

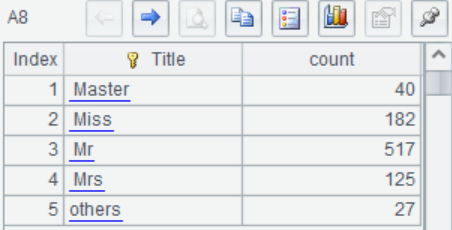
Low frequency categorical data processing
When the number of categories of categorical variable is large, there may be noise, such as category with very few sample, abnormal category, suspected error category, etc. in this case, the number of category can be reduced by combining low frequency variables.
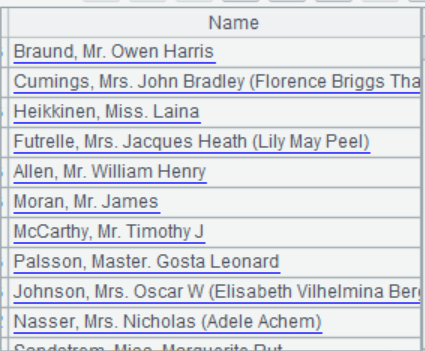
The "Name" in Titanic.csv is a categorical variable. Each passenger's name contains such titles as"Mr"and"Mrs", which can extracted to generate a new variable"Title", and then combine the low-frequency classification in"Title".
SPL code:
A |
|
1 |
=file("D://titanic.csv").import@qtc() |
2 |
=A1.derive(Name.split@b(",")(2).split(".")(1):Title) |
3 |
=A2.groups(Title;count(~):count) |
4 |
=A2.group(Title) |
5 |
=A4.align@a([true,false],~.len()<10) |
6 |
=A5(1).(~.run(Title="others")) |
7 |
=A2 |
8 |
=A7.groups(Title;count(~):count) |
A2 Extract the Title information from Name
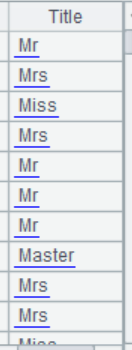
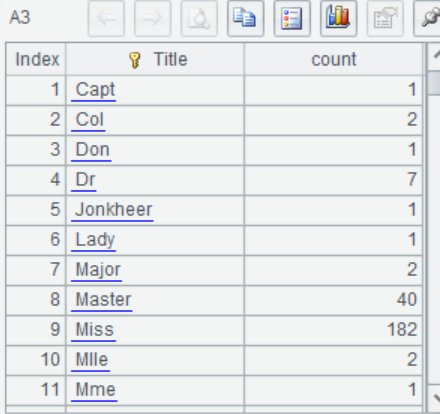
A3 Check the classification in Title, there are some low-frequency categories like "Capt", "Don"...
A4 Group the samples in A2 by Title
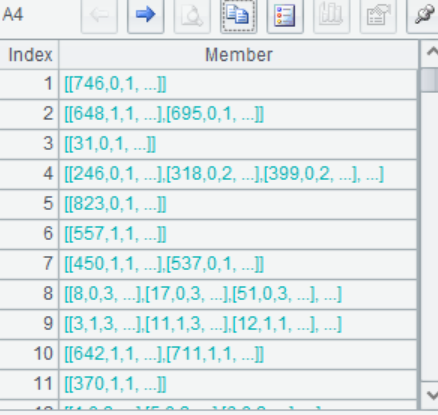
A5 The sample size <10 was divided into one group as low-frequency classification, and the sample size >=10 was divided into the other group

A6 Change the Title of low-frequency classification with less than 10 samples to "others".
A8 Check the classification of Title again, and the low-frequency classification is merged into "others".
SPL Official Website 👉 https://www.scudata.com
SPL Feedback and Help 👉 https://www.reddit.com/r/esProcSPL
SPL Learning Material 👉 https://c.scudata.com
SPL Source Code and Package 👉 https://github.com/SPLWare/esProc
Discord 👉 https://discord.gg/cFTcUNs7
Youtube 👉 https://www.youtube.com/@esProc_SPL

