

A Universal File Format N Times Faster Than CSV
Using csv files to store data is very common. Similar formats include text files, tsv files, etc. These files all have a plain structure—no hierarchy—and store data as text characters. Some xls files also have a similar plain structure.
CSV files have characteristics such as simplicity and strong versatility, but they also have significant drawbacks. Text characters cannot directly participate in calculations, and parsing them to in-memory data types such as dates and real numbers is a very time-consuming process, especially when checking for invalid cases, which makes it even more complex. Therefore, the performance of csv files is consistently poor. The lack of data compression causes csv files to expand in size, take up more storage space, further hinder performance, and also pose challenges to file manipulation and management. In addition, storing high-precision numerical data as text may lose information. Other types of data, such as date-type data and strings containing commas, may also cause errors during parsing. These need to be manually enclosed in quotes and specially handled during parsing to eliminate the errors.
These issues of csv files can all be addressed through the employment of binary format files. However, a universal, simple binary storage format is absent in the industry. Many software applications have efficient binary file formats, but the vast majority are proprietary and do not provide public APIs, thus making them unusable by third parties. While open-source binary formats like Parquet offer public APIs, they are too heavy and require complex environments (such as Hadoop) to function, which makes the application cost too high.
The btx format from the open-source computing engine esProc is a very simple and open binary file format, boasting 4-5 times faster performance than csv files! btx files allow for the direct writing of memory bytes corresponding to various data types; when reading, the bytes are directly retrieved and loaded as in-memory data, without complex parsing processes or validating invalid situations. btx also provides a simple compression method, using an appropriate compression ratio, which can both reduce hard drive space usage to some extent and avoid excessive CPU consumption during reading.
btx covers all functionalities of csv files, and in addition to storing dates, numbers and strings, etc., it also allows for more complex set and record data types, and supports nested data schema.
The utilization of the scripting language SPL provided by esProc makes it easy to implement mutual conversion between btx and csv/DB, which can guarantee the universality of btx.
A |
|
1 |
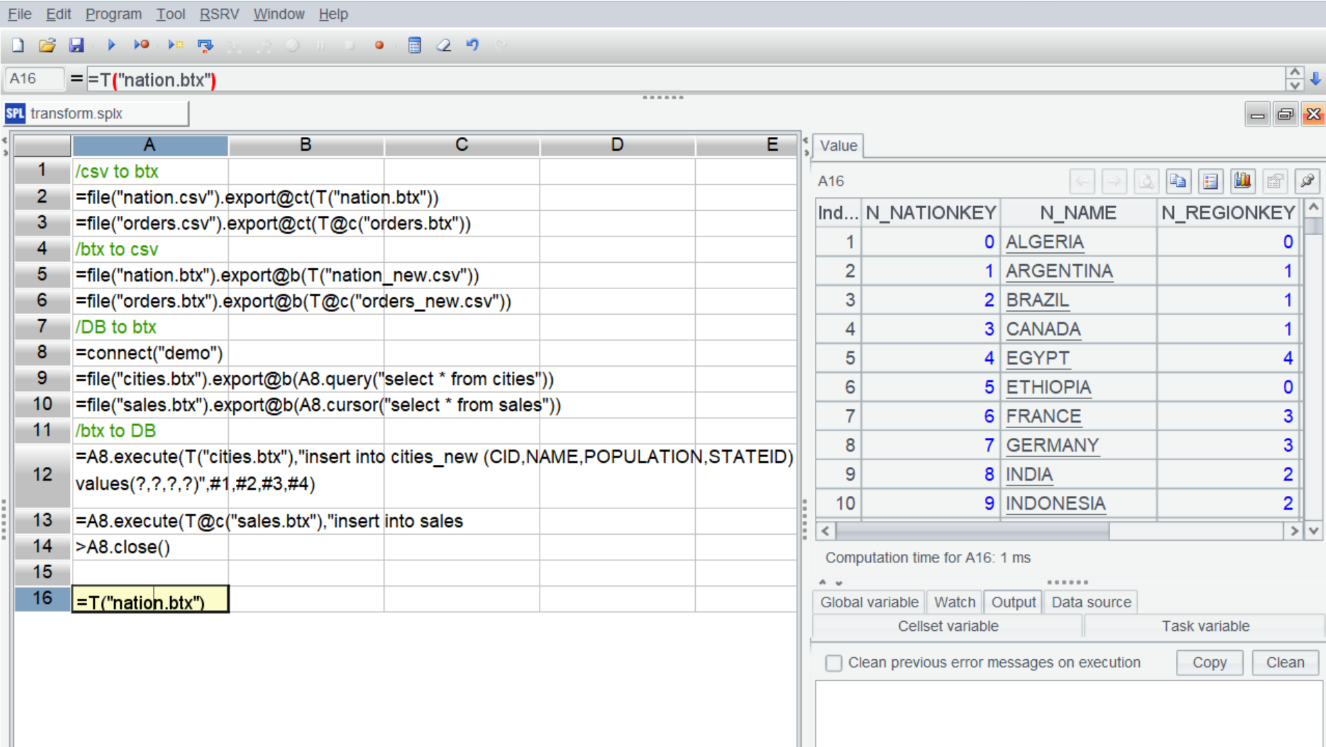
/btx to csv |
2 |
=file("nation.csv").export@ct(T("nation.btx")) |
3 |
=file("orders.csv").export@ct(T@c("orders.btx")) |
4 |
/csv to btx |
5 |
=file("nation.btx").export@b(T("nation_new.csv")) |
6 |
=file("orders.btx").export@b(T@c("orders_new.csv")) |
7 |
/DB to btx |
8 |
=connect("demo") |
9 |
=file("cities.btx").export@b(A8.query("select * from cities")) |
10 |
=file("sales.btx").export@b(A8.cursor("select * from sales")) |
11 |
/btx to DB |
12 |
=A8.execute(T("cities_new.btx"),"insert into cities (CID,NAME,POPULATION,STATEID) values(?,?,?,?)",#1,#2,#3,#4) |
13 |
=A8.execute(T@c("sales_new.btx"),"insert into sales(ORDERID,CLIENT,SELLERID,AMOUNT,ORDERDATE) values(?,?,?,?,?)",#1,#2,#3,#4,#5) |
14 |
>A8.close() |
Besides csv/DB, other data sources can also be mutually converted with btx. Refer to the SPL documentation for details. When converting various data sources to btx, there’s no need to pre-create a data structure; you can directly write to the file, which is very convenient. In cases where the data volume is large, a cursor-based approach for conversion can be employed.
SPL also provides powerful computing capabilities for btx.
A |
B |
|
1 |
=T("nation.btx").select(N_NAME=="CHINA" && like(N_COMMENT,"*express*")) |
/Filter |
2 |
=T("nation.btx").groups(N_REGIONKEY;count(1):nationCount) |
/Group and aggregate |
3 |
=T("nation.btx").select(N_NATIONKEY>10).icount(N_REGIONKEY) |
/Distinct count |
4 |
=T("customer.ctx").select([2,3,5,8].contain(C_NATIONKEY)).top(3;C_ACCTBAL) |
/TOP N |
5 |
=T("nation.btx").keys(N_NATIONKEY) |
|
6 |
=T("customer.btx").switch(C_NATIONKEY,A5:N_NATIONKEY) |
/Foreign key association |
7 |
=T("nation.btx").keys(N_NATIONKEY) |
|
8 |
=T("nation_info.btx").keys(NI_NATIONKEY) |
|
9 |
=join(A7:n,N_NATIONKEY;A8:ni,POPULATION) |
|
10 |
=A9.new(n.N_NAME/"-"/ni.POPULATION) |
/Primary key association |
Here, the T() function is used each time to read btx, which is suitable for various independent calculations. If it’s a continuous multi-step calculation, reading the file once is enough, and subsequent calculations can all be performed based on in-memory tables.
When btx files are large, SPL also supports large file cursor-based external storage computation and segmented parallel computation.
A |
B |
|
1 |
=file("orders.btx").cursor@bm(O_ORDERKEY,O_CUSTKEY).select(between(O_ORDERDATE,date(1996,1,1):date(1996,1,31)).fetch(100) |
/Large file cursor, external storage filtering |
2 |
=file("orders.btx").cursor@bm(O_ORDERDATE,O_TOTALPRICE).groups(O_ORDERDATE;sum(O_TOTALPRICE):all,max(sum(O_TOTALPRICE)):max) |
/Group and aggregate |
3 |
=file("orders.btx").cursor@bm(O_CUSTKEY).total(icount(O_CUSTKEY)) |
/Distinct count |
4 |
=file("orders.btx").cursor@bm(O_ORDERKEY,O_TOTALPRICE).total(top(-10;O_TOTALPRICE)) |
/TOP N |
5 |
= T("customer.btx").keys(C_CUSTKEY) |
|
6 |
=file("orders.btx").cursor@bm(O_ORDERKEY,O_CUSTKEY,O_TOTALPRICE).switch(C_NATIONKEY,A5:N_NATIONKEY) |
/Foreign key association |
7 |
=file("customer.btx").cursor@bm(C_CUSTKEY,C_ACCTBAL) |
|
8 |
=file("customer_info.btx").cursor@bm(CI_CUSTKEY,FUND) |
|
9 |
=joinx(A7:c, C_CUSTKEY;A8:ci,CI_CUSTKEY) |
|
10 |
=A9.new(c.C_ACCTBAL+ci.FUND:newValue) |
/Primary key association, requiring the cursor to be ordered by primary key |
The cursor@b function can define a cursor on btx files for external storage computation. The @m option indicates segmented multi-threaded parallel computation on the btx file, which can significantly improve external storage computation performance.
In the code, the file object file("orders.btx") can be defined once and used repeatedly. However, a cursor can only compute once; each calculation requires the definition of a new cursor. For multi-step calculations, a delayed cursor can be used.
esProc SPL is very lightweight, and its integrated development environment (IDE) is ready to use upon installation, requiring no configuration of various environments like Hadoop, and even less, no cluster is needed.
esProc offers a standard JDBC driver, which makes it easy to embed btx in applications. You just need to place the esProc core jars package and configuration file in the classpath of your Java application and put the btx files in the configured directory, then you can call them.
…
Class.forName("com.esproc.jdbc.InternalDriver");
con= DriverManager.getConnection("jdbc:esproc:local://");
st =con.prepareCall("=T(\"nation.btx\")");
st.execute();
ResultSet set = st.getResultSet();
…
This example uses Java to read and then process btx files. A more recommended approach is to write SPL scripts to handle various btx-related complex calculations, as the amount of code is much simpler than Java. Calling an SPL script (e.g., csv2btx.splx) in an application is also very simple; this Java code requires only slight modification:
…
st =con.prepareCall("call csv2btx()");
st.execute();
…
The esProc core jars package is very small, less than 100MB.
In reporting applications, btx is very suitable for storing buffered report data, as it enables controllable local cache within the application, including partial cache and cache reuse. btx files perform much better than csv files or database temporary tables.
In data analysis scenarios, storing some data from the database in btx files for portability allows you to analyze anytime and anywhere using SPL IDE.
SPL Official Website 👉 https://www.scudata.com
SPL Feedback and Help 👉 https://www.reddit.com/r/esProcSPL
SPL Learning Material 👉 https://c.scudata.com
SPL Source Code and Package 👉 https://github.com/SPLWare/esProc
Discord 👉 https://discord.gg/2bkGwqTj
Youtube 👉 https://www.youtube.com/@esProc_SPL


Chinese version