored orderly by customer no, they can be joined through ordered merging with only one traversing needed, and the calculation complexity is M+N. In contrast, RDB adopts HASH algorithm with a corresponding complexity of SUM(Ni*Mi). Therefore, the ordered merging performs much better.
Ordered merging can also be done every night when the batch job is performed. Add customer data into the detailed data redundantly, and generate merged data files. Since the ordered merging is not needed when querying, the performance is better.
Performance optimization 3. The result of ordered merging of the said tables is also in order by customer no., and hence we can adopt an ordered de-duplication way to quickly count:
 When de-duplicating the customers and counting, it only needs to compare adjacent customer numbers, and only one traversal is needed to accomplish the calculation.
When de-duplicating the customers and counting, it only needs to compare adjacent customer numbers, and only one traversal is needed to accomplish the calculation.
Performance optimization 4. An organization will have n branches (business outlets). To count the index of an organization, we need to do IN conditional judgment for the branch code of detailed data. If the IN calculation is performed on a record-by-record basis with common method, the performance will be poorer when n is larger. To solve this problem, we calculate n branches to a boolean dimension sequence in advance as follows:
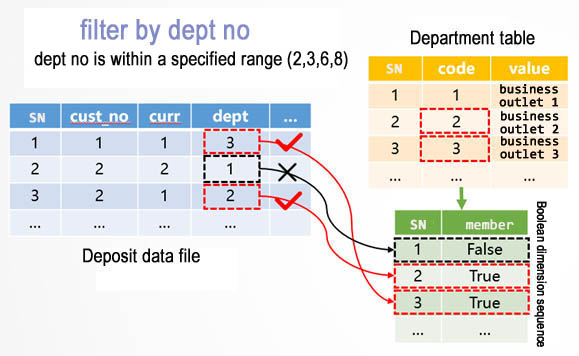
When querying, traverse the deposit file in segments. Specifically, for the 1st record, its value in deptfield is 3, we find the 3rd member in the boolean dimension sequence. Since the value of this member is true, the 1st record satisfies the condition. If the value is false, this record doesn’t satisfy condition. For other records, do the same thing.
Boolean dimension sequence converts the comparison of values to the reference of sequence number, effectively reducing the computing time. The computing time of IN is independent of the number of IN enumeration values and won’t increase as the number of enumeration values increases.
Performance optimization 5. Since the server has multi-core CPU, we can make use of multiple threads to calculate one index, as shown below:
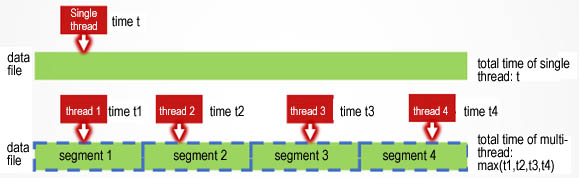
Using 4 threads to calculate one index at the same time can speed up by 2-3 times.
Performance optimization 6. The data amount of currency type, organization number, etc., is not very large, we store them as integer. This storage way stores less data than the string way and the calculation speed is faster. We can pre-generate a set containing all small integer objects (from 0to 65535) in memory:
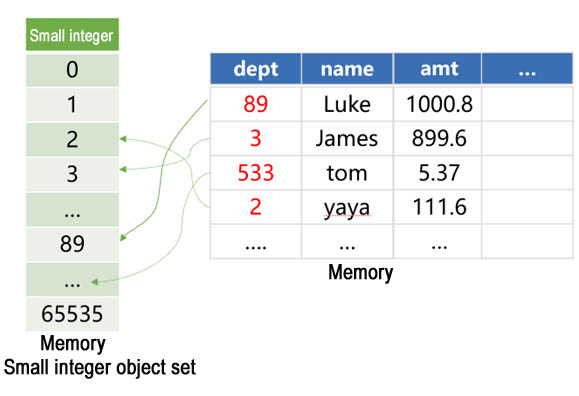
Since the currency type, organization number, etc. are all less than 65536, objectification is no longer needed when reading them from hard disk. Instead, we refer to the pre-generated small integer object in memory. In this way, the objectification time is saved, the memory space occupation is decreased.
Performance optimization 7. To calculate the index “number of de-duplicated customers”, two fields are required: customer no. and detail no, while for the “balance” and “number of transactions” indexes, the two fields are not required. Too many customer numbers or detail numbers is the main reason for huge computing amount.
To cope with this problem, we adopt a partial pre-aggregation method, that is, associate customers with deposit table in advance, and then group and aggregate through fields other than customer number and detail number to generate a new data file, and finally count the balance and number of transactions. The new file is much smaller than the original file, the computing speed is thus much faster. Moreover, the optimization methods 4 to 9 in this article can also be employed.
