

Big data technology that is orders of magnitude faster than SQL
SQL often runs very slowly
SQL is still the most commonly used big data computing language, but a fact is that SQL often runs very slowly, seriously wasting hardware resources.
The data preparation part of a bank’s anti-money laundering computation: it takes the 11-node Vertical cluster 1.5 hours to process the 3.6 billion rows of data.
An e-commerce funnel analysis involving 300 million rows: it takes SnowFlake’s Medium 4-node cluster more than 3 minutes to be unable to get a result.
A spatiotemporal collision task involving 25 billion rows: it takes a 5-node ClickHouse cluster 1,800 seconds to complete.
The data volume in each of these cases is not very large, ranging from a few gigabytes to several hundred gigabytes. However, the performance of SQL is not satisfactory.
Are these tasks too complex and can only be so slow? No, the performance is significantly improved after they are rewritten in SPL.
For anti-money laundering data preparation, it only takes SPL single machine 26 seconds to finish, 208 times faster than SQL and surprisingly turning the batch job into a real-time query!
For the funnel analysis, SPL single machine gets the task done in 10 seconds.
And it only takes the SPL single machine 350 seconds, which is 5 times faster, to complete the spatiotemporal collision task.
After switching to SPL, not only does the computing performance increase by an order of magnitude, but the hardware resources are also reduced, turning the cluster into a single machine. In fact, even the code is shorter.
Why can’t SQL achieve this performance?
Explore causes of SQL’s low performance through TOP N problem
Because SQL cannot write low complexity algorithms.
To find top10 from 100 million pieces of data, for example, the SQL statement contains ORDER BY keywords:
SELECT TOP 10 * FROM Orders ORDER BY Amount DESC
This means a sorting is involved. If we really perform the big sorting of 100 million records, the computational workload will be huge.
In fact, as long as we keep a small set of ten records and continuously compare and replace members in the small set when traversing the 100 million records, we can get the top10 at a computational cost 8 times less than that of big sorting! Unfortunately, SQL does not have an explicit set data type, cannot describe such a computing process, but can only write ORDER BY and rely on database optimization. Fortunately, almost all databases can optimize this and use an efficient algorithm, instead of performing the full sorting.
But what if the situation becomes slightly more complicated? For example, if we change the requirement to find the top 10 in each group, the SQL statement would look like this:
SELECT * FROM (
SELECT *,
ROW_NUMBER() OVER (PARTITION BY Area ORDER BY Amount DESC) rn
FROM Orders )
WHERE rn<=10
This is very different from the previous method of getting top10 from the entire set. We need to first use the window function to create intra-group sequence numbers, and then use a subquery to get records meeting the condition. The approach is a bit roundabout.
Anyway, there is still the “ORDER BY”, and the computing logic is still sorting. In actual testing, it is found that for the same amount of data, Oracle’s getting top10 in each group is dozens of times slower than getting top10 from the entire set. Yet theoretically, an extra grouping operation should only make the whole process slightly slower – Oracle is likely to have performed sorting or even external storage sorting.
And the database optimization engine fails each time when faced with slightly more complex cases. It can only execute the SQL logic, which is usually high-complexity, literally, resulting in a sharp decline in performance.
Of course, perhaps one day the database will evolve again and able to optimize such logics. But there are always more complex situations, and the database optimization engine’s reform falls behind the real-world requirements.
More complex object-event tasks
The reason we take TopN task as an example is that it is simple and easy to understand. In real-world scenarios, however, the task is not a frequent encounter. And the TopN problem is so simple that the improved SQL optimizer can cope even if the target is the more complicated intra-group TopN.
The actual computing tasks are far more complex than the TopN problem. All requirements in the previous cases are rather complicated and compute-intensive though they are not data-intensive. SQL cannot describe the efficient algorithms; it can only rely on the database optimization engine, which is often not reliable.
