

Lightweight big data processing technology
The framework of modern big data application is roughly as follows:
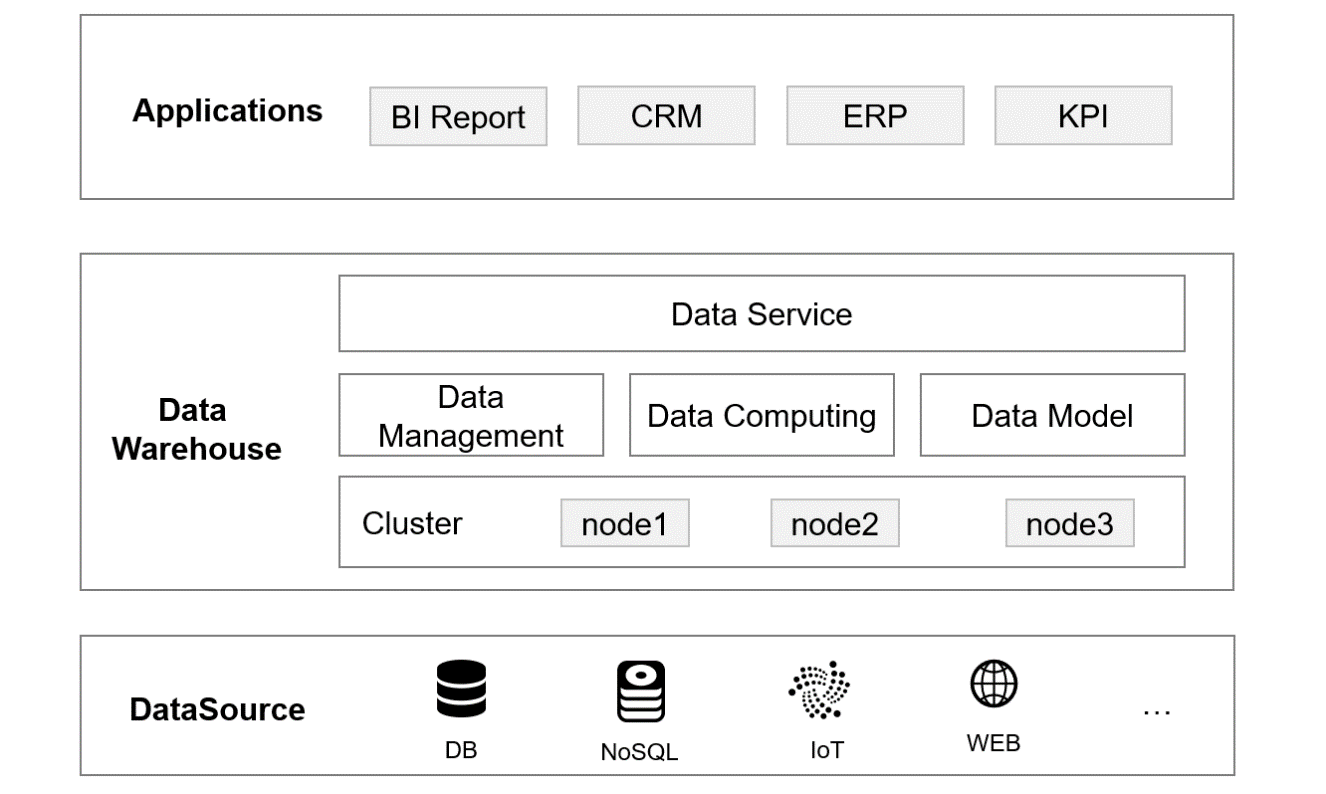
As a bridge between various applications (upper part) and data sources (lower part), the data center (middle part) needs not only to process and analyze the data of multiple data sources but also to provide data service for every application, so its importance is self-evident. Since the data center needs to process huge data amount and respond to numerous tasks, the big data cluster technology is a common way to implement. Only in this way can huge business needs be satisfied. Moreover, this way allows us to scale out the computing ability so as to meet growing business needs.
