

Data Analysis from Excel to SPL: Facing Big Data
Excel is an essential tool for daily work, offering quick and convenient data processing, making it very popular. However, its data processing capabilities are not limitless, and when confronted with big data, Excel’s performance becomes inadequate.
For data with several hundred thousand rows, just opening such a large file in Excel will take several minutes. If you perform more complex calculations, then it will become very slow, or even crash. When the data volume exceeds one million rows, Excel will truncate the data due to capacity limitations, making it unprocessable. Therefore, Excel is no longer a suitable tool for big data scenarios.
Then, would using a database work? Databases can handle slightly larger data volume, but regrettably, they are excessively complex and challenging to utilize. Here are the reasons: first, the installation environment is complex, requiring extensive configuration. Even after successful installation, Excel files must be imported into the database as database tables before they can be used. Even though it’s just about processing a single file, it requires installing a database, and importing and exporting data is too troublesome. Second, solving problems with SQL is often more challenging than with Excel, as the code logic often involves multiple layers of nesting, making it quite difficult to write. In addition, SQL debugging is also difficult and not user-friendly.
What about BI? It seems like it should be simpler. BI itself is not difficult to use, but it still relies on databases to handle big data, and also faces the same challenges in environment setup. BI software typically has smooth interactivity and a visually appealing interface, making it appear quite suitable. However, current BI tools are technically limited to multidimensional analysis, and the range of operations they can execute is quite small. Being only a small subset of SQL, many experienced Excel users find it very restrictive.
It appears that the only option is to rely on programming, after all, there’s nothing that can’t be programmed.
Programming languages indeed have more powerful computing capabilities. However, for analysts accustomed to using Excel, most programming languages have poor interactivity and a high barrier to entry. For example, VBA can enhance Excel’s computing capabilities, but its support for structured data is too weak, and programming is too cumbersome. Moreover, VBA does not have built-in big data handling capabilities, requiring manual implementation, which makes programming more cumbersome. Python’s ability to perform table calculations is adequate, but it also lacks direct big data support, which also requires manual implementation. These difficulties are already far beyond the capabilities of Excel users.
So, what is SPL, and is it easy to use?
Yes, SPL can indeed handle big data, and it’s very easy to use, making it very suitable for data analysis.
SPL is also a programming language that excels at handling tabular data and boasts powerful computing capabilities. Moreover, it can handle hundreds of thousands or millions of big data smoothly, and can even compute massive dataset that exceeds memory limits.