This is a typical object-event problem. The object can be an ecommerce platform, a bank account, a gamer, a mobile phone, a vehicle, etc. It usually has a unique ID, under which all events happened on the object, such as ecommerce system operations, a bank account’s transaction records, phone calls and user operation logs to name a few, are stored.
An object-event problem is also compute-intensive. Examples include computing the churn rate at a specified operation step for an ecommerce platform, the number of transactions whose amount is above $10,000 for a bank account, total transaction amount during holidays, whether each credit card has transactions involving an amount above $1,000 in continuous three days, the sum a gamer spends on a specified equipment, the number of days between a newly-registered gamer’s first login time and the next, and the number of mobile phone calls whose durations are below 3 seconds, and so on.
Such tasks are common and account for more than half of the data analytics scenarios. They all have practical business significance, and a larger part of them involve order-based computations, which are difficult to write in SQL. The code is cumbersome and runs slow.
Let’s find out the causes behind the slow SQL through ecommerce funnel analysis, one the typical object-even problems.
The goal of object-event tasks
The goal of object event tasks is to perform a certain aggregation operation on events that meets a certain condition under each ID, and then the summarization on all IDs.
Specifically, funnel analysis aims to find the maximum number of steps each user can perform in a sequence of given steps within a short time window.
Given three steps, for example: browsing products, viewing details, and confirming order. The aggregate value to be computed is: the number of steps among the three steps each user can perform in order within 3 days. With this value, the number of users who have reached each step can be obtained through a simple count, and then we can further analyze which step has the most severe user churn rate.
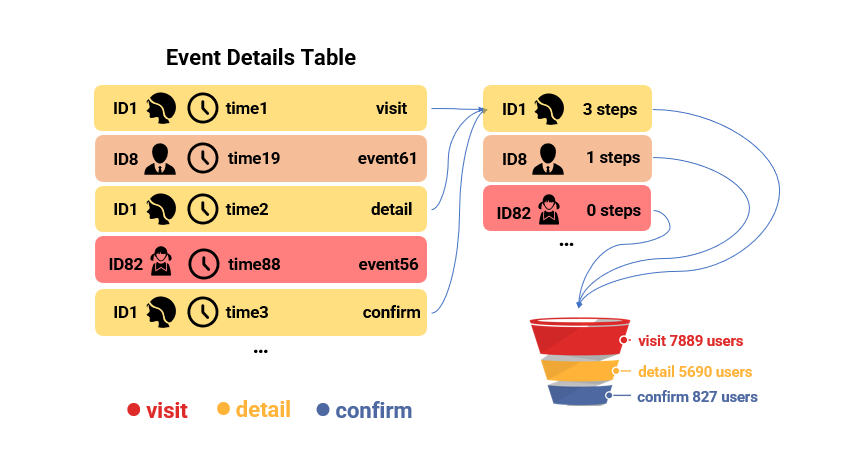
Characteristics of object-event computations
To clarify the SQL difficulty in performing this analysis, let’s first look at the characteristics of object-event computations:
1. There are a large number of IDs, ranging from tens of millions to billions;
2. There are not many events under the same ID, ranging from a few to several thousand;
3. The computations of events are complex and involve a lot of steps;
4. There is no correlation between IDs during the computation.
The SQL logic involves big table JOINs
Complex JOIN operations between object and event involve multiple interdependent event records.
SQL has weak support for cross-row operations, and requires joining multiple rows of records as one row for further operations. Moreover, conditions are defined on the event records, and generally the eligible ones need to be first selected using subqueries before join can be performed. The more events involved in the computation the more subqueries participate in the JOIN.
The three-step funnel analysis, for example, involves multiple records corresponding to ID1. First, use multiple subqueries to get eligible event records, then JOIN multiple rows of records into one row in order to perform further operations.
