

Combine columns and deal with duplicate data
There are two cases of duplicate data:
1. Duplicate rows
2. Duplicate key column
When dealing with duplicate data, there are three situations:
1. Only keep one of the same records
2. Only keep records that are not empty
3. Remove all duplicate data
Examples
Example1: Remove all duplicate data when the entire row is duplicate
There is an Excel file 600.xlsx, and part of the data is as follows:

There is an Excel file 100.xlsx, and part of the data is as follows:

The data of 100.xlsx is a subset of 600.xlsx.
Now we need to delete the data in 600.xlsx that also exist in 100.xlsx. The results are as follows:

Write SPL script:
A |
|
1 |
=file("600.xlsx").xlsimport@t() |
2 |
=file("100.xlsx").xlsimport@t() |
3 |
=[A1,A2].merge@d() |
4 |
=file("500.xlsx").xlsexport@t(A3) |
A1 and A2 Read the data of 600.xlsx and 100.xlsx respectively
A3 Remove records of A2 that are duplicated in A1
A4 Export the result of A3 to 500.xlsx
Example2: Keep the records that are not empty and only one of the same records when the key column is duplicate
There is an Excel file book1.xlsx, and the data is as follows:
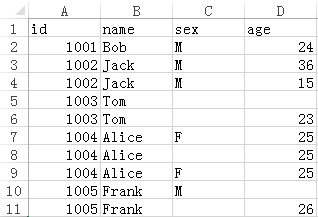
Now we need to remove the records whose sex and age values are both null and keep only one identical record. The result is as follows:
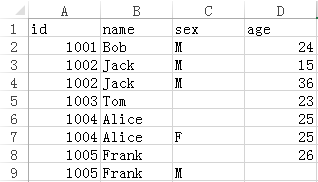
Write SPL script:
A |
|
1 |
=file("book1.xlsx").xlsimport@t() |
2 |
=A1.select(sex||age) |
3 |
=A2.group@1(id,name,sex,age) |
4 |
=file("result.xlsx").xlsexport@t(A3) |
A1 Read the data of Excel file, and the @t option means the first row is the column name
A2 Remove the records whose sex and age values are both null
A3 Keep only one record of all the same records
A4 Export the result to result.xlsx
SPL Official Website 👉 http://www.scudata.com
SPL Feedback and Help 👉 https://www.reddit.com/r/esProc
SPL Learning Material 👉 http://c.scudata.com
SPL Source Code and Package 👉 https://github.com/SPLWare/esProc
Discord 👉 https://discord.gg/ydhVnFH9
Youtube 👉 https://www.youtube.com/@esProc_SPL

