

Can’t afford large models, small models are also useful
The most popular topic this year is ChatGPT, which has sounded the horn of the AI large model, with multiple enterprises and institutions rushing into the large model track bombed out by ChatGPT with acceleration. However, this is ultimately a competition among technology giants. Developing large models requires core capabilities such as great computing power, big data and strong algorithms. The technology threshold is high and the investment is large.
Taking GPT-3 as an example, its parameters reach 175 billion, with over 285000 CPU cores, 10000 GPUs, and a 400GB/s GPU server network transmission bandwidth. The computational cost of training the GPT-3 model once exceeds $4.6 million, and even fine-tuning based on open-source large models still has high costs.
In addition to powerful computing power, data itself is also a big investment. According to statistics, GPT-3 uses 300 billion words, more than 40T of large-scale, high-quality data for training. These investments are insurmountable challenges for small and medium-sized enterprises or individuals, and large models cannot be played.
However, while marveling at the power of large models, there are also more and more small models appearing in our vision. These small models may not be as complex as large models, but they also have a very wide range of application scenarios and require relatively small amounts of data in terms of computational resources and operational efficiency consumption. Therefore, even if you can’t afford to play with those large models, it is a good choice to choose small models.
For example, in financial institutions, there may be some historical loan user data information, which may include the borrower’s income level, debt situation, loan amount, term, interest rate, loan repayment situation, and even the borrower’s job position, living conditions, consumption habits, etc. Based on this information, we can build a model to predict whether the user’s loan will default. In this way, when encountering a new loan customer, the probability of the current customer defaulting can be determined based on the matching rules of the customer’s various information. Of course, this prediction cannot guarantee 100% accuracy (there are many ways to evaluate its accuracy), so if only one target (such as only one loan) needs to be predicted, it is meaningless. But usually, we have many cases of targets that need to be predicted, so even if not every case can be predicted correctly, it can still ensure a certain accuracy, which is still very meaningful. For loan business, the predicted high-risk customers may not necessarily be true, but as long as the accuracy is high enough, it can still effectively prevent risks. Building such a small model does not require feeding massive amounts of data like GPT, and can make good models with tens of thousands of pieces of data. Of course, it does not require too much computing power, and even a laptop can do.
In fact, these small models have performed very well in many practical applications. For example, precision marketing of products, risk assessment of credit users, optimization management in industrial production, disease diagnosis in medical treatment, and so on. Many commonly used business prediction scenarios can be implemented by small models.
Of course, small models are not innate and require the efforts of data scientists. Firstly, similar to large models in mathematical principles, it is difficult to learn and requires professional talents. Secondly, the modeling process is not overnight and requires repeated debugging and optimization. Moreover, the data preprocessing process is also very complex, such as data noise, missing values, high skewness distribution, etc. In addition, if the data sources are different or relatively primitive, it often requires some tedious preparation work. A set of processes can take as little as a week or two to several months, and require the participation of data scientists, which is time-consuming and labor-intensive. However, it is gratifying to note that there are many ready-made automation tools available for building small models, which can improve work efficiency and lower the threshold for modeling talents.
SPL is precisely such a useful tool, which has a library that can implement complete automated modeling. After configuring the external modeling library, simple function invocations can be used to achieve automatic modeling. There is no need to spend time preprocessing data and debugging models, and both ordinary programmers and modeling beginners can use it. Training small models in SPL requires not much data, and even tens of thousands of pieces of data can build a useful model. It can run well in a few minutes, which is simple and convenient.