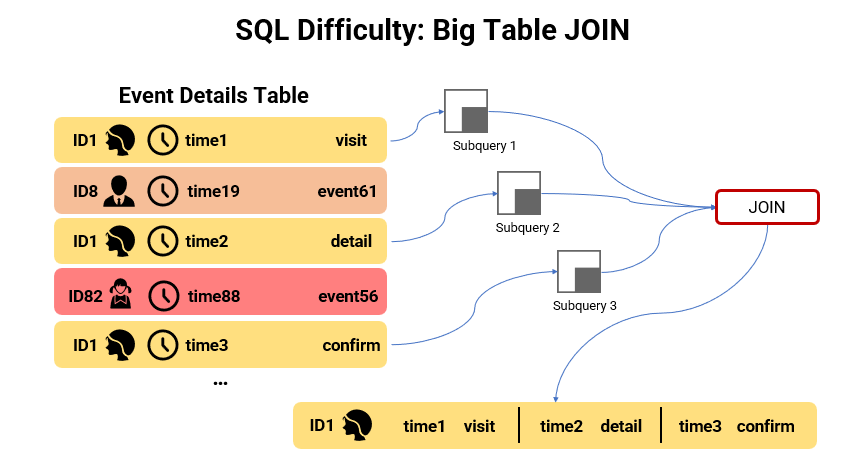
Also, dependence exists between these subqueries. For example, the second-step event needs to be searched for based on the first-step event, and the subqueries themselves also need to be computed using JOIN.
These subqueries are all based on huge event tables. It is already difficult to JOIN them, and even repeated JOINs are needed here. No wonder the execution is slow, and crashes occur.
The SQL logic involves GROUP BY on a large result set
SQL also involves GROUP BY on a large result set when computing the final aggregate value.
Because in the expected outcome, each ID should correspond to one set of aggregate values. But the result of JOIN is different, where one ID may match multiple records. In this case, a GROUP BY operation on ID is needed. As there are a lot of IDs, the performance of grouping operation on this large result set is extremely low and the effect of using parallel processing is unsatisfactory.
Sometimes, the computing goal is to count IDs, and GROUP BY degenerates into COUNT DISTINCT, but the degree of complexity remains unchanged.
The SQL script of handling object-event problem
This is a three-step funnel analysis written in SQL, which includes ID-based big table JOINs, GROUP BY operation and COUNT DISTINCT.
WITH e1 AS (
SELECT userid, visittime AS step1_time, MIN(sessionid) AS sessionid, 1 AS step1
FROM events e1 JOIN eventgroup ON eventgroup.id = e1.eventgroup
WHERE visittime >= DATE_ADD(arg_date,INTERVAL -14 day) AND visittime < arg_date AND eventgroup.name = 'SiteVisit'
GROUP BY userid,visittime
), e2 AS (
SELECT e2.userid, MIN(e2.sessionid) AS sessionid, 1 AS step2, MIN(visittime) AS step2_time, MIN(e1.step1_time) AS step1_time
FROM events e2 JOIN e1 ON e1.sessionid = e2.sessionid AND visittime > step1_time JOIN eventgroup ON eventgroup.id = e2.eventgroup
WHERE visittime < DATE_ADD(step1_time ,INTERVAL +1 day) AND eventgroup.name = 'ProductDetailPage'
GROUP BY e2.userid
), e3 AS (
SELECT e3.userid, MIN(e3.sessionid) AS sessionid, 1 AS step3, MIN(visittime) AS step3_time, MIN(e2.step1_time) AS step1_time
FROM events e3 JOIN e2 ON e2.sessionid = e3.sessionid AND visittime > step2_time JOIN eventgroup ON eventgroup.id = e3.eventgroup
WHERE visittime < DATE_ADD(step1_time ,INTERVAL +1 day) AND (eventgroup.name = 'OrderConfirmationType1')
GROUP BY e3.userid
)
SELECT s.devicetype AS devicetype,
COUNT(DISTINCT CASE WHEN fc.step1 IS NOT NULL THEN fc.step1_userid ELSE NULL END) AS step1_count,
COUNT(DISTINCT CASE WHEN fc.step2 IS NOT NULL THEN fc.step2_userid ELSE NULL END) AS step2_count,
COUNT(DISTINCT CASE WHEN fc.step3 IS NOT NULL THEN fc.step3_userid ELSE NULL END) AS step3_count,
FROM (
SELECT e1.step1_time AS step1_time, e1.userid AS userid, e1.userid AS step1_userid, e2.userid AS step2_userid,e3.userid AS step3_userid,
e1.sessionid AS step1_sessionid, step1, step2, step3
FROM e1 LEFT JOIN e2 ON e1.userid=e2.userid LEFT JOIN e3 ON e2.userid=e3.userid ) fc
LEFT JOIN sessions s ON fc.step1_sessionid = s.id
GROUP BY s.devicetype
The correct way of handling object-event problem
In fact, as long as we can exploit the above-mentioned characteristics, the object-event problem handling is not difficult.
