

Stored Procedures: Where to Go
The stored procedure is a love-hate thing.
Its significance is obvious as all old-brand databases support it. Newcomer databases are often slighted if they do not support stored procedures. Yet, the stored procedure has noticeable shortcomings. Many development teams make painstaking efforts to remove stored procedures and try to implement all business logics in applications.
The stored procedure is already at the crossroads.
The stored procedure’s biggest advantage is to enhance SQL’s ability to compute in a stepwise fashion. SQL supports writing the whole logic only in a single statement. But certain logics need to be implemented step by step, even including branching the loop statement when they are complicated. In that case, it is hard, even impossible, to code the logic in a single SQL statement. The stored procedure was thus created to tackle the problem.
The defect of stored procedures lies in architecture level. It splits the business logic and puts it respectively in application and in database. This is inconvenient and could cause inconsistency. Also, stored procedures in databases cannot follow the contemporary application frameworks to be scaled out themselves. Since different databases provide different stored procedure syntax, we often need to maintain multiple versions of stored procedures. Compiling a stored procedure requires a relatively high database privilege, which leads to contradiction between potential security risk and high-efficiency development.
High-level programming languages for developing applications naturally support procedural programming. If we implement business logics all in the application and only use SQL to do the basic data read and write, we will take advantage of the stored procedure while avoiding its disadvantages. This is perfect! It is also what those who try to remove stored procedures calculate. But it is not that simple.
To achieve the business logic, application layer not only controls the flow but also participates in the data processing – as a great part of the procedure is about data computing. Java and other high-level languages do not have a sufficient set of structured data types and basic operations and are not as convenient as SQL when handling many data processing scenarios. Their code is extremely complicated and lengthy. Though having architecture advantages, they have much lower development efficiency and are more difficult to maintain.
Python is a bit better than Java, but it is also not as easy to use as SQL. In addition, unless the whole application is written in Python, the language’s poor integration will cause new architecture problems.
esProc SPL is a better choice.
esProc SPL is a purely Java-based, open-source software. It can be seamlessly embedded in a Java application – it’s like when the code is written by application developers themselves – and share the advantages the mature Java frameworks offer.
esProc SPL provides a complete set of structured data types and a rich library of computing functions, including basic operations such as filtering, grouping and join, which cover all SQL functions but produce simpler code. Unlike the ORM technique that depends on databases to work, esProc implements the basic class libraries entirely within itself. Business logics written in SPL are database independent and intrinsically migratable. SPL also offers the method to convert SQL statements (See How to Write SQL Statments That Are Migratable Between Databases). It is easy to migrate necessary, basic SQL statement in the code.
SPL also has a complete set of control statements, such as for loop and if branch statement, and supports invocation of the subprogram. This achieves the procedural programming capability the stored procedure has. SPL alone can implement complex business logics and form a complete business logic unit, without cooperation of the higher-layer main program’s code. The main program just needs to invoke the SPL script as it calls the database stored procedure.
A SPL script can be stored as a file, and placed and maintained together with the application, getting rid of the probable inconsistency caused by business logic maintenance on both sides. Putting the SPL code outside the database amounts to the “outside database” stored procedure. Changes of it do not need any database privileges and potential security risks are eliminated.
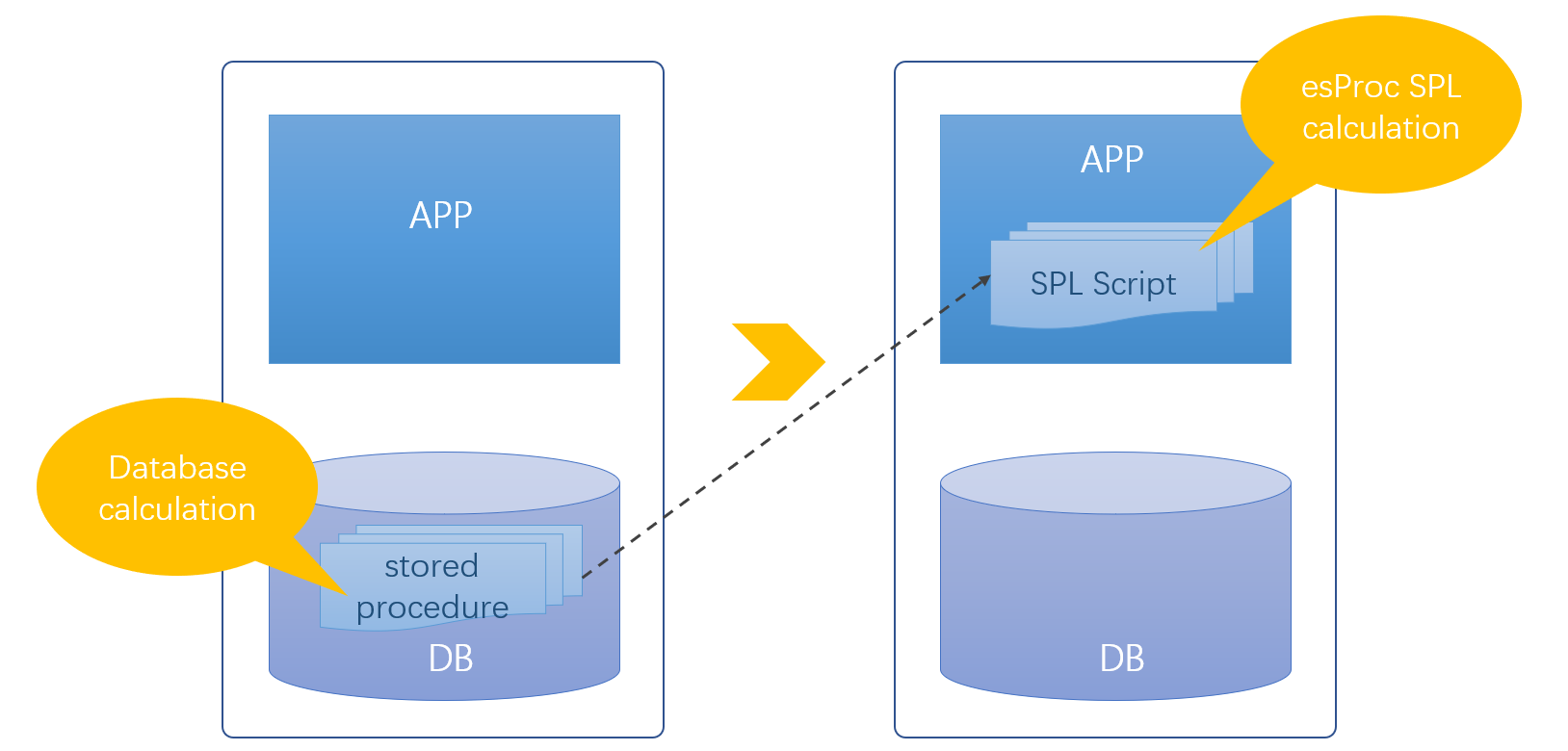
Particularly, SPL is an interpreted execution language. Unlike Stream/Kotlin and other Java class libraries that require re-compilation of the modified code together with the main program and the application shutdown/restart, changes of the SPL code take effect instantly. This is business logic’s hot swapping, which is especially suitable for handling frequently changing business.

