

What else can Stream&Kotlin evolve into?
Java has not provided a direct dataset operation syntax for a long time, and writing a simple SUM requires many lines, let alone complex operations such as grouping and sorting. The code with exactly the same data processing function is much longer than SQL, resulting in low development efficiency.
Starting from Java 8, Stream has been introduced, providing set operation classes that support Lambda syntax. Programmers no longer write many lines for SUM, and conventional grouping and sorting have ready-made functions.
The sorting on the dataset is written in this way, which is indeed much more convenient than early Java:
Stream<Order> result=Orders
.sorted((sAmount1,sAmount2)->Double.compare(sAmount1.Amount,sAmount2.Amount))
.sorted((sClient1,sClient2)->CharSequence.compare(sClient2.Client,sClient1.Client));
However, compared to SQL, there is still a significant difference in convenience:
select * from Orders order by Client desc, Amount
More complex grouping and aggregation:
Calendar cal=Calendar.getInstance();
Map<Object, DoubleSummaryStatistics> c=Orders.collect( Collectors.groupingBy(
r->{
cal.setTime(r.OrderDate);
return cal.get(Calendar.YEAR) + "_" + r.SellerId;
},
Collectors.summarizingDouble(r->{return r.Amount;})
));
for(Object Sellerid:c.keySet()){
DoubleSummaryStatistics r =c.get(Sellerid);
String year_sellerid[]=((String)Sellerid).split("_");
System.out.println("group is (year):"+year_sellerid[0]+"\t (sellerid):"+year_sellerid[1]+"\t sum is:"+r.getSum()+"\t count is:"+r.getCount());
}
Roughly equivalent to SQL statement:
select year(OrderDate), Sellerid, sum(Amount), count(1) from Orders group by year(OrderDate), Sellerid
The gap is quite obvious.
Based on Stream, Kotlin was developed, which no longer directly uses the Java language and is no longer limited by Java. It can use new syntax and symbols to write more concise Lambda expressions.
For example, the previous sorting:
var resutl=Orders.sortedBy{it.Amount}.sortedByDescending{it.Client}
The level of conciseness is already very close to SQL.
However, in the face of more complex calculations, it is still not convenient enough, such as the aforementioned grouping and aggregation:
data class Grp(var OrderYear:Int,var SellerId:Int)
data class Agg(var sumAmount: Double,var rowCount:Int)
var result=Orders.groupingBy{ Grp(it.OrderDate.year+1900,it.SellerId) }
.fold( Agg(0.0,0),{acc, elem -> Agg(acc.sumAmount + elem.Amount,acc.rowCount+1) })
.toSortedMap(compareBy<Grp> { it. OrderYear}.thenBy { it. SellerId} )
result.forEach{ println("group fields:${it.key.OrderYear}\t${it.key.SellerId}\t aggregate fields:${it.value.sumAmount}\t${it.value.rowCount}") }
Although simpler than Stream, it still cannot be compared to SQL.
It seems that in order to replace SQL (for better framework) in Java to write business logic related to structured datasets, Stream and Kotlin still need to continue to evolve.
The open-source software esProc SPL can achieve the goals of Stream and Kotlin in one step.
esProc SPL is also a pure Java open-source software, similar to Stream and Kotlin, which can be seamlessly integrated into Java applications, enjoying the advantages of mature Java frameworks together.
Similar to Kotlin, esProc also provides a new programming language, which is SPL. But it did not develop from Stream and Kotlin.
Why design a new programming language instead of directly encapsulating it as Java APIs?
Java is a compiled static language that makes it difficult to implement dynamic data structures and convenient Lambda syntax, which is particularly common in structured data operations and the advantage of SQL.
Any SELECT statement in SQL will generate a new data structure, allowing for the addition and deletion of fields without the need to define the structure (class) beforehand, which is common in structured data operations. However, languages like Java won’t work effectively. It is necessary to define all the structures (classes) used when compiling the code, and it can be considered that new classes cannot be dynamically generated during the execution process (Java theoretically supports dynamic compilation, but the complexity is too high). If a specialized class is used to represent all data tables, and field names are also treated as data members of the class, it is not possible to directly use the class’s attribute syntax to reference fields, and the code is very cumbersome.
Lambda syntax is widely used in SQL, such as the condition in WHERE, which is essentially a Lambda expression. Although Java, a static language, currently supports Lambda syntax, it is far less convenient than SQL. A function header definition is needed to tell the compiler every time a Lambda function is about to be written, and the code looks messy. In Lambda functions, field names in the data table cannot be directly referenced. For example, when calculating amounts using unit price and quantity, if the parameter name used to represent the current member is x, it needs to be written in the verbose form of “x. unit price * x. quantity”. In SQL, it can be more intuitively written as “unit price * quantity”.
Only interpretive dynamic languages can implement these features of SQL, which can generate new data structures at any time, or determine whether the current parameter is a Lambda function based on the host function itself. Therefore, there is no need to write a definition header, and fields without table names can be correctly referenced based on the context.
SQL is an interpretive dynamic language, and so is SPL. Java, as well as Kotlin and Scala based on Java, are not, so it is difficult to write concise code in these languages.
On the basis of interpretive dynamic languages, SPL provides more comprehensive structured data objects (tables, records, cursors) and richer computational functions than SQL, including basic operations such as filtering, grouping, and join in SQL, as well as missing ordered and set operations in SQL. So, SPL code is usually more concise and easier to maintain than SQL, and much stronger than Stream and Kotlin.
The aforementioned two sorting and grouping operations, written in SPL, are more concise than SQL:
Orders.sort( -Client, Amount)
Orders.groups( year(OrderDate), Sellerid; sum(Amount), count(1) )
For more complex tasks, such as this one, calculating the longest consecutive days for a stock to rise, SQL needs to be written in multiple nested, lengthy, and difficult to understand:
select max(ContinuousDays) from (
select count(*) ContinuousDays from (
select sum(UpDownTag) over (order by TradeDate) NoRisingDays from (
select TradeDate,case when Price>lag(price) over ( order by TradeDate) then 0 else 1 end UpDownTag from Stock ))
group by NoRisingDays )
Stream and Kotlin lack support for window functions, making it much more difficult and lengthy to write the same computational logic, while using SPL is very simple:
Stock.sort(TradeDate).group@i(Price<Price[-1]).max(~.len())
SPL also has comprehensive process control statements, such as for loops and if branches, and supports subroutine calls. Using only SPL can achieve very complex business logic, directly forming a complete business unit, without the need for upper-level Java code to cooperate. The main program simply calls the SPL script.
esProc SPL is a pure Java program, it can be called by Java, and it can also call Java. In this way, even some code that is difficult to implement in SPL and needs to be implemented in Java (such as some external interfaces) or existing ready-made Java code can be integrated in SPL. SPL scripts and main Java applications can be integrated seamlessly.
As an interpretive language, SPL scripts can be stored as files and placed outside the main application program. Code modifications can be made independently and immediately take effect, unlike code based on Stream and Kotlin that needs to be recompiled with the main program after modification, and the entire application needs to be shut down and restarted. This can achieve hot swap of business logic, especially suitable for supporting frequently changing businesses.