Note that the new file adds a field “number of transactions” to record the sum of the pre-aggregated number of transactions. The subsequent number of transactions will not be counted but summed.
Performance Optimization 8. When counting the index of the whole bank, it needs to count the detailed data of every business outlet. In other words, all detailed data meets the organization condition. Therefore, there is no need to compute the IN condition on organization number. Adding a judgment in the code, and removing the filter condition on “organization number" if the index belongs to whole bank’s index can decrease a lot of calculations and improve performance.
Performance optimization 9. The application server communicates with the data computing server through the network. There are dozens to hundreds of indexes to be calculated on the user interface, and each index invoking needs the establishment of network connection. When multiple users query concurrently, the large number of network requests and connections will become a bottleneck.
So, instead of establishing connection to the application server on index, we establish connection on “index block”, as follows:
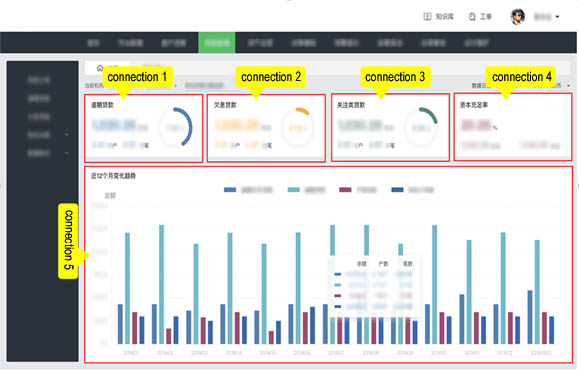
As you can see, the page that otherwise would require 188 connections needs only 5 connections after adjust the connection way. Since the five connections to application server are established in parallel through multiple threads, and in each connection, the data computing server computes multiple indexes also in parallel through multiple threads, the indexes throughout the page are still computed in parallel after adjusting.
Actual effect
Once an optimization scheme is drawn up according to the calculation characteristics, it needs to select an appropriate computing tool. From the above analysis, we know that RDB does not work, for SQL is too sketchy to describe such elaborate optimization algorithms. If we adopt conventional high-level languages like Java, it does work, but there are many disadvantages, including large coding amount, long implementation period, prone to code errors, and difficult to debug and maintain. Fortunately, we have the open-source esProc SPL, which provides rich basic algorithms, enabling us to quickly implement such personalized high-performance computing.
After a few days of programming, debugging and testing, we found that the real-time calculation of index directly from the detailed data worked very well. The test result on one server shows that when calculating the indexes like deposit balance, number of transactions, number of de-duplicated customers, the time for one index is 100-200 milliseconds, including the request time from front-end page and the display time of statistical charts, and it takes only 3 seconds to query 2000 indexes concurrently. If there is a need to support a larger number of concurrent querying, an easy method is to deploy a cluster. SPL cluster has very powerful function, and is easy to use and manage, you can set up a SPL cluster with simply configurations.
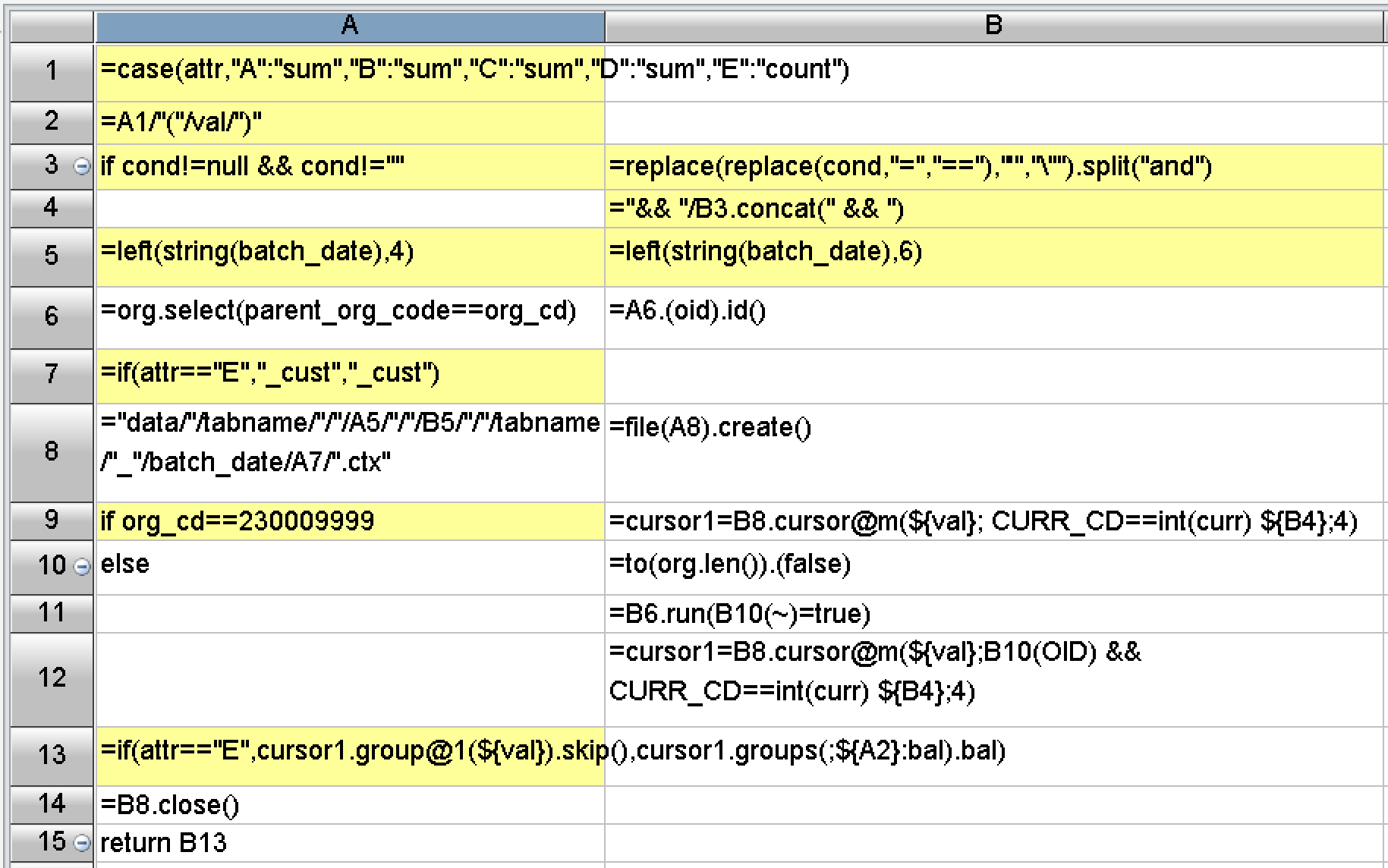
