

Match the first part of the cell value
An Excel worksheet has multiple columns of source data that contains empty cells, as the following range C3:D19 shows. It also contains data items, which are separated into two parts by "-", used for comparisons, as range F3:F7 shows.
C |
D |
E |
F |
|
3 |
NICK |
NICK-GL |
||
4 |
DAVE |
JOHN-GL |
||
5 |
QUANDEL |
SAM-GL |
||
6 |
ERIC |
LEE-GL |
||
7 |
JOHN |
LEROY-WC |
||
8 |
||||
9 |
||||
10 |
MARK |
|||
11 |
SAM |
SAM |
||
12 |
BLAIS |
|||
13 |
||||
14 |
||||
15 |
LEE |
|||
16 |
||||
17 |
||||
18 |
||||
19 |
LEROY |
LEROY |
Task: Compare each column of the source data with the first part of the data item, and after each column of data, list all matching data items, as shown below:
C |
D |
E |
F |
|
3 |
NICK |
NICK-GL |
||
4 |
DAVE |
JOHN-GL |
||
5 |
QUANDEL |
SAM-GL |
||
6 |
ERIC |
LEE-GL |
||
7 |
JOHN |
LEROY-WC |
||
8 |
||||
9 |
||||
10 |
MARK |
|||
11 |
SAM |
SAM |
||
12 |
BLAIS |
|||
13 |
||||
14 |
||||
15 |
LEE |
|||
16 |
||||
17 |
||||
18 |
||||
19 |
LEROY |
LEROY |
||
20 |
||||
21 |
NICK-GL |
JOHN-GL |
||
22 |
SAM-GL |
SAM-GL |
||
23 |
LEROY-WC |
LEE-GL |
||
24 |
LEROY-WC |
Use SPL XLL to do this:
=spl("=d=transpose@n(?1),transpose@n(d.(E@1(?2).select(d.~.pos(substr@l(~,$[-])))))",C3:D19,F3:F7)
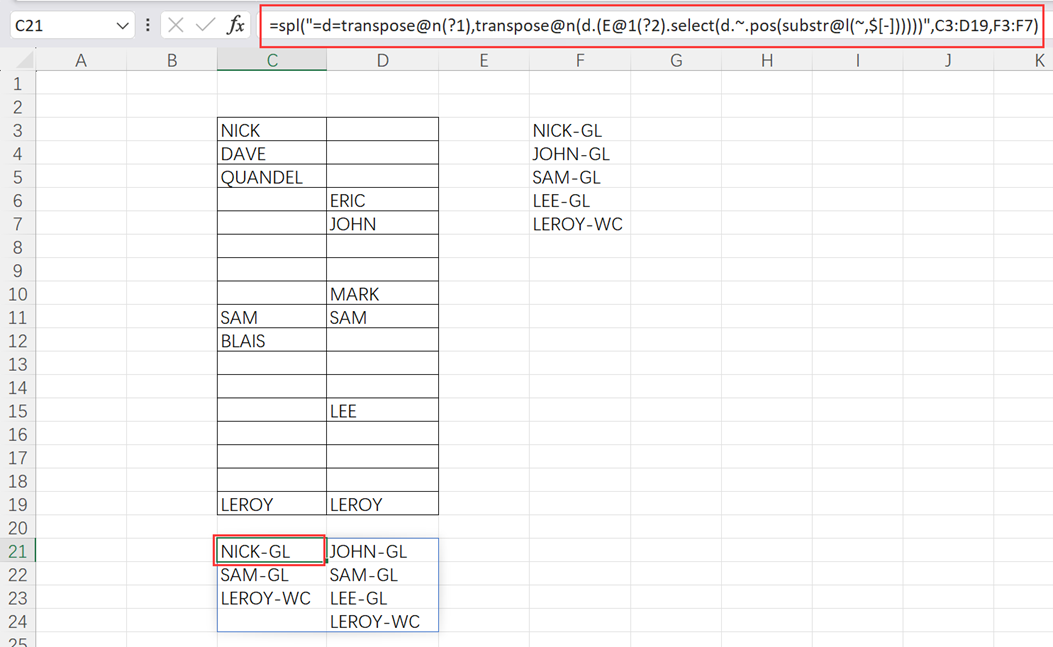
transpose@n function transposes a sequence. E@1 convers a multilayer sequence to a single-layer one. substr@l searches for the specified character in a string and returns the substring before the specified character; here the option is lowercase letter l. pos() function finds whether a sequence contains a certain member or not; ~ represents the current member.
In the above, we use one formula to handle all columns. We can also use the following formula to first handle column C in cell C21 and then drag the formula to the other columns.
=spl("=E@1(?2).select(E@1(?1).pos(substr@l(~,$[-])))",C3:C19,$F$3:$F$7)
SPL Official Website 👉 https://www.scudata.com
SPL Feedback and Help 👉 https://www.reddit.com/r/esProc_Desktop/
SPL Learning Material 👉 https://c.scudata.com
Discord 👉 https://discord.gg/2bkGwqTj
Youtube 👉 https://www.youtube.com/@esProcDesktop
Linkedin Group 👉 https://www.linkedin.com/groups/14419406/

