

This Is Probably the Best Exploratory Data Analysis Tool
Exploratory data analysis is important
Many data analysis tasks involve dynamic queries that require flexible analysis and judgment, such as user behavior analysis, product recommendations and inventory optimization based on ecommerce data, and risk assessment and customer categorization in finance industry. All of them are not fixed queries. Analysts need to gradually adjust the analytic operations according to data performance variation so that they can dig up underlying patterns and anomalies. The dynamic analysis approach is the core of exploratory data analysis.

Exploratory data analysis features the flexible guess-and-confirm mode. Unlike the fixed queries, exploratory analysis is a process of repeatedly making an assumption and checking whether it is correct or not. Analysts form a hypothesis based on the preliminary observation of the data and check whether the hypothesis stands the test of data analysis. Each verification result will affect the next analysis step. If the hypothesis is true, it may be further refined. If the hypothesis is false, the analysist will need to switch direction or find the other related factors. One example is the analysis of e-commerce user activity. Initially, the analyst probably guesses that the activity is related to promotion. But the verification analysis result shows that the correlation is low. Then they turn to other factors, such as browsing duration or discount. The repeated iteration helps discover the underlying relationships among data.
The exploratory analysis plays an important role in analyzing data. It allows analysts to flexibly adjust operations to find out new patterns and rules without a predefined frame.
Excel is an exploratory data analysis tool, but…
Excel is an excellent exploratory analysis tool. Supported by easy-to-use operations and outstanding visualization, it allows analysts to instantly check result of each step and adjust the subsequent operation in real-time. Excel is good at implementing the flexible guess-and-confirm procedure in handling simple data analysis tasks in a very intuitive way.
But Excel’s computing ability is not as good. Although it can handle basic table calculations and summarization, it is struggling with more complex tasks. For example, it is difficult to accomplish the following computations with Excel:
• Find users who view products of the same category for at least 3 times in every 7 days to analyze user preference;
• Get the next login time after each 15-minute interval between website operations to analyze user activity;
• Find the specific date when the stock of a certain product lowers below the warning line for more three times to optimize the product inventory.
These computing tasks involve not only complex logic operations, but stepwise computation, conditional filtering and time series processing. This is hard for Excel to deal with.
Then what about using a programming language to implement these complex computations? After all, programming is a universal way.
Try using the SQL or Python that are commonly used among data analysts, for example. Both have a relatively strong computing ability, and can deal with complex data computations to some extent to meet the computing needs during the analysis process. But both have insufficient interactivity, and cannot offer the real-time dialogue experience required by the exploratory analysis. SQL requires executing the whole code and returns the final result after the whole query is completed. This makes it unable to give feedback step by step and have to split the query layer by layer to view an intermediate step. Python has a slightly higher interactivity, but analysts still need to use a special method, such as print, to output an intermediate result. And its analysis process is rather complicated; it is hard to have an exploration experience as smooth as that with Excel.
Also, some tasks do not become necessarily easy even with SQL or Python programming. One example is to get the largest count of consecutively rising days during stock analysis.
SQL:
SELECT CODE, MAX(con_rise) AS longest_up_days
FROM (
SELECT CODE, COUNT(*) AS con_rise
FROM (
SELECT CODE, DT,
SUM(updown_flag) OVER (PARTITION BY CODE ORDER BY CODE, DT) AS no_up_days
FROM (
SELECT CODE, DT,
CASE WHEN CL > LAG(CL) OVER (PARTITION BY CODE ORDER BY CODE, DT) THEN 0
ELSE 1 END AS updown_flag
FROM stock
)
)
GROUP BY CODE, no_up_days
)
GROUP BY CODE
It is even difficult to write such a nested SQL statement by DBA, let alone by analysts.
Python:
import pandas as pd
stock_file = "StockRecords.txt"
stock_info = pd.read_csv(stock_file,sep="\t")
stock_info.sort_values(by=['CODE','DT'],inplace=True)
stock_group = stock_info.groupby(by='CODE')
stock_info['label'] = stock_info.groupby('CODE')['CL'].diff().fillna(0).le(0).astype(int).cumsum()
max_increase_days = {}
for code, group in stock_info.groupby('CODE'):
max_increase_days[code] = group.groupby('label').size().max() – 1
max_rise_df = pd.DataFrame(list(max_increase_days.items()), columns=['CODE', 'max_increase_days'])
The Python code is a bit simpler, but the whole code, which involves loop, is still cumbersome.
Actually, it is not difficult to handle this computing task with Excel. First, sort records by stock code and date; second, write a formula to get the number of consecutively rising dates; third, group records and find the largest number of consecutively rising dates for each group; lastly, collapse the display of data. The task is done in four intuitive steps.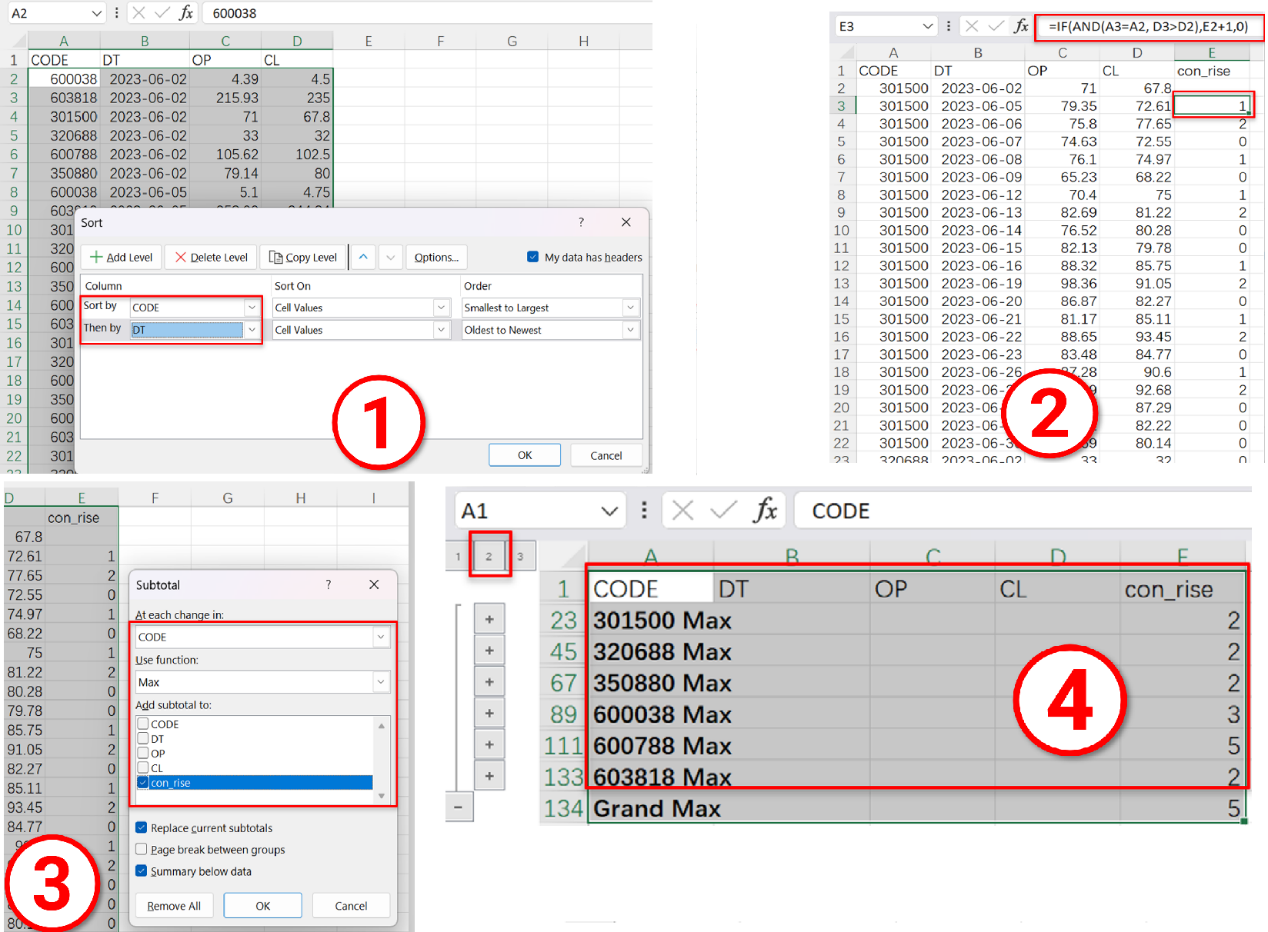
In this sense, SQL and Python’s computing abilities are not that efficient. Sometimes the two languages are even not as convenient as the Excel.
The exploratory analysis requires computing ability and interactivity that are equally good. The computing power should be strong enough to deal with complex computations, and there needs to be high interactivity that allows for real-time adjustment and feedback during the analysis. The strong computing power also helps simplify the complex code – by enabling the use of a simpler algorithm to achieve the computing goal.
SPL is more suitable for exploratory data analysis
Boasting high interactivity and powerful computing ability, data analysis programming language SPL (Structured Process Language) is probably the best choice.
High interactivity
An obvious difference between SPL and the other programming languages is that the former has high interactivity. SPL supports not only step-by-step computations but also checking the result of each step in real-time. The interactive experience is very similar to that with Excel.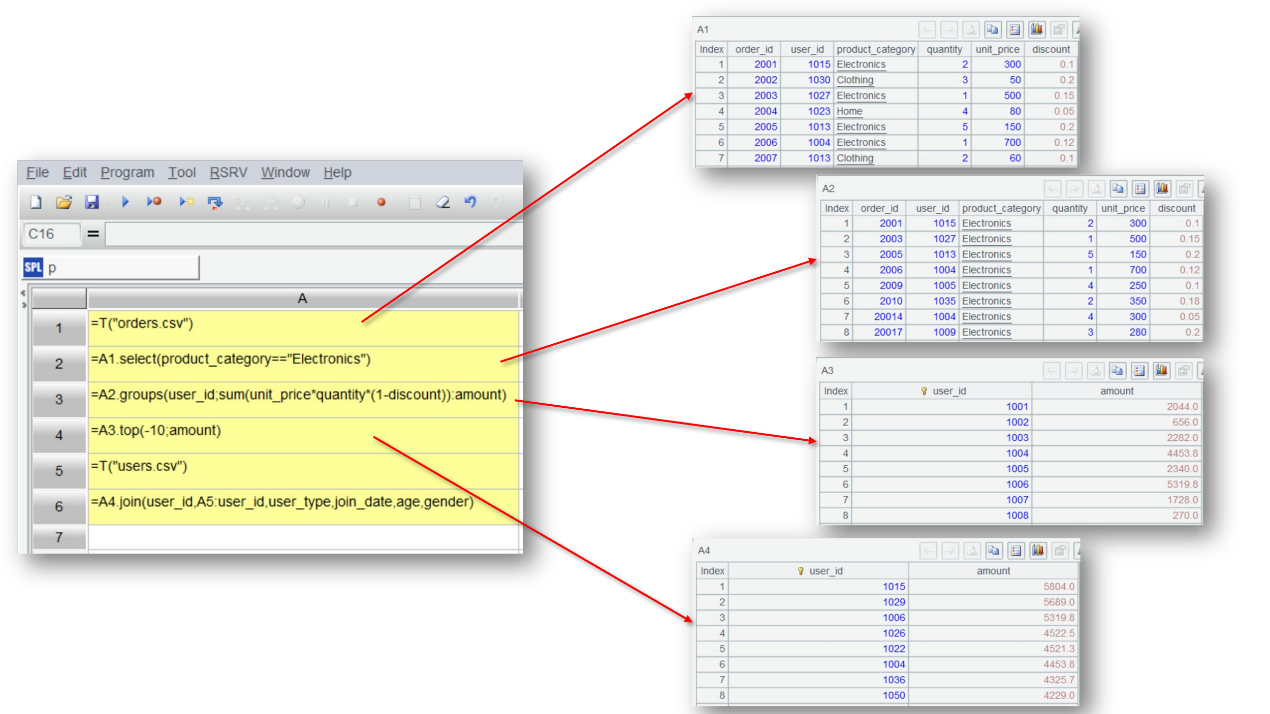 SPL writes code in the grid. The multiple steps are held by different cells. Each cell can reference result of a previous step through the cell name. Click and select a cell to view result of the current step, modify the code if there is any error, and decide which operation the next step will use according to the current result. The process is almost the same as the Excel operations.
SPL writes code in the grid. The multiple steps are held by different cells. Each cell can reference result of a previous step through the cell name. Click and select a cell to view result of the current step, modify the code if there is any error, and decide which operation the next step will use according to the current result. The process is almost the same as the Excel operations.
Here is the SPL integrated development environment (IDE). Beside the mentioned characteristics, SPL also allows executing a step separately. This helps avoid the waste of time brought by repeated execution.
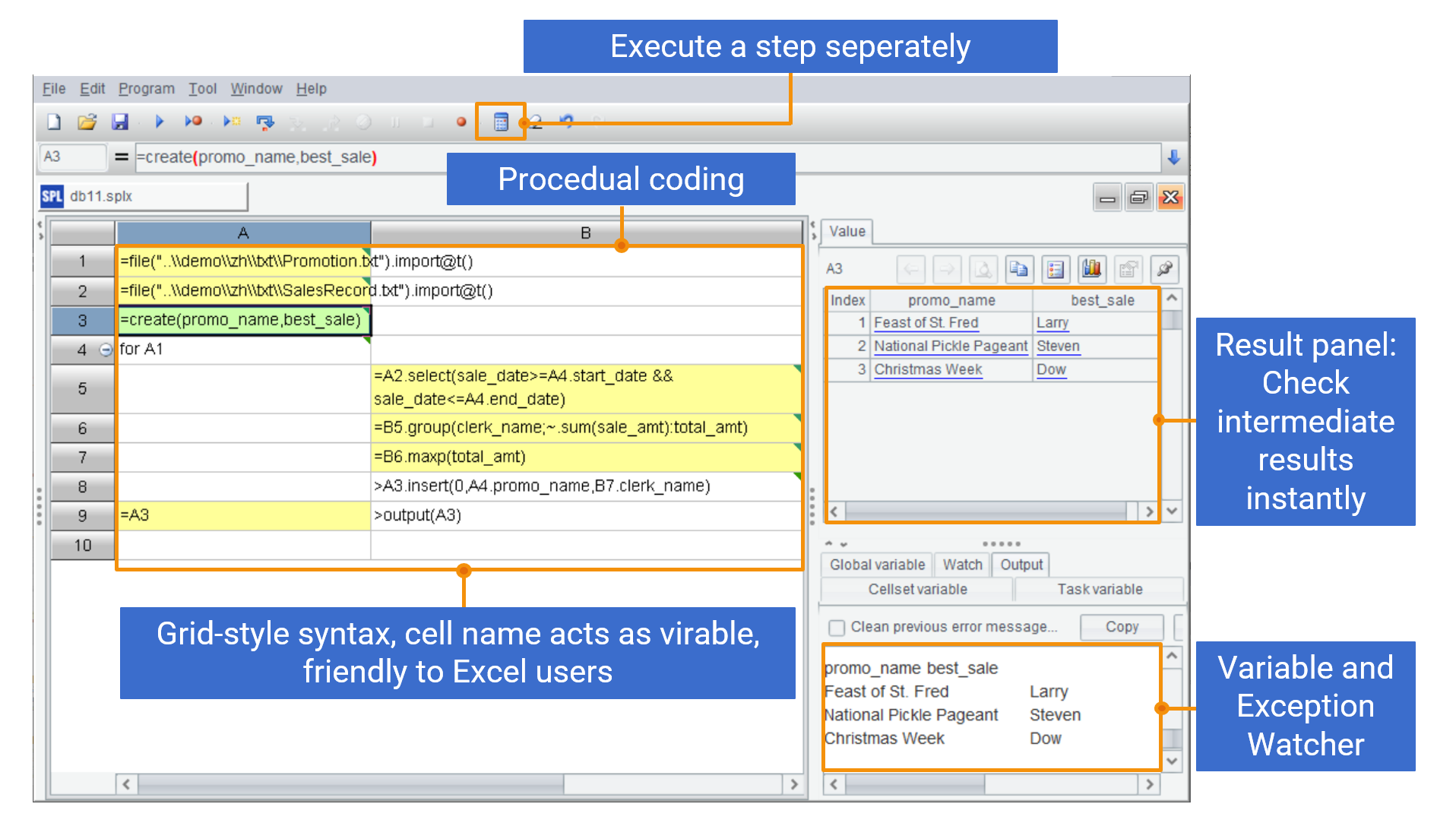
Supported by the stepwise computing procedure, grid-based syntax and cell name reference mechanism, and the visualized panel where users can view each step’s result, SPL is naturally suitable for handling the exploratory analysis.
Strong computing power
In regard of the computing power, SPL offers a rich collection of class libraries and data objects for computing table data. It is particularly good at handling order-based computations.
For example, Excel is simpler than both SQL and Python in handling the task of getting the number of consecutively rising dates for each stock. But SPL produces truly concise code, which has only three lines:
A |
|
1 |
StockRecords.xlsx |
2 |
=T(A1).sort(DT) |
3 |
=A2.group(CODE;~.group@i(CL<CL[-1]).max(~.len()):max_increase_days) |
SPL’s strong computing power is also reflected in performing computations that Excel is not good at. For example, find the star products that rank in top10 in each month according to the given data: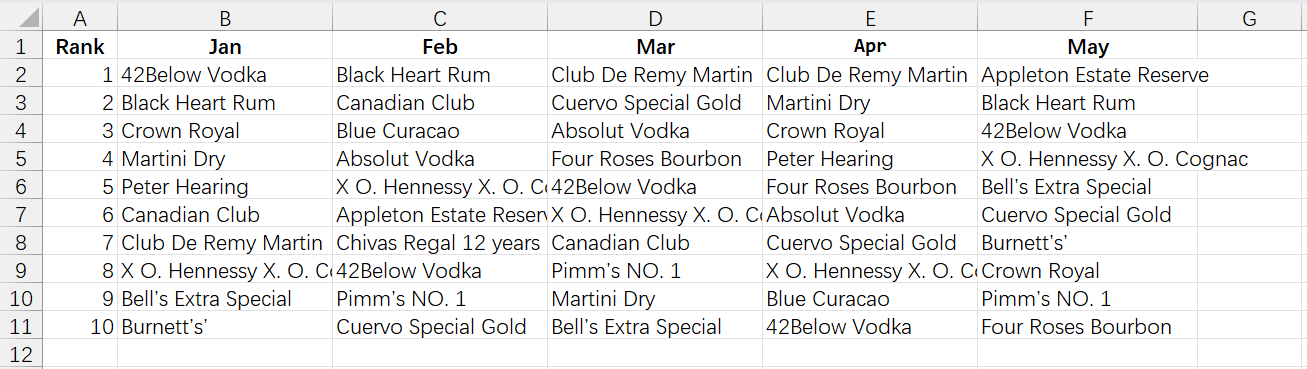
Performing intersection with Excel is cumbersome. But SPL does it in a very simple way:
A |
|
1 |
=file("product.xlsx").xlsimport@w() |
2 |
=transpose(A1).m(2:).isect() |
Excel add-ins
SPL also provides XLL plugin, allowing users to use SPL’s powerful computing ability in their familiar Excel environment. We can directly write a SPL formula in Excel. This leverages advantages of both SPL and Excel.
To perform the above intersection, it is even more concise to write the SPL code directly in Excel: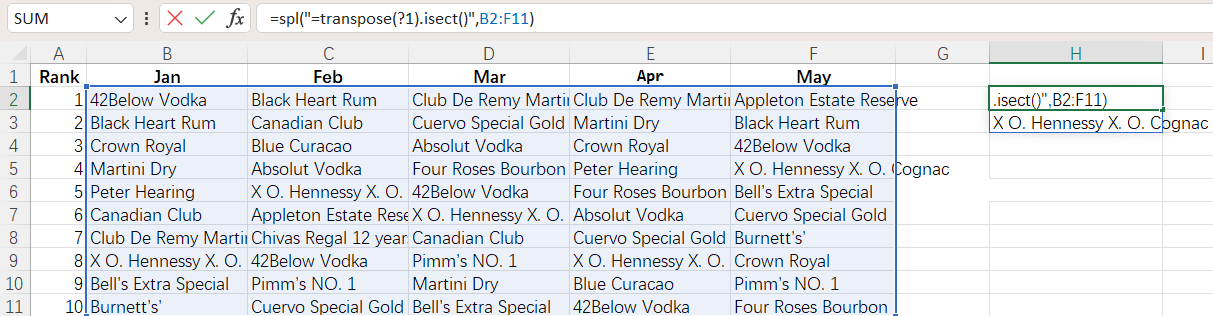
Overall, SPL, with its powerful computing ability and flexible interactivity, is an ideal tool for exploratory data analysis. It not only can simplify complex data processing logics but also supports step-by-step result viewing and code debugging during the analysis process, offering a real-time feedback experience similar to Excel. Compared to the SQL and Python coding style, SPL enables analysts to quickly obtain feedbacks during the process and adjust operations in real-time, truly realizing exploratory analysis. Combining the excellent computing power of programming languages with Excel’s high interactivity, SPL is expected to be the best choice for exploratory data analysis tasks.
SPL Official Website 👉 https://www.scudata.com
SPL Feedback and Help 👉 https://www.reddit.com/r/esProc_SPL
SPL Learning Material 👉 https://c.scudata.com
SPL Source Code and Package 👉 https://github.com/SPLWare/esProc
Discord 👉 https://discord.gg/cFTcUNs7
Youtube 👉 https://www.youtube.com/@esProc_SPL


Chinese version