We can sort events by ID. As each ID corresponds to only a few events, we can read all events of one ID into memory at a time. It is easy to implement the complex computation using a procedural language in memory.
Because IDs are unrelated, in-memory joins only happen between events under one ID and there are no big table JOINs. One aggregate value for one ID each time; there is no need to perform GROUP BY ID later, and COUNT DISTINCT will become a simple COUNT. This algorithm not only involves less computations, but occupies less memory space and makes it easy to implement parallel computation.
Unfortunately, SQL cannot implement such an efficient algorithm. This is mainly because SQL lacks discreteness and cannot implement the complex cross-row operations step by step. Moreover, the SQL sets are unordered, and even if data is deliberately stored in an ordered manner, the orderliness cannot be utilized to streamline the computation.
Get TopN in SPL
SQL does not have explicit set data type, and thus cannot describe the low-complexity algorithm mentioned earlier. It can only rely on the database to optimize the statement. SPL, however, handles such a computing scenario at the algorithmic level.
SPL understands getting TopN as an aggregation, same as SUM and MAX, except that the return value is a set. This amounts to implementing the efficient algorithm mentioned earlier. The code is written as follows:
Orders.groups(;top(10;-Amount))
Orders.groups(Area;top(10;-Amount))
There are not the keyword ORDERY BY in these statements, so they do not perform a big sorting but use a small set-based algorithm instead. In addition, the syntax of getting top 10 from each group is basically the same as that of getting top 10 from the entire set, except that there is a grouping key in the latter.
SPL’s way of solving object-event problem
Then let’s look at the object-event problem again, and find it easy to implement the high-efficiency algorithm mentioned above using SPL.
SPL sets are ordered, which enables to store data in order and the use of order-based cursor that can read event data of one ID at a time. The SPL syntax features higher discreteness, making it easy to code stepwise cross-row operations in a natural way of thinking. Here is the SPL code for implementing the same funnel analysis:
A |
|
1 |
=eventgroup=file("eventgroup.btx").import@b() |
2 |
=st=long(elapse(arg_date,-14)),et=long(arg_date),eet=long(arg_date+1) |
3 |
=A1.(case(NAME,"SiteVisit":1,"ProductDetailPage":2,"OrderConfirmationType1":3;null)) |
4 |
=file("events.ctx").open() |
5 |
=A4.cursor@m(USERID,SESSIONID,VISITTIME,EVENTGROUP;VISITTIME>=st && VISITTIME<eet,EVENTGROUP:A3:#) |
6 |
=file("sessions.ctx").open().cursor@m(USERID,ID,DEVICETYPE;;A5) |
7 |
=A5.joinx@m(USERID:SESSIONID,A6:USERID:ID,DEVICETYPE) |
8 |
=A7.group(USERID) |
9 |
=A8.new(~.align@a(3,EVENTGROUP):e,e(1).select(VISITTIME<et).group@u1(VISITTIME):e1,e(2).group@o(SESSIONID):e2,e(3):e3) |
10 |
=A9.run(e=join@m(e1:e1,SESSIONID;e2:e2,SESSIONID).select(e2=e2.select(VISITTIME>e1.VISITTIME && VISITTIME<e1.VISITTIME+86400000).min(VISITTIME))) |
11 |
=A10.run(e0=e1.id(DEVICETYPE),e1=e.min(e1.VISITTIME),e2=e.min(e2),e=e.min(e1.SESSIONID),e3=e3.select(SESSIONID==e && VISITTIME>e2 && VISITTIME<e1+86400000).min(VISITTIME),e=e0) |
12 |
=A11.news(e;~:DEVICETYPE,e2,e3).groups(DEVICETYPE;count(1):STEP1_COUNT,count(e2):STEP2_COUNT,count(e3):STEP3_COUNT) |
A8 reads all events of one ID each time. A9 ~ A12 implements the complex judgment logic. Finally, A12 only needs to perform the simple COUNT for each group, without the need to take care of deduplication.