This is a heavy solution.
Like other technologies, this architecture has some drawbacks in practice:
First, O&M is complex. Cluster doesn’t work without O&M. Normally, the larger the scale of a cluster, the more complex the O&M. Moreover, current big data technologies cannot utilize hardware resources efficiently, and thus more hardware is required to make up for this deficiency, resulting in an increasingly large cluster scale, which in turn increases the complexity and cost of O&M.
Second, the system is closed. At present, no matter what big data technology is adopted, it faces the problem of closeness. The so-called closeness means that the data can be calculated only when it is loaded into database, because the calculations of data inside and outside the database are quite different. To load the external data into database, an ETL process is a must, which not only increases the workload, but loses the real-time of data. In addition, the data of modern business comes from many sources, if we go through an ETL process before every computing, it will inevitably reduce the use efficiency of data and increase the cost.
Third, coupling problem exists. Since the data center serves all applications, some data processing tasks may be shared by multiple applications. Of course, this is reasonable from the point of view of resource saving. However, the sharing of table (storage) and computing logic (code) will result in tight coupling between applications, it is not only disadvantageous for application expansion (modification may affect other applications), but increases the difficulty of O&M (some functions have to be retained even if they expire). Consequently, the data center is too bloated, and the O&M becomes more complex, and you will often face the pressure of capacity expansion.
The original purpose of building a data center is to provide data service for the entire business, but it seems that you can't have the data center undertake all computing tasks, as the capacity of data center is limited. If the data center is under great pressure, you need to find a way to share its computing tasks.
A common practice is to transfer part of computing tasks to the application side, especially some temporary and personalized tasks. Since such tasks can be done at application side, it is unnecessary to put them all to data center. So here comes a question: how to implement such tasks at application side?
One solution is to add a front-end computation layer based on the original framework to share part of computing tasks. Specifically, the computation layer can contain multiple data marts, each of which exclusively serves a certain type of applications. In this way, the calculations are shared, and the coupling problem between applications is solved.
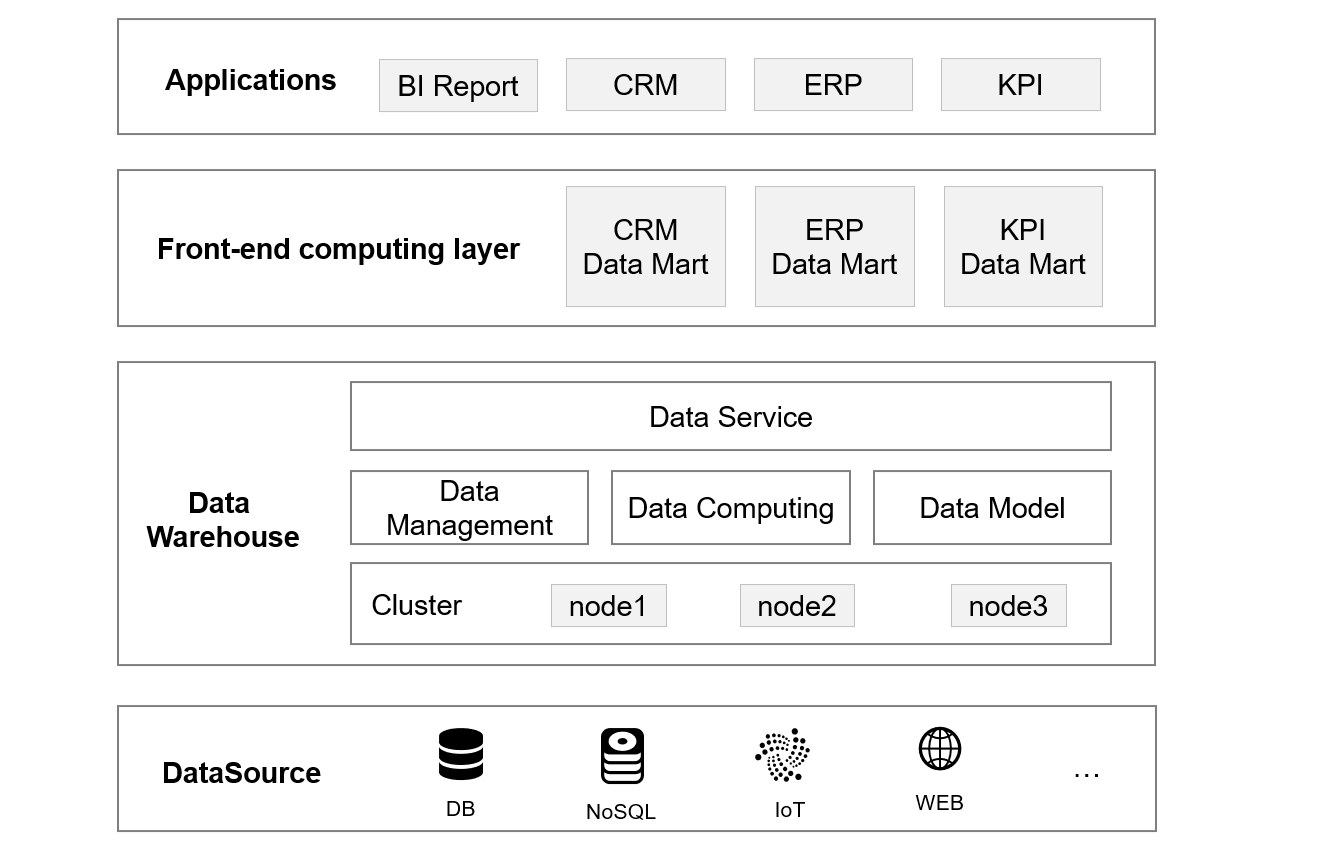
Then, what technology is used to build the computation layer?