Taking the classic Titanic survival prediction data as an example, a model can be built with a few simple lines of code:
| A | |
|---|---|
| 1 | =file(“titanic.csv”).import@qtc() |
| 2 | =ym_env() |
| 3 | =ym_model(A2,A1) |
| 4 | =ym_target(A3,“Survived”) |
| 5 | =ym_build_model(A3) |
Then you can view the model’s performance:
| A | |
|---|---|
| … | |
| 6 | =ym_present(A5) |
| 7 | =ym_performance(A5) |
| 8 | =ym_importance(A5) |
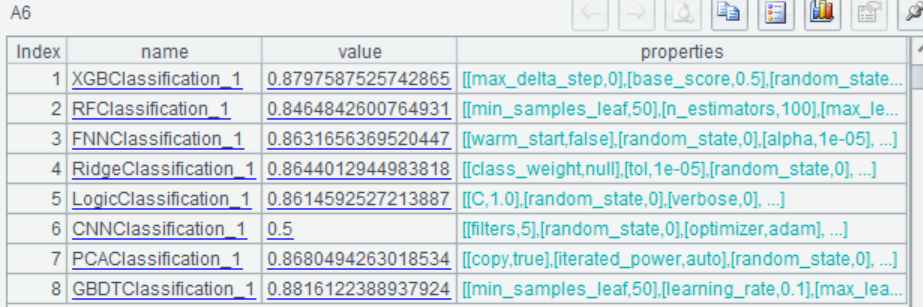
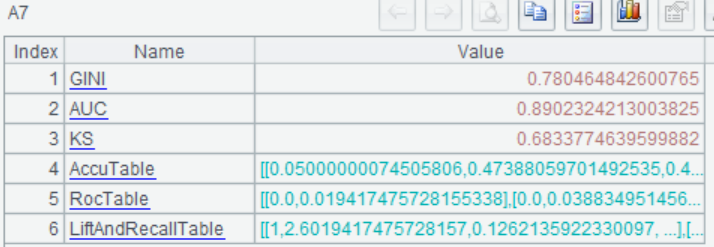
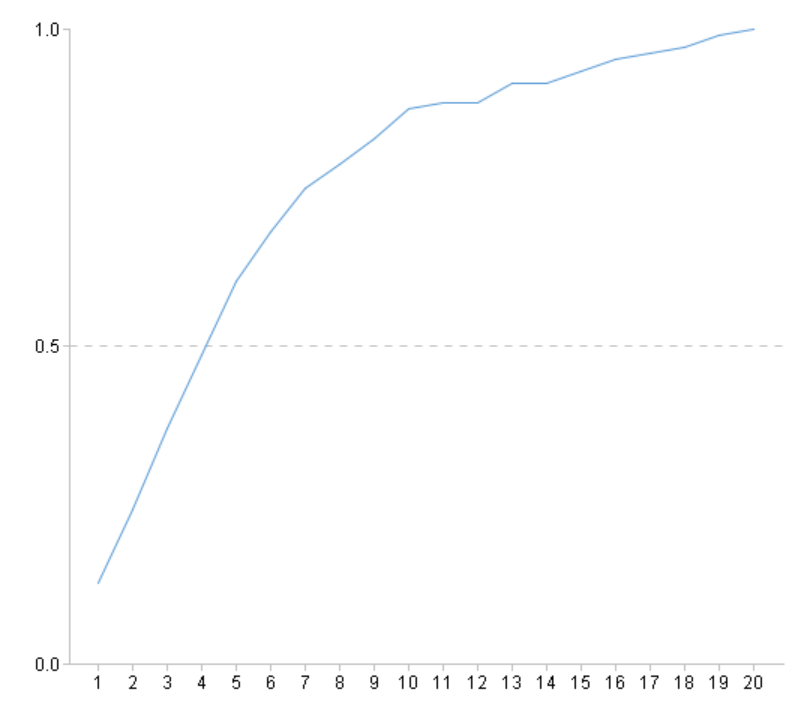
Then use the model to predict the probability of survival for each passenger:
| A | |
|---|---|
| … | |
| 9 | =ym_predict(A5,A1) |
| 10 | =ym_result(A9) |
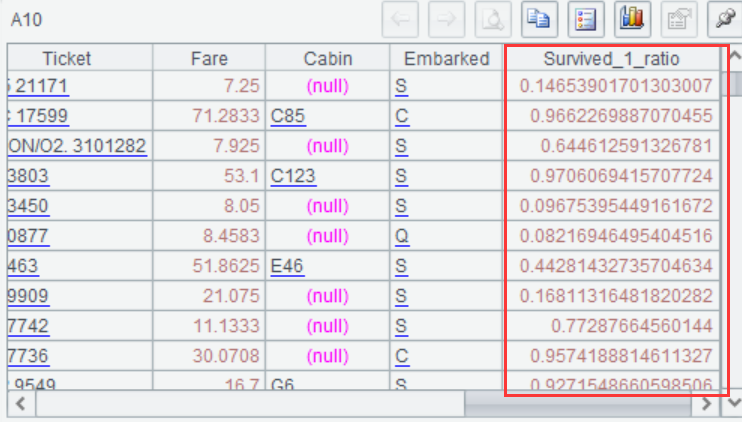
For the complete process, you can refer to: Data mining, modeling and prediction in SPL
In many practical businesses, the small models built by SPL have performed well, providing strong support for production practice activities.
