

What to do if the query calculation is moved out of database but is too slow using java
Many modern applications will move data computation and processing tasks away from databases and implement them in Java, which can gain framework benefits. Moreover, Java has comprehensive process processing capabilities and is more adept at handling increasingly complex business logic than SQL (although the code is not short). However, we often find that the performance of these Java codes in computing and processing data is not satisfactory, and they cannot even match the performance of SQL in the database.
Normally, as a compiled language, Java may not be as good as C++in terms of performance, but it should have an advantage over interpreted SQL. However, the fact is not.
Why is this?
There are two main reasons.
One direct reason is the IO aspect. Java itself does not have a common storage mechanism, and usually needs to continue to rely on databases to store data. Therefore, when calculating, data needs to be read from the database first, and the database access interface (JDBC) is not very fast. If the data volume is large, it will suffer significant losses in terms of reading.
Then, can we not use database storage to achieve higher read performance? After all, most of the data is historical data that will not change, and the amount of data that is still changing is usually small. If we change to an efficient access scheme to store cold data, only a small amount of hot data needs to be read instantly. Can Java’s computational performance be greatly improved?
In theory, this is the case, but for the aforementioned reasons, Java itself does not have a common storage mechanism. If a database is not used, public formats such as CSV/TXT can generally only be used. The performance of these formats is not significantly different from that of a database, and there is also a risk of losing data type information. If you design a binary storage format yourself, it can indeed be much faster than a database, but it is not an easy task to consider it comprehensively and implement it, which exceeds the ability of many application programmers.
So, Java programmers are still using databases or text files, enduring low performance IO.
The other reason is algorithm implementation. To run fast and find ways to reduce computational complexity, it is necessary to use some low complexity algorithms. However, the computational complexity of these algorithms is lower, but the implementation complexity is higher.
For example, common grouping and join operations, databases generally use the HASH algorithm instead of direct sorting or hard traversal. But the implementation difficulty of this algorithm is relatively high, and it exceeds the ability of many application programmers. As a result, programmers often use relatively simple sorting or hard traversal methods to implement it, which will increase the computational complexity by orders of magnitude. It is not surprising that compiled Java runs slower than interpreted SQL.
In-memory operations are still slightly better, and there are now some open-source libraries available (but to be fair, their convenience is far inferior to SQL). But for external storage computing involving big data, the Java industry has almost no effective support, making even basic sorting difficult.
Furthermore, to utilize the parallel capabilities of multiple CPUs, it is necessary to write multi-threaded code. Writing multithreading in Java is not a problem, but it is extremely troublesome. Programmers need to consider various issues such as resource sharing conflicts, which can increase implementation difficulty and the possibility of errors. As a result, they often weigh costs and write it as a single thread, wasting CPU resources in vain.
What should we do then?
esProc SPL is here to help you.
esProc SPL is a pure Java open-source computing engine that provides database independent but more powerful computing power than SQL. esProc SPL can be seamlessly integrated into Java applications, just like the code written by application programmers themselves, enjoying the advantages of mature Java frameworks together.
esProc SPL supports access to databases and common public files such as CSV/TXT, and the performance in this area is not significantly different from direct Java development. Especially, esProc has designed high-performance binary file formats that support compression, columnar storage, indexing, as well as cursor and segment parallel mechanisms for big data. Storing historical big data as binary files not only achieves much higher access performance than databases, but also makes it easier to organize and manage using the tree structure of the file system.
The computing power of esProc SPL does not rely on databases or other third-party services, making it easy to implement mixed computing of multiple data sources. Specifically, by simultaneously reading cold data from files and hot data from databases, real-time calculations on whole data can be achieved. Please refer to: How to perform mixed computing with multiple data sources
esProc SPL comes with built-in rich structured data computing class libraries.
Filter:T.select(Amount>1000 && Amount<=3000 && like(Client,"*s*"))
Sort:T.sort(Client,-Amount)
Distinct:T.id(Client)
Group:T.groups(year(OrderDate);sum(Amount))
Join:join(T1:O,SellerId; T2:E,EId)
...
Similar to databases, these libraries also use mature algorithms in the industry, which can efficiently perform calculations.
SPL also supports big data cursors and parallel operations, using mature algorithms, and the syntax is almost the same as in-memory data tables:
file("T.btx").cursor@b().select(Amount>1000 && Amount<=3000 && like(Client,"*s*"))
file("T.ctx").open().cursor().groups@m(year(OrderDate);sum(Amount))
...
This way, Java programmers no longer need to implement these complex algorithms themselves and can enjoy high performance similar to databases.
In fact, SPL provides more structured data operations and high-performance algorithms than SQL. In many complex scenarios, the actual performance of SPL is much higher than that of SQL in the database, often achieving better performance on a single machine than SQL on a cluster: Here comes big data technology that rivals clusters on a single machine .

Take a practical case: a data processing task of a large international bank, the data amount involved is not too large, only over one million rows. But the business rules are very complex. The primary data table has over 100 columns, each with dozens of different calculation rules. Coding in SQL/stored procedures is too cumbersome and chaotic. Although the code written in Java is not short, the structure is much clearer and easier to maintain. The total calculation time of Java code is about 20 minutes, with a reading of about 1 minute. After switching to SPL coding, the reading time of 1 minute cannot be reduced, but the calculation time has been reduced to 1.5 minutes, with a total duration of 2.5 minutes, which is 8 times faster than the original 20 minutes!
In this case, SPL’s ordered cursor technique is utilized. Due to hardware limitations, over one million rows of data cannot be fully loaded and can only be read in using a cursor. After grouping, association operations need to be performed. Even with simple and inefficient multiple traversal association algorithms, Java code is still cumbersome. SPL’s ordered cursor technology can handle grouping while reading, avoiding repeated traversal and association. With less than 300 lines of code, there is still a significant improvement in performance.
SPL also has well-established process control statements, such as for loops and if branches, and supports subroutine calls, which is comparable to Java’s procedural processing capabilities. Using only SPL can achieve very complex business logic, directly forming a complete business unit, without the need for upper-level Java program code to cooperate. The main Java program simply calls SPL scripts.
SPL scripts are stored as files and placed outside the main application program. Code modifications can be made independently and immediately take effect, unlike Java libraries such as Stream/Kotlin that require recompilation with the main program after modifying code, and the entire application needs to be shut down and restarted. This can achieve hot swap of business logic, especially suitable for supporting frequently changing businesses.
esProc SPL also has a simple and easy-to-use development environment, providing single step execution, breakpoint setting, and WYSIWYG result preview. The development efficiency is also better than programming in Java:
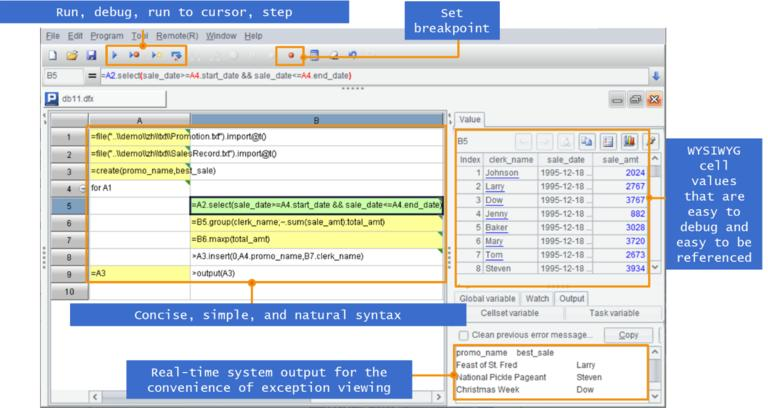
(Here is a more detailed introduction to SPL A programming language coding in a grid )
….
SPL is equivalent to combining the advantages of SQL and Java, that is, it not only has the flexibility and process control ability of Java, enjoys the advantages of Java frameworks, but also encapsulates and extends the algorithms and storage mechanisms of SQL, allowing programmers to gain and surpass the simplicity and high performance of SQL in Java applications.
Finally, esProc SPL is here https://github.com/SPLWare/esProc .
SPL Official Website 👉 https://www.scudata.com
SPL Feedback and Help 👉 https://www.reddit.com/r/esProcSPL
SPL Learning Material 👉 https://c.scudata.com
SPL Source Code and Package 👉 https://github.com/SPLWare/esProc
Discord 👉 https://discord.gg/2bkGwqTj
Youtube 👉 https://www.youtube.com/@esProc_SPL


Chinese version