Obviously, the adoption of big data technologies that are used for data center doesn't work because such technologies rely heavily on cluster, and are too heavy for front-end computing task with relatively small data amount. If big data technology was adopted, it would very likely not be as easy as expanding the data center. Moreover, as multiple data marts are to be built, the framework will become complex, and the difficulty of O&M will increase. As a result, the cost will be far greater than the expansion of data center, resulting in more losses than gain.
Since big data technology doesn't work, how about traditional databases? Database is not as heavy as the cluster technology, and very strong in computing ability, it seems to be a suitable solution. In fact, however, database is still very heavy, for the reason that the vast majority of databases still need to be deployed separately, which requires adding a physical layer (independent hardware resource) to the framework, causing the framework and O&M to be more complex, and the cost is still high. Besides, there are two other key factors that make database less suitable for implementing front-end computing.
One is the data range. The purpose of building front-end computation layer (data mart) is to share the computing pressure of data center, but the calculation cannot be done without data, so the question arises: what data needs to be moved to data mart? If the data range is too small, the data mart won't work, because too small range often makes application fail to find the required data, thereby losing the significance of front-end computing. On the contrary, if the data range is too large, it won’t work either. Although moving all data to the data mart can certainly find the required data, the capacity is a problem. Not to mention whether the data mart can hold so much data, doing so is equivalent to building another data center, and makes no sense. In fact, even if big data technology is adopted, this problem exists. As long as the data mart store part of data, it will result in a failure to find the required data.
The other is the problem of SQL itself, which is mainly reflected in three aspects. Firstly, SQL requires metadata to run, but the efficiency of loading and computing metadata is very low and, all data must be loaded into database before being computed due to the closeness of database, these factors make SQL heavy to run. Secondly, the ability of SQL is not complete. In practice, it is difficult for SQL to implement some complex calculations (such as e-commerce funnel calculation involving ordered steps), it needs to resort to other languages such as Python or Java to implement such calculations, resulting in a complex and heavy technology stack. Thirdly, it is not easy to code in SQL, and in practice, a multiply-layer nested SQL code with over a thousand lines is very common. Such SQL code is not only hard to write but hard to maintain, resulting in heavy burden in development. These problems of SQL are reflected not only in the database but also in many big data technologies that support SQL.
