

The Triple-layered Reporting Architecture
In conventional reporting architecture, a reporting tool is connected directly to the data source, without a data computing layer in between. Most of the time, the middle layer isn’t needed. Related computations can be handled within the data source and by the reporting tool respectively. But we found during lots of development work that there are certain types of reports for which the computations are not suitable to be handled either within the data source or by the reporting tool. Such types of reports are in the minority, but the development workload for them is huge.
Inability to perform procedural computing
All reporting tools are capable of handling computed columns and data grouping & sorting. Some even provide methods for performing inter-row operations and for referencing cells in relative positions and sets, making complex computations possible.
Reporting tools perform computations in a descriptive mode. This mode lists all expressions on the reporting interface, and executes them in an order automatically determined by their dependency relationship. This is intuitive. The computational target of each cell is clear when the relationship between expressions is simple. The descriptive mode becomes awkward when the dependency relationships are complex and the data preparation involves multiple steps. To make a reporting tool perform computation in a procedural way, hidden cells have to be used, which will both hurt the descriptive-mode computation’s intuitiveness and cause a lot of extra memory usage.
For example, you might want to list clients whose sales account for half of the total sales. Without a special data preparation stage, we must hide the ineligible records using the functionality of hidden rows or columns, but can’t really filter them away. Another example is sorting a grouped report having detailed data by aggregate values. We need to first group data and then sort it, but many reporting tools can’t control the order of grouping and sorting.
Round-off error control is particularly typical. The total of rounded detailed values probably doesn’t equate to the rounded total value of the original detailed values, causing disagreement between the detailed data and the totals. In that case you need to find the appropriate round-off values for the detailed values according to the round-off value of the totals. Though the logic isn’t complicated, reporting tools are helpless even using the hidden cells.
The issue of handling heterogeneous data sources
Years ago, relational databases were the only report data source. Today, the report data source could also come from NoSQL databases, local files, and data downloaded from web servers, etc. These non-relational data sources lack standard interface and syntax for data retrieval; some even don’t have the basic filtering ability. But the filtering operation and even the associative operation are necessary during report development. Reporting tools normally support the two types of in-memory operation, but they can only handle them well when data amount is relatively small. With a large amount of data, the memory will become overloaded. Also, most reporting tools are not good at processing multi-level data such as JSON and XML, and are not able to create dynamic code to access remote web server to get data.
Dynamic data sources are another common demand. Generally the data source the reporting tool uses is pre-configured, and can’t be dynamically selected according to the parameter directly within the reporting tool. For a standard query, reporting tools don’t support using the parameter to control the query condition in the SQL statement for retrieval, but instead often need to replace a sub-clause. Some reporting tools support macro replacement, which makes up for the lack of support for conditional parameters. But the parameter-based calculation of macro value is also conditional and procedural, which is difficult to be handled directly by the reporting tool.
The issue of performance optimization
In previous articles, we mentioned that most of the reporting performance issues need to be addressed during the data preparation stage but many scenarios can’t be handled within the data source. For example, parallel data retrieval should be performed outside of the data source because its purpose is to increase the I/O performance; to achieve the controllable buffer, the buffer information needs to be written to an external storage device, which can’t be handled within a data source; and the asynchronous data buffering and loading data by random page number in building a list report can’t be handled by a data source. Even for an associative query over multiple data sets that a data source can deal with, it would be necessary to get it done outside the data source when multiple databases or a non-database source is involved and when the database load needs to be reduced. Obviously, these scenarios that are not able to be handled within a data source also can’t be handled by a reporting tool.
Solution: Data computing layer
The above issues can be solved by adding a middle layer, a data computing layer, to the conventional double-layer reporting architecture.
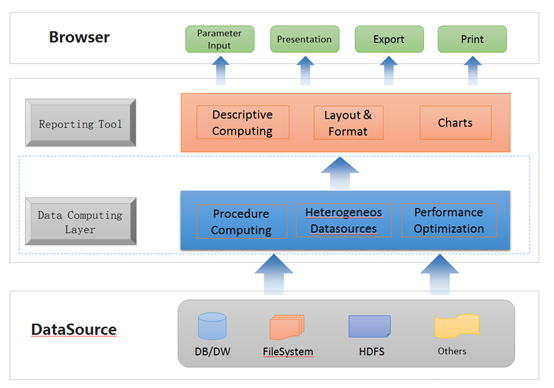
A data computing layer can deal with all those computations mentioned above, leaving a reporting tool to handle the data presentation and a small number of intuitive computing scenarios that the descriptive mode is good at handling.
Though invisible, the data computing layer actually exists in the conventional reporting architecture. Proofs are the uses of the stored procedure of the data source and the reporting tool’s user-defined data source interface. The stored procedure can perform some procedural computations and performance optimizations, but its working zone is within a single database, which is equivalent to processing within the data source. Handling computations that need to be handled outside of the data source is beyond its ability. There are limitations about its application. Theoretically, all problems can be solved by using a user-defined data source, for which almost all reporting tools provide the interface, so the method is used more widely.
Well, is the reporting tool’s user-defined data source functionality convenient enough to replace a data computing layer? That’s our next topic.
SPL Official Website 👉 http://www.scudata.com
SPL Feedback and Help 👉 https://www.reddit.com/r/esProc
SPL Learning Material 👉 http://c.scudata.com
SPL Source Code and Package 👉 https://github.com/SPLWare/esProc
Discord 👉 https://discord.gg/ydhVnFH9
Youtube 👉 https://www.youtube.com/@esProc_SPL

