

Which Tool Is Ideal for Diverse Source Mixed Computations
It is common that a contemporary information system has multiple or diverse data sources, especially an analytic application, which often needs to perform data analysis on several sources, sometimes of different types, through mixed computation. There are a variety of data sources, including RDB, NoSQL, files like CSV and Excel, JSON, XML, HDFS, Elasticsearch, Kafka, etc. Implementing a mixed computation on heterogeneous sources is not easy because they vary greatly in their computing ability. RDBs boast powerful ability on which computations can rely on, while NoSQL databases have rather weak computing ability and files do not have any. It is thus believed that a unified technology having independent computing capacity is necessary for dealing with the cross-data-source mixed computation problems.
The well-known cross-data-source computation tools in the industry have various drawbacks. DBLink, a representative of cross-database query solution, is unstable and inefficient and relies solely on databases; Scala is difficult to master and demands all-in-memory computation; Calcite is poor in both functionalities and performance. None is the ideal tool for the cross-data-source job.
Is there a technology that can effectively handle the multiple/diverse mixed computation issue?
Of course. The open-source esProc SPL is exactly what we need.
As a special open-source data computing engine, SPL has an independent computational capability that not only does not rely on any data sources but can access them directly and perform mixed computations.
Diverse data source support and mixed computation ability
SPL supports dozens of data sources directly (the list is growing longer…), and is able to connect to and compute them no matter whether they have any computing ability.

Some of data sources SPL supports
SPL is good at giving full play to each data source’s strengths. On many occasions, it lets the computation-capable RDB handle part of the computation before SPL takes over; it makes use of the NoSQL and file’s high IO efficiency to retrieve data directly from them for computation. it is convenient to use the multilevel MongoDB data; to name a few.
Most importantly, SPL can achieve mixed computations directly based on any data sources. Below is one of the commonly seen cross-database (mixex) computation scenarios:
A |
|
1 |
=oracle.query("select EId,Name from employees") |
2 |
=mysql.query("select SellerId, sum(Amount) subtotal from Orders group by SellerId") |
3 |
=join(A1:O,SellerId; A2:E,EId) |
4 |
=A3.new(O.Name,E.subtotal) |
And the example of full data T+0 query based on the separation of cold data and hot data (mixed computation on file and database):
A |
||
1 |
=cold=file(“/data/orders.ctx”).open().cursor(area,customer,amount) |
/Retrieve data of and before yesterday (cold data) from the file system (high performance SPL storage format) |
2 |
=hot=db.cursor(“select area,customer,amount from orders where odate>=?”,date(now())) |
/Retrieve data of today (hot data) from the production database |
3 |
=[cold,hot].conjx() |
|
4 |
=A3.groups(area,customer;sum(amout):amout) |
/Perform mixed computation to achieve T+0 query |
Example of join query between multilevel JSON/XML data and the database:
A |
||
1 |
=json(file("/data/EO.json").read()) |
Get JSON data |
2 |
=A1.conj(Orders) |
|
3 |
=A2.select(Amount>1000 && Amount<=3000 && like@c(Client,"*s*")) |
Perform conditional filtering |
4 |
=db.query@x(“select ID,Name,Area from Client”) |
Get database data |
5 |
=join(A3:o,Client;A4:c,ID) |
Perform join operation |
Example of computing data coming from a NoSQL database like MongoDB:
A |
|
1 |
=mongo_open("mongodb://127.0.0.1:27017/mongo") |
2 |
=mongo_shell(A1,"test1.find()") |
3 |
=A2.new(Orders.OrderID,Orders.Client,Name,Gender,Dept).fetch() |
4 |
=mongo_close(A1) |
5 |
=db.query@x(“select ID,Name,Area from Client”) |
6 |
=join(A3:o, Orders.Client;A4:c,ID) |
Example of mixed computation on RESTful data and text data:
A |
||
1 |
=httpfile("http://127.0.0.1:6868/api/getData").read() |
Get RESTful data |
2 |
=json(A1) |
|
3 |
=T(“/data/Client.csv”) |
Get text data |
4 |
=join(A2:o,Client;A3:c,ClientID) |
Perform join operation |
SPL performs computations in a uniform way after it connects to data sources and retrieves data from them. That’s the strength of the unified computing capability. Besides the native syntax, SPL also supports the SQL syntax of SQL92 standard to perform cross-data-source computations in SQL.