For example, banks have many types of financial products and a large number of users, so it is particularly important to market the right products to the right users. Traditional marketing methods are inefficient and have a low success rate. Therefore, the bank hopes to fully tap into the list of potential customers, recommend financial product portfolio packages, and conduct synchronous marketing of multiple product combinations for target customers, in order to consolidate the customer-centric business system and highlight the comprehensive operation of key customer groups.
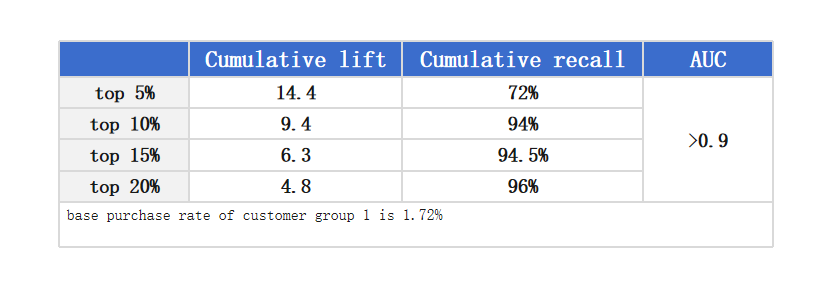
We use the bank’s own data, including users’ basic personal information, asset information, consumption data, etc, then, with the help of SPL’s automatic modeling function, build models based on multiple target products and multiple customer groups (which can be large customer groups of millions or small customer groups of thousands), and the purchase list of key customer groups is successfully predicted. Taking a certain customer group as an example, based on the effectiveness of the model, the purchase rate can be increased by 14.4 times, and 72% of the target customers can be captured on 5% of the data. After practice, the daily average growth rate has increased by more than 70 times after using the model.
For another example, in the fiercely competitive car insurance market, insurance companies hope to establish more accurate pricing models to help them more accurately locate customers. On the one hand, utilizing price elasticity to bring more low-risk customers at a lower premium, and on the other hand, preventing more high-risk customers at a higher premium, thereby improving profit margins. We used the basic information of the policy and historical accident situations to model it, and developed a new pricing model using a combination of GLM and neural networks, which improved the GINI performance based on compensation by 12% compared to the original pricing model. Significantly improved the performance of pricing models, maximizing the returns of insurance institutions.
In the above two cases, we all used the automatic modeling function of SPL. A series of processes, such as data preprocessing, model selection and parameter adjustment, and model evaluation, are automatically completed by the software, which is simple and convenient to operate.
In addition, SPL also has powerful structured computing capabilities, interactive programming methods, and convenient data preparation, making it simpler to use than SQL and Python. Comparison between SPL and Python in processing structured data
In summary, although the performance of large models is impressive in many aspects, we cannot ignore the excellent performance of small models. Whether in terms of computing resource consumption or practical application scenarios, small models can be a good choice for us. Building one’s own large model requires a significant investment of time, manpower, and funds, as well as facing challenges and difficulties in multiple fields. Enterprises should measure which model to choose based on their actual situation and needs.
SPL Official Website 👉 http://www.scudata.com
SPL Feedback and Help 👉 https://www.reddit.com/r/esProc
SPL Learning Material 👉 http://c.scudata.com
SPL Source Code and Package 👉 https://github.com/SPLWare/esProc
Discord 👉 https://discord.gg/ydhVnFH9
Youtube 👉 https://www.youtube.com/@esProc_SPL


Chinese version