Let’s continue to see other characteristics of SPL:
SPL code is written in grid, which is quite different from the text-based code. The SPL IDE is independent, simplistic, and easy to use, offers “Step over”, “Set breakpoint” and WYSIWYG result viewing, and gets higher development efficiency. By contrast, debugging a stored procedure is too inconvenient.
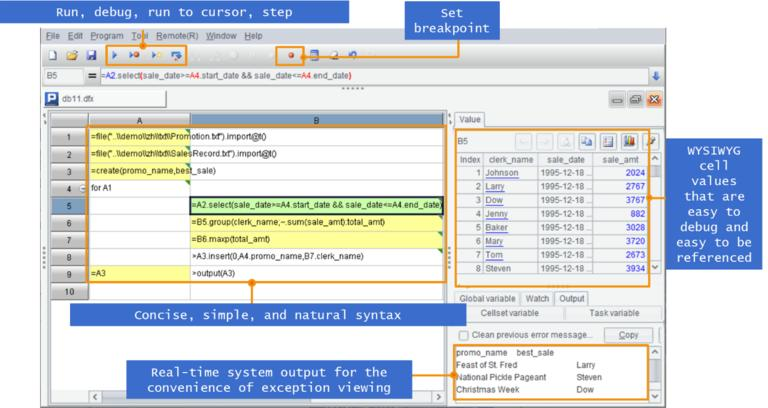
Find more about SPL in A Programming Language Coding in a Grid.
SPL offers much more data objects and computing libraries than SQL. The SPL code is much simpler than SQL in the stored procedure, which further speeds up development and lowers maintenance cost.
For example, we want to find the first n customers whose sum of order amounts takes up at least half of the total and sort them by order amount in descending order. The goal is written in SQL like this:
with A as (select client,amount,row_number() over (order by amount) ranknumber from sales)
select client,amount
from (select client,amount,sum(amount) over (order by ranknumber) acc from A
where acc>(select sum(amount)/2 from sales)
order by amount desc
It is difficult for SQL to handle the record on the dividing line. We should use a roundabout way, with two layers of three sub queries, leading to vague process steps and hard debuging.
SPL codes, on the other hand, has a very clear process:
| A | B | |
|---|---|---|
| 1 | =sales.sort(amount:-1) | / Sort amounts in descending order |
| 2 | =A1.cumulate(amount) | / Get a sequence of cumulative amounts |
| 3 | =A2.m(-1)/2 | / Get the last cumulative amount, which is the total |
| 4 | =A2.pselect(~>=A3) | /Get the position where the cumulative amount exceeds half of the total |
| 5 | =A1(to(A4)) | / Get values according to positions |
SPL supports a large variety of data sources. Relational databases are only one of the various data sources contemporary applications use. But they are the only one that offer the complex stored procedure mechanism.

With the support of SPL, any data source can have the capability the stored procedure has.
A complex stored procedure often generates intermediate tables for performing the subsequent computations. SPL supplies high-efficiency binary file formats to store the intermediate data as files for further processing. Neither native Java nor Python provides such a convenience. Generally, they use text files or databases as the intermediate storage medium, which have low performance and use much more resources.
Finally, get esProc SPL in https://github.com/SPLWare/esProc.
SPL Official Website 👉 https://www.scudata.com
SPL Feedback and Help 👉 https://www.reddit.com/r/esProcSPL
SPL Learning Material 👉 https://c.scudata.com
SPL Source Code and Package 👉 https://github.com/SPLWare/esProc
Discord 👉 https://discord.gg/2bkGwqTj
Youtube 👉 https://www.youtube.com/@esProc_SPL


Chinese version