To compute data coming from both a CSV file and an Excel file in SQL:
$select o.OrderId,o.Client,e.Name e.Dept
from d:/Orders.csv o
inner join d:/Employees.xls e on o.SellerId=e.Eid
And to perform a mixed computation on the MongoDB database and the RDB in SQL:
A |
|
1 |
=mongo_open("mongodb://127.0.0.1:27017/mongo") |
2 |
=mongo_shell@x(A1,"detail.find()").fetch() |
3 |
=db.query@x("select * from main") |
4 |
$select d.title, m.path,sum(d.amount) from {A2} as d left join {A3} as m on d.cat=m.cat group by d.title, m.path |
SPL allows the unrestricted use of both its native syntax and the SQL syntax it supports on any data source, creating universal syntax.
Powerful computational capability and consistent syntax
SPL offers the all-around computing capabilities for handling all structured data computations successfully and rich class libraries, as well as supporting procedural programming. These enable the language to achieve computations in very simple ways.
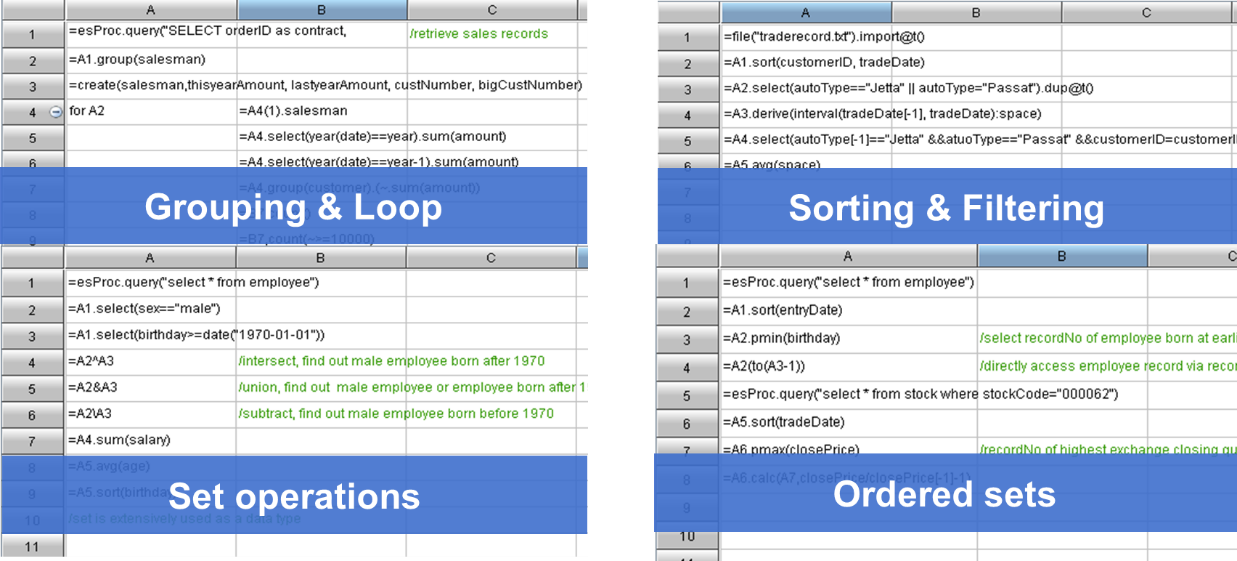
Powered by SPL’s great computational capabilities and consistent syntax, programmers can process data sources in a unified way. Not only can they achieve computations in the same way technologically, but they are able to develop and maintain programs conveniently. There is no specific way of handling a certain type of data source, so the learning cost is reduced. A unified way makes code highly migratable. A data source switch-over involves the modification of retrieval code only, without affecting the main computing logic.
Integration-friendly
SPL provides the standard driver (JDBC/ODBC/RESTful) to be conveniently integrated into an application. SPL can be integrated into a Java application as an embedded engine, supplying the application with diverse data source mixed computing ability.