SPL solution to the long-standing SQL JOIN problem
We can also deal with the long-standing SQL JOIN problem with SQL.
SQL’s JOIN definition does not involve primary keys, though almost all JOINs having business significance are related to primary keys. SQL cannot utilize this characteristic. The use of bilateral HASH JOIN algorithm not only is compute-intensive, but also has uncontrollable performance when external storage or cluster are involved.
SPL redefines JOINs by categorizing them, which enables full use of different primary key-related characteristics to reduce computing amount. This not only leads to fast computation, but gets rid of the uncontrollable issues.
As a result, SPL table joins often outperforms and SQL wide tables.
Let’s dig deeper
On the surface, SQL cannot describe high-performance algorithms as expected because it lacks support for certain operations, such as order-based computations and retaining grouped subsets. But the true reason lies in its oversimple theoretical basis – relational algebra, which lacks necessary data types and corresponding basic operations, if we dig just a bit deeper. Yet, it is normal that a theoretical system born half a century ago is unable to adapt to the contemporary computing requirements.
Can SQL’s low-performance problem be improved through engineering methods?
Distributed and parallel computing, for example, can sometimes improve performance, but the cost is too high.
SQL tuning has limited effectiveness and is not effective for complex situations. Tuning can indeed help adopt certain efficient algorithms by changing the execution path, but many high-performance algorithms do not exist al tall in SQL.
Writing high-performance code using UDF is feasible in principle, but the cost is too high and becomes infeasible. Cluster environments can also bring complex scheduling and operation and maintenance issues. Furthermore, if the database storage scheme cannot be changed, it is difficult to speed up using UDF alone.
In a nutshell, engineering optimization methods cost high but the effect is mediocre. There are almost not effective optimization methods. SQL’s slow execution problem lies in its theoretical base. The engineering optimization can only improve the situation to a limited extent but cannot change it fundamentally.
SPL does not inherit the relational algebra. Instead, it invents the discrete dataset theory with a rich library of data types and basic operations.

The algorithms marked with asterisks here are all original creations of SPL.
Based on the innovative theory and with the toolkit, it is easy to write low-complexity code, fully utilize hardware resources, and achieve high-performance computing that is orders of magnitude faster than SQL.
Besides, SPL provides cluster computing capabilities, but in SPL’s performance optimization cases, it is sufficient to handle most scenarios with a single machine. There are few opportunities to use the cluster computing functionality. That’s why SPL seldom promotes its distributed computing capability.
SPL is now open-source. You can download it in https://github.com/SPLWare/esProc.
SPL Official Website 👉 https://www.scudata.com
SPL Feedback and Help 👉 https://www.reddit.com/r/esProcSPL
SPL Learning Material 👉 https://c.scudata.com
SPL Source Code and Package 👉 https://github.com/SPLWare/esProc
Discord 👉 https://discord.gg/2bkGwqTj
Youtube 👉 https://www.youtube.com/@esProc_SPL


Chinese version