On the whole, application-side computing needs a lightweight big data processing technology that is independent of database, integrable, embeddable, simple and convenient, and this technology should have strong openness, and has the ability to process the data from multiple sources and solve data range problem. Unfortunately, existing technologies have problems of one kind or another.
The open-source esProc SPL is a good solution.
Lightweight big data computing engine esProc SPL
As a structured data computing engine specifically for big data, esProc bears the following characteristics: i)it can be deployed independently, or integrated in applications, serving as an embedded engine in applications, thus achieving lighter overall solution; ii) it has good openness, supports mixed computing of multiple data sources; iii)it provides high-performance computing mechanism, which makes it possible to make full use of hardware resource to maximize the performance of a single node, thereby achieving the effect of a cluster by means of one node only, and reducing the application cost; iv) it supports data routing, which allows us to implement a computing task either locally or in data center; v)it provides agile SPL (Structured Process Language) syntax, which is good at implementing complex calculations. In short, esProc is light from deployment to running. Below we will explain the characteristics one by one.
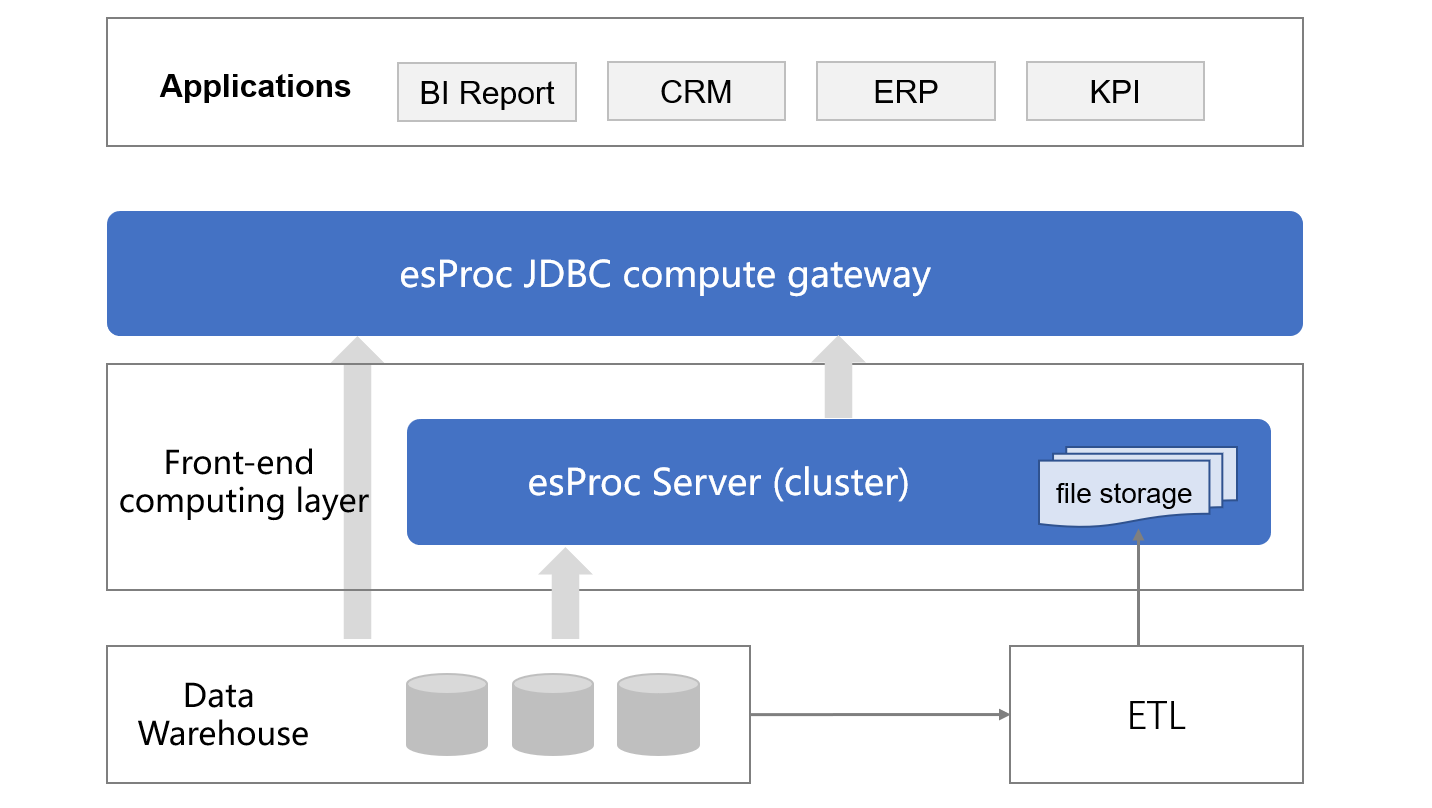