Below is an example of invoking the SPL code through JDBC:
…
Class.forName("com.esproc.jdbc.InternalDriver");
Connection conn =DriverManager.getConnection("jdbc:esproc:local://");
CallableStatement st = conn.prepareCall("{call splscript(?, ?)}");
st.setObject(1, 3000);
st.setObject(2, 5000);
ResultSet result=st.execute();
…
The interpreted execution SPL supports hot-swap, is integration and development-friendly, and is convenient to be incorporated into the popular microservice framework for data processing – which reduces Java’s computing workload.
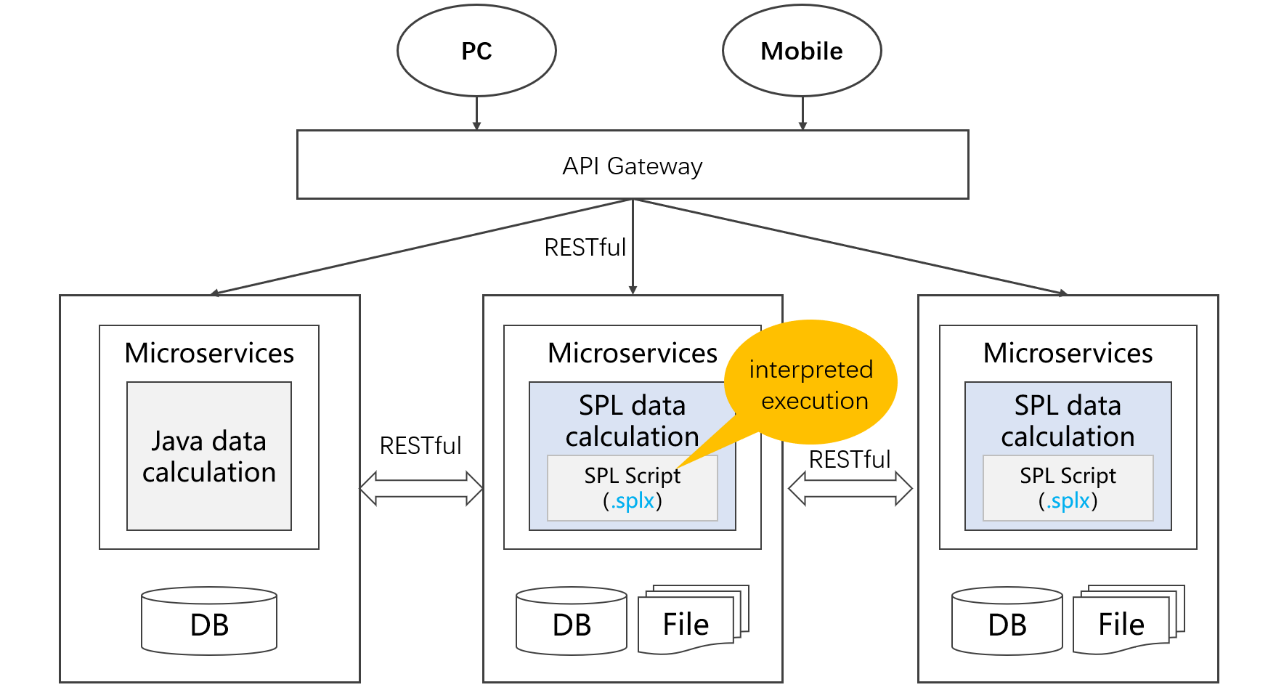
In summary, SPL is versatile, light-weighted and outperforms all other strategies for diverse source mixed computations. It is the most suitable tool for dealing with the contemporary diverse data source computing scenarios.
Extended Reading
Open-source SPL that can execute SQL without RDB
SPL: The Open-source Java Library to Process Structured Data
From JSONPath and XPath to SPL
Open-source SPL: The Sharp Tool for Processing Retrieved Webservice/Restful Data
Handling Excel Files in Java: From POI to SPL
The Open-source SPL Boosts MongoDB Computing Ability
SPL Official Website 👉 https://www.scudata.com
SPL Feedback and Help 👉 https://www.reddit.com/r/esProc_SPL
SPL Learning Material 👉 https://c.scudata.com
SPL Source Code and Package 👉 https://github.com/SPLWare/esProc
Discord 👉 https://discord.gg/cFTcUNs7
Youtube 👉 https://www.youtube.com/@esProc_SPL


Chinese version