The data sources supported by SPL are also very rich, whether it is a relational database or NoSQL or Kafka or Restful, whether it is a regular two-dimensional table or a multi-level JSON, SPL can all calculate and process. Neither Stream nor Kotlin involves these contents, and you still need to write your own Java code to access them.

Very specifically, SPL code is written in a grid, which is very different from the code typically written as text. The independent development environment is simple and easy to use, providing single step execution, breakpoint setting, and WYSIWYG result preview, making debugging and development more convenient.
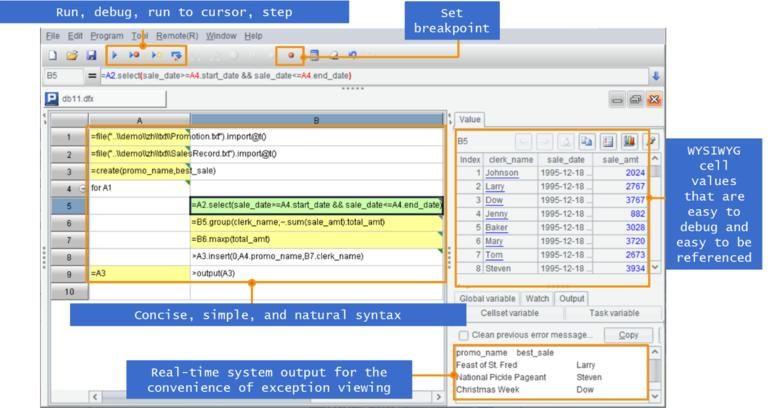
Here A programming language coding in a grid is a more detailed introduction to SPL.
Finally, esProc SPL is here https://github.com/SPLWare/esProc .
SPL Official Website 👉 https://www.scudata.com
SPL Feedback and Help 👉 https://www.reddit.com/r/esProcSPL
SPL Learning Material 👉 https://c.scudata.com
SPL Source Code and Package 👉 https://github.com/SPLWare/esProc
Discord 👉 https://discord.gg/2bkGwqTj
Youtube 👉 https://www.youtube.com/@esProc_SPL


Chinese version