Technical framework of esProc
Integration
esProc can be deployed independently or in an integrated way, it means that it can provide service for applications independently, or be integrated in application to serve as a part of the application. When integrating, we only need to import the jars, which are only tens of MBs in size and very light. After integration, esProc, as the computing layer of application logic, can access data source, and can also provide data service for applications (as it encapsulates the general JDBC/ODBC/RESTful interface).
Good integration makes computing no longer heavy. Embedding esProc in application, and running together with application allow us to calculate flexibly. As a result, there is no need to make unnecessary adjustments to the framework, little increase in O&M complexity, and no additional investment in hardware.
When the computing power is not enough, we can deploy an independent computing service. esProc supports distributed deployment and provides all computing abilities of a cluster, such as load balancing and fault tolerance.
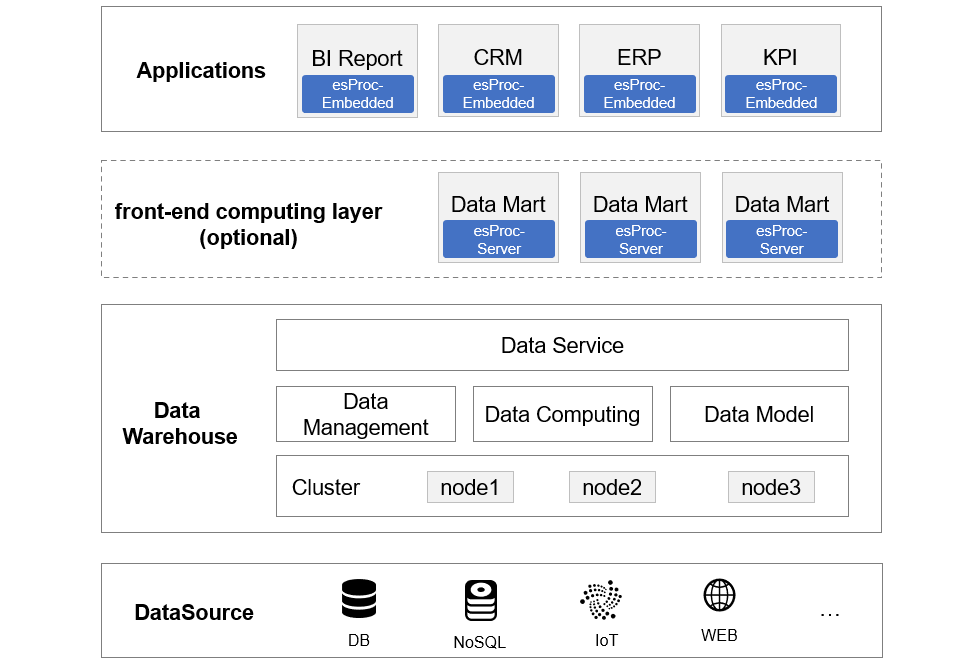
This is the application framework after importing esProc. It can be seen that esProc can be embedded in applications, and thus the physical front-end computing layer is not necessary. If the computing power needs to be enhanced, then deploy an independent computing service. Therefore, it is more flexible in practice.
