

The “Female Manager’s Male Subordinates” Problem That Frustrates All BI Tools
Join queries are a big, long-standing problem in BI, and wide tables (CUBE) are commonly used to deal with the problem. A wide table is constructed in advance to eliminate the multitable association so that the issue can be bypassed.
But this reduces the flexibility of the BI tools.
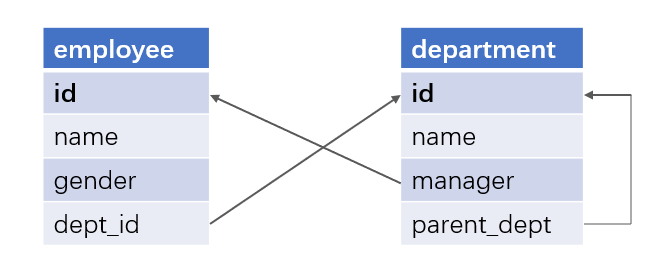
Here is the “female managers’ male subordinates” problem: based on employee table and department table, we want to find out male employees whose 1st-level managers are female.
Below is the relationship between the two tables (there is an association relationship between employee table and department table, and the department table contains a self-association):
This is the SQL written manually:
SELECT A.*
FROM employee A
JOIN department B ON A.dept_id=B.id
JOIN employee C ON B.manager=C.id
WHERE A.gender='male' AND C. gender =' female'
The employee table storing the employees and managers (who are also employees) needs to be associated twice to obtain the query target.
In order to avoid the association, we construct a wide table (emp_width) according to the query’s requirement:

As “special” employees, information of managers needs to be specifically copied from the employee table. No association is needed when conducting query based on this wide table:
SELECT A.*
FROM emp_width A
WHERE A.GENDER='' AND A.mgr_gender='female'
It is easy to implement the “female managers’ male subordinates” query based on such a wide table. There’s nothing particular about it. But if we want to find “male employees whose 1st-level managers and 2nd-level managers are female”, what can we do? The current wide table is not enough to conduct the query, we need to add more fields to it:

Copy information of the 2nd-level managers (who are also employees) again to get a wider table, then we can implement the query based on this single table:
SELECT A.*
FROM emp_width A
WHERE A.GENDER='' AND A.mgr_gender='female' AND A.mgr_gender2='female'
So far, I believe you have been aware of the problem. As the query requirement changes, the wide table needs to be adjusted. Obviously, this deviates from our original intention of designing BI tools (the plan is to achieve flexible queries).
Of course, most of the contemporary BI products also allow users to establish association themselves on the interface side, which is another commonly used way to handle the join queries. But this requires that business users (BI users) be very familiar with the table structure and the relationships between tables and that they possess a certain degree of technical skill.
For the same example, we can also construct the following relationships to query “female managers’ male subordinates”:

We need to select the employee table twice and give them different aliases, and figure out the joining fields between tables. This is difficult for the business people and usually the technical staff is required to first construct the model. It is in essence similar to creating physical wide tables.
It is more complicated to query “male employees whose 1st-level managers and 2nd-level managers are female”:

