

How to store and calculate historical big data with lower usage frequency
The usage frequency of historical data often decreases over time, and how to store and calculate it becomes a problem.
Low frequency of use does not mean that it is no longer used at all. If all these data are archived from the database, they must be imported into the database again when querying statistics, it is time-consuming and labor-intensive. There is often an awkward situation where the query takes only 3 minutes but the import takes 3 hours.
It’s not feasible to keep these data occupying database space. Many enterprises use commercial databases, which are not cheap in terms of usage and space. Even with open source and free products, it is very troublesome to operate and maintain one (or even multiple) database that is always alive (which can be shut down but cannot be uninstalled). The data entered into the database cannot be moved arbitrarily, and the corresponding database engine must always be bound to it. Anyway, this is a high-cost matter, but the usage rate is very low.
It’s okay if the amount of data is small, but when the amount of historical data accumulates to a large extent, it becomes a dilemma. Saving to the database is not suitable, and not saving to the database is also not suitable.
There are two reasons causing this result: 1. The computing capability in the application is currently mainly provided by the database, and to calculate data, it needs to rely on the database; 2. A database is usually a closed system that does not separate storage and computation, and cannot simply use its computing power to arbitrarily calculate specified data.
Then, to solve it, we also start from these two aspects: 1. A computing engine that does not rely on a database; 2. A computing mechanism capable of storing and calculating separately.
Using a cloud data warehouse with storage and computing separation is a solution. The data is always loaded into the database and can be calculated at any time. Low frequency usage consumes less computing resources and costs less. However, cloud data warehouses are still logically closed, and managing too much historical data in the same warehouse can easily cause confusion. The operation and maintenance costs of splitting into multiple warehouses will increase, and also making it difficult for mixed calculations. In some scenarios, it is not convenient to move data to the public cloud due to security reasons, and building a cloud database with storage and computing separation within the enterprise would be too heavy.
esProc SPL is a better lightweight solution that can simultaneously meet the two aspects mentioned above, namely, not relying on the computing capability of the database and the natural storage and computing separation mechanism.
esProc SPL is an open source computing engine developed purely in Java, which can seamlessly embed into Java applications and provide powerful computing capability that does not rely on databases.