Openness
esProc doesn’t have the concept of theme (metadata), and doesn’t have a difference between data inside and outside the database. No matter where the data is, they can be computed as long as they are accessible, the only difference is that the access performances are different for different data sources. The good openness of esProc can solve many original problems caused by the closeness of database, such as capacity problem, poor data real-time, as well as the inability to make full use of the advantages of various data sources themselves.
With the support of esProc’s openness, it is easy to utilize the method of trading space for time. To be specific, the redundant data can be stored directly in file system, which won’t put any pressure on capacity, and it is very convenient to compute the redundant data either separately or jointly with data of other sources.
High performance
Similar to database, esProc also provides data storage functionality, allowing us to compute locally. Unlike database, however, esProc stores data directly in files. Currently, esProc provides the high-performance binary file format and offers many storage mechanisms to ensure computing performance, such as compression, columnar storage, ordering, and parallel segmentation.
In addition, esProc is richer in terms of data type and computing library. By means of the high-performance algorithms, we can implement lower-complexity algorithms, thus improving performance. In practice, esProc often runs faster than other technologies by several times to dozens of times, even thousands of times in some extreme cases. For example, in an e-commerce funnel analysis scenario for calculating user churn rate, the user did not get result after 3 minutes running on Snowflake's Medium server (equivalent to 4*8=32 cores), while the user ran the SPL code on a 12-core, 1.7G low-end server and got the result in less than 10 seconds. Another example, in a computing scenario of NAOC on clustering the celestial bodies, esProc's performance is 2000 times faster than other implementation ways (Python and a distributed database).
With these high-performance guarantee mechanisms, a single esProc node can achieve outstanding performance, and can achieve or even surpass the effect of original cluster in some scenarios (single machine can rival a cluster). Therefore, integration should be prioritized when using esProc. If the performance cannot meet computing requirement after integration, then deploying an independent esProc node basically works.
Data routing
esProc provides programmable data routing functionality. When the front-end computing layer (in physics, it can be deployed as an independent server or integrated in application) stores part of the data (frequently used hot data), and if the data request from application exceeds the data storage scope of front-end layer, esProc will automatically route the request to back-end data center to execute, and then return the query result to the application. Routing rules can be determined freely in computing scripts.
For more information, refer to: Routable computing engine implements front-end database
Agility
As mentioned earlier, the heaviness of current technologies is reflected not only in technical framework, but also in SQL syntax system. Instead of continuing to use SQL, esProc designs the SPL syntax based on a new theoretical model. In previous real cases, esProc not only improved the performance, but significantly reduced the code amount. Compared with SQL, SPL is good at implementing complex calculations, for the reason that SPL supports procedural calculation, allowing us to code step by step, and provides complete programming ability, such as loops, branches, procedures and subprograms. In addition, SPL provides very rich structured data computing library.
In the e-commerce funnel case, the code implemented in SPL is much shorter than that implemented in SQL, and SPL code is more universal (one more sub-query is needed for each additional funnel step if SQL is adopted). Shorter code is one of the advantages of SPL syntax. Depending on the agile syntax, complete computing ability, as well as flexible use and high performance, SPL is fully capable of implementing lightweight big data computing.
In summary, the reason why esProc can implement lightweight big data computing and provide front-end computing service for applications at the application side is the result of its integration, openness, high performance, data routing functionality and agility. With these characteristics, it can meet the computing needs of various application easily, reduce the application cost while ensuring high performance, and make the overall solution lighter.
SPL Official Website 👉 https://www.scudata.com
SPL Feedback and Help 👉 https://www.reddit.com/r/esProcSPL
SPL Learning Material 👉 https://c.scudata.com
SPL Source Code and Package 👉 https://github.com/SPLWare/esProc
Discord 👉 https://discord.gg/2bkGwqTj
Youtube 👉 https://www.youtube.com/@esProc_SPL