In terms of programming difficulty, SPL has made a lot of encapsulations, provided rich functions, and built-in basic algorithms and storage schemes required by the above optimization solutions. As a result, you don’t need to write long code in practice, and the development efficiency is very high. For example, it only needs a few lines of code when querying one index:
Postscript
To solve the performance optimization problem, the most important thing is to design a high-performance computing scheme to effectively reduce the computational complexity, so as to speed up eventually. Therefore, we should not only fully understand the characteristics of calculation and data, but also have an intimate knowledge of common high-performance algorithms, only in this way can we design a reasonable optimization scheme based on actual condition. The basic high-performance algorithms used herein can all be found at: https://c.raqsoft.com/article/16413676961944, where you can find what you are interested in.
Unfortunately, the current mainstream big data systems in the industry are still based on relational database. Whether it is the traditional MPP or HADOOP system, or some new technologies, they are all trying to make the programming interface closer to SQL. Being compatible with SQL does make it easier for users to get started. However, SQL, subject to theoretical limitations, cannot implement most high-performance algorithms, and does not have any measure to improve when the hardware resource is wasted. Therefore, SQL should not be the future of big data computing.
When we have the optimization scheme, we also need to select a good programming language to efficiently implement the algorithms. Although the common high-level programming languages can implement most optimization algorithms, the code is too long and the development efficiency is too low, which will seriously affect the maintainability of the program. In this case, the open-source SPL is a good choice, because it has enough basic algorithms, and its code is very concise. Moreover, SPL has a friendly visual debugging mechanism, which can effectively improve development efficiency and reduce maintenance cost.
If you are struggling with SQL performance optimization, you can discuss with us at:
http://www.raqsoft.com.cn/wx/Query-run-batch-ad.html
More related cases:
Open-source SPL Speeds up Query on Detail Table of Group Insurance by 2000+ Times
Open-source SPL optimizes batch operating of insurance company from 2 hours to 17 minutes
Open-source SPL improves bank’s self-service analysis from 5-concurrency to 100-concurrency
Open-source SPL turns pre-association of query on bank mobile account into real-time association
Open-source SPL speeds up batch operating of bank loan agreements by 10+ times
SPL Official Website 👉 https://www.scudata.com
SPL Feedback and Help 👉 https://www.reddit.com/r/esProcSPL
SPL Learning Material 👉 https://c.scudata.com
SPL Source Code and Package 👉 https://github.com/SPLWare/esProc
Discord 👉 https://discord.gg/2bkGwqTj
Youtube 👉 https://www.youtube.com/@esProc_SPL


Chinese version