The employee table is selected three times and department table is used twice. The construction of association has already become complicated. Moreover, some BI products do not support selecting and using one table repeatedly, so we cannot construct such an association to conduct the query.
Even such as seemingly simple “female managers’ male subordinates” problem defeats almost all BI products.
Obviously, this is an invented example. Maybe no one is really interest in it in real-world businesses. But does this mean that the above discussion is meaningless?
Of course not. Though the example itself does not have much business significance, there are many similar join query requirements in real-world businesses. Here we list some of them:
- Query according to call records and mobile account in the telecom industry: find the call records from NY phone numbers to LA phone numbers;
- Query according to sales records and region information in retail industry: get sales in different cities in different regions;
- Aggregation according to orders information (the target cities and the departure cities) in the logistics business: count orders in each city;
- Query according to transaction information, customer information and region information in finance industry: calculate the transaction amount and the number of transactions for each customer in different regions in the specified period of time;
- Query according to oil well information, oil yield information and sensor data in the oil industry: calculate a certain oil well’s average oil and natural gas yield per minute and average temperature in the specified period of time;
- ……
There are all sorts of flexible join query requirements, and the above is just to name a few.
Even if the data structure in this example is simple and only several association relationships are involved, we can still design a lot of scenarios that easily disable many well-known BI tools. In real-world practice, the data structure and the association relationships involved are dozens of, even hundreds of, times more complex. If a wide table isn’t constructed beforehand, it will be beyond the business people’s ability to describe the association relationships. The above simple example also shows that it is impossible to construct a wide table covering all possible query requirements. Any change of the requirement needs a tuning of the wide table. Facing the complex reality, agile BI becomes impossible.
In view of this, wide tables cannot handle the query requirements conveniently. They should not be used if we want to have the flexibility BI tools are expected to achieve. The join query problem needs to be squarely confronted and dealt with fundamentally.
Why the problem has been lingered for so long?
Because SQL is in the way. SQL defines the JOIN oversimply, resulting in too complicated association relationships between data sets, which is beyond comprehension of many business people. In order to solve the problem fundamentally, data organization model at the database level should be changed. Yet, almost all BI products will not re-define the database’s data model. As a result, their join query ability (flexibility) will remain limited.
In-depth Discussion of JOIN Simplification and Acceleration offers comprehensive explanations about JOIN queries.
In an effort to address the problem, we need a set of query syntax that is truly suitable for handling joins.
DQL (Dimensional Query Language) is the SQL-like query syntax specifically designed for BI analyses. DQL categorizes the JOIN operations and eliminates the association action using multiple methods, such as foreign key attributization and homo-dimension table equalization, to convert the multi-table join query to the single-table query.
We can express the “female managers’ male subordinates” query using DQL syntax in the following way:
SELECT *
FROM employee
WHERE gender='male' AND dept_id.manager. gender ='female'
DQL treats the foreign key field values as corresponding records of the dimension table. Part of the second statement expresses “gender of the manager of the department where the current employee works”. By understanding the foreign key values as corresponding records of the dimension table, the dimension table’s fields become the foreign key’s attributes. The field dept_id.manager means “manager of the department where the current employee works” and it is still a foreign key in the department table; fields of the corresponding dimension table records can still be regarded as its attributes and thus there is dept_id.manager.gender, which means “gender of the manager of the department where the current employee works”.
Obviously, the foreign key attributization method is much more natural and intuitive than the filtering on Cartesian product. Regarding the multi-table join operations as slightly complicated single-table operations amounts to getting rid of the join action, even the JOIN keyword, from the syntax of the most commonly seen JOIN operations, making the code much simpler and easier to understand. The frontend webpage developed using this syntax is easy to understand, where the foreign key relationship can be described through “attributization” in any number of layers.
So, we can implement the query of “male employees whose 1st-level managers and 2nd-level managers are female” in DQL as follows:
SELECT *
FROM employee
WHERE gender='male' AND dept_id.manager. gender ='female' AND dept_id.manager.dept_id.manager.gender='female'
In the code, the “foreign key attributization” method is used to convert the multi-table join to a single-table query expressed through multilayer references.
With this method, we can well implement the frontend interface even based on the DQL syntax, which enables us to query data in any layer according to the tree structure. For example, the frontend interface can be designed as follows:
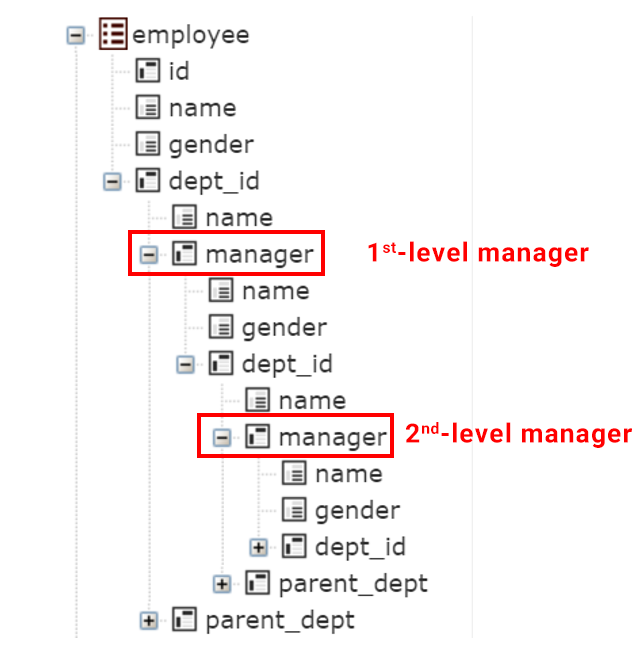
The information of employees, 1st-level managers and 2nd-level managers is displayed in the tree structure, which can expand infinitely, so we can query data in any layer (manager information/department information). The method is easy to understand and use, there isn’t any difficulty for the business people to use it, and the real-time join query problem that has long been plaguing the industry can be satisfactorily solved.
Find detailed information about DQL’s JOIN simplification in In-depth Discussion of JOIN Simplification and Acceleration, which, except for the foreign key attributization, also covers homo-dimension table equalization and subtable set-lization.
DQL handles the real-time multi-table join queries directly, getting rid of the need of using wide tables to bypass the association as well as the inflexible process.
At present, DQL can run based on SPL. DQL works as the semantic layer and directly interacts with the frontend of the application. Users can still use their original application for multidimensional analysis and use SPL as the low-level computing engine to offer high performance. About SPL, view Are Wide Tables Fast or Slow? (SPL has better performance than wide tables).
The BI application framework that includes DQL and SPL becomes like this:
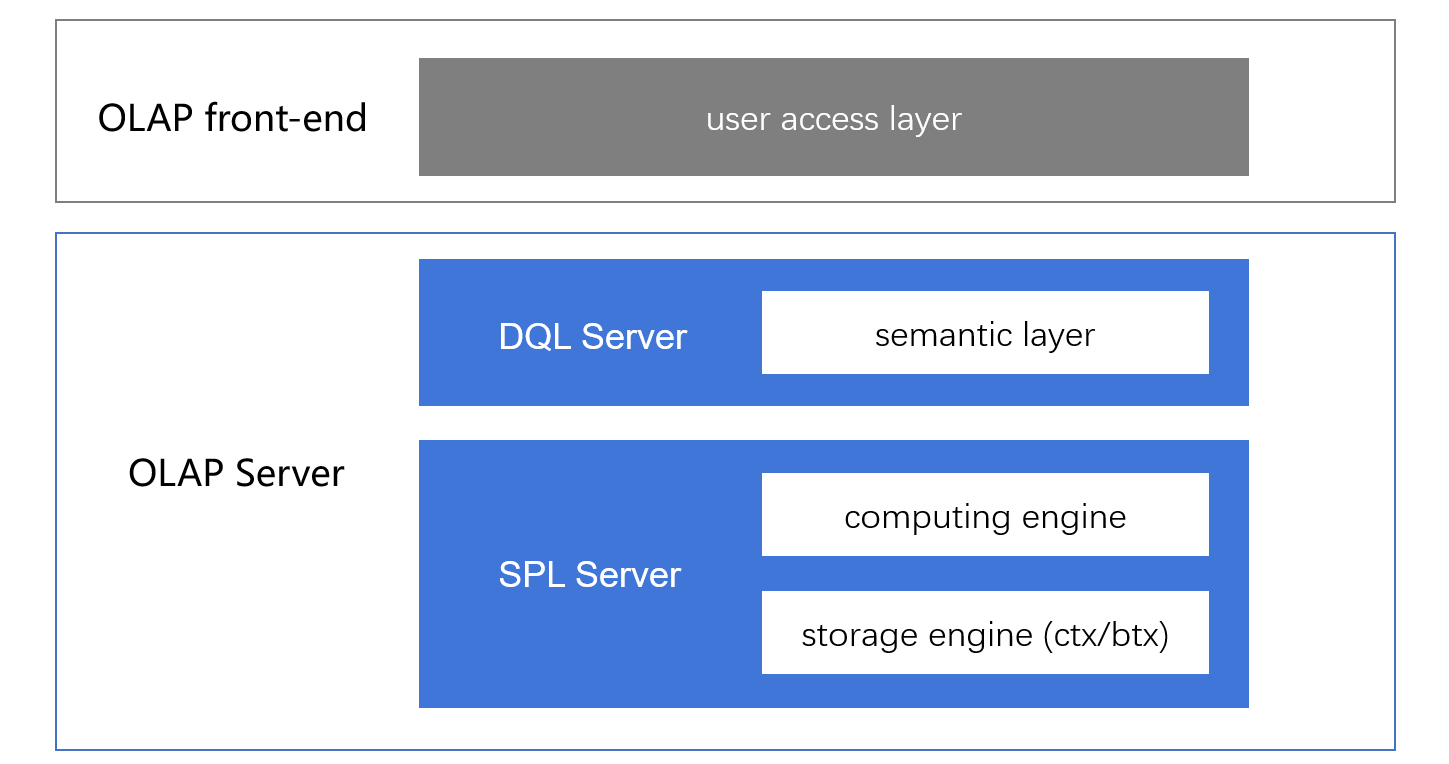
With SPL and DQL, we can conveniently and efficiently handle join queries that are a long-lasting headache, getting a real-time join performance higher than that obtained through wide tables (detailed test data can be found in the related document links). The flexible and high-performance real-time joins help to eliminate problems of the wide tables, including inflexibility, data redundancy, data error (data not conforming to the norm forms) and others, and to put BI tools back to the way it should be.
SPL Official Website 👉 https://www.scudata.com
SPL Feedback and Help 👉 https://www.reddit.com/r/esProcSPL
SPL Learning Material 👉 https://c.scudata.com
SPL Source Code and Package 👉 https://github.com/SPLWare/esProc
Discord 👉 https://discord.gg/cFTcUNs7
Youtube 👉 https://www.youtube.com/@esProc_SPL


Chinese version