Importantly, while SPL is a programming language, its way of working closely resembles that of Excel, offering high interactivity. This makes it exceptionally convenient for Excel analysts, with no special requirements.
Take an example, there is a loan order data with over 2.7 million rows, and we’ll process it using SPL.
Let’s first take a look at SPL interface, as shown in the figure below. On the left is the code/formula area, and on the right is the results area. Clicking on any cell allows you to see the result of that cell, offering high interactivity.
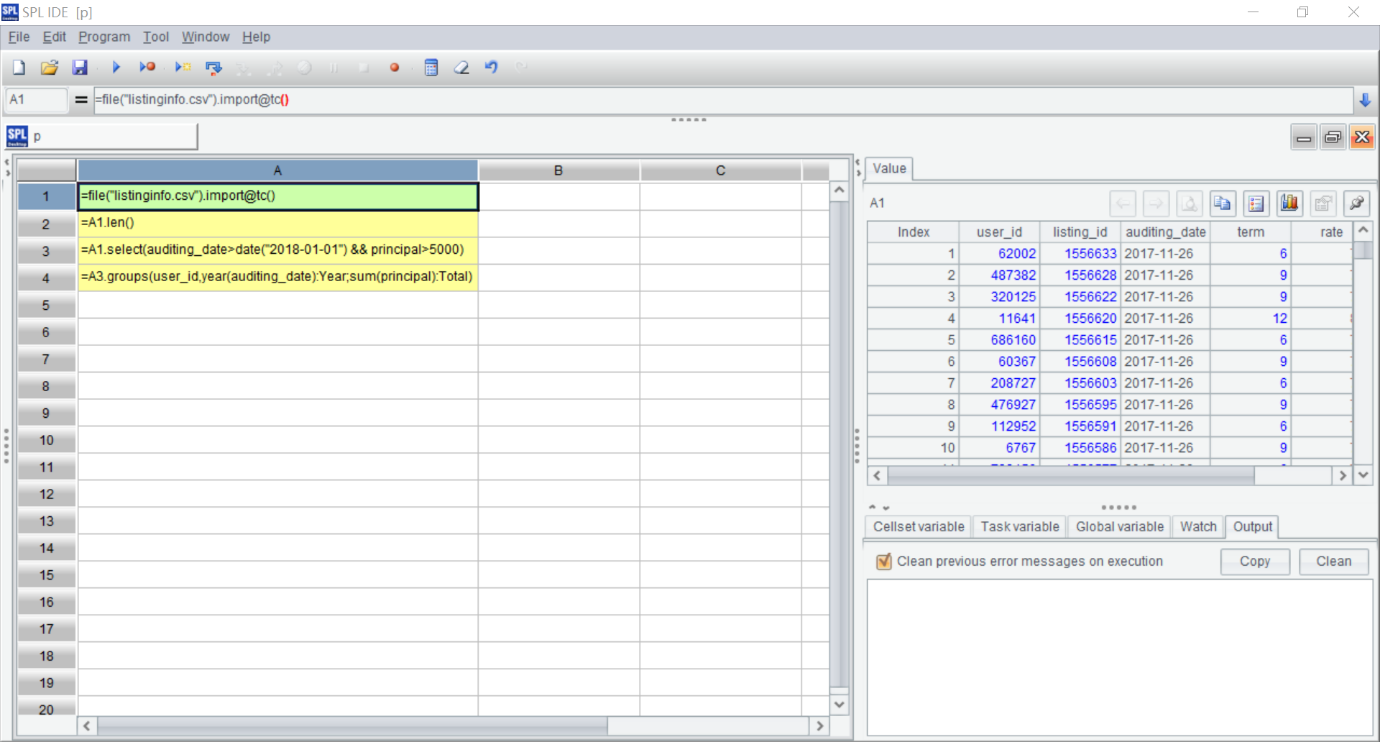
Similar to Excel formulas, SPL code also starts with an equals sign followed by the formula content. For example, the formula in A1 here indicates reading the order file. Following the execution of the formula, you can see the calculation results on the right side of the window, which is the order data. With formulas input on the left and results displayed on the right, the user experience is very intuitive.
Just like in Excel, you can reference other cells in SPL formulas. For example, if you want to see the file’s data volume, you can enter =A1.len() into cell A2, and the results area will show that this is a dataset with over 2.7 million rows. Being able to write and see results simultaneously is remarkably convenient.

SPL’s function syntax is concise and easy to understand.
A |
|
1 |
=file("listinginfo.csv").import@tc() |
2 |
=A1.len() |
3 |
=A1.select(auditing_date>date("2018-01-01") && principal>5000) |
4 |
=A3.groups(user_id,year(auditing_date):Year;sum(principal):Total) |
For example, cell A1’s file().import() is to import the data.
Cell A2 is to calculate the length of data.
Cell A3 is to select data with an order amount principal greater than 5000 for orders placed after 2018.
Cell A4 is to group and aggregate principal by user and year.
Basically, you can get a general idea of what it does just by looking at the literal meaning. The code is intuitive and easy to understand, making it very easy to learn.
Even for extremely large dataset that exceeds memory capacity, SPL can still process them using cursor technology. Writing functions using a cursor is much like writing them in memory, and it’s also easy to code. For example, when using a cursor, the above example would be written like this:
A |
|
1 |
=file("listinginfo.csv").cursor@tc() |
2 |
=A1.select(auditing_date>date("2018-01-01") && principal>5000) |
3 |
=A2.groups(user_id,year(auditing_date):Year;sum(principal):Total) |
The cursor() function in cell A1 indicates that the data is to be read as a cursor. The way other statements are written is largely consistent with how they would be in memory.
In addition, SPL also supports thread-based parallel computing, which takes full advantage of multi-core CPUs. For example, still using the same example, simply adding an m option to the cursor() function will drastically improve performance.
A |
|
1 |
=file("listinginfo.csv").cursor@tcm() |
2 |
=A1.select(auditing_date>date("2018-01-01") && principal>5000) |
3 |
=A2.groups(user_id,year(auditing_date):Year;sum(principal):Total) |
SPL Official Website 👉 https://www.scudata.com
SPL Feedback and Help 👉 https://www.reddit.com/r/esProcSPL
SPL Learning Material 👉 https://c.scudata.com
SPL Source Code and Package 👉 https://github.com/SPLWare/esProc
Discord 👉 https://discord.gg/2bkGwqTj
Youtube 👉 https://www.youtube.com/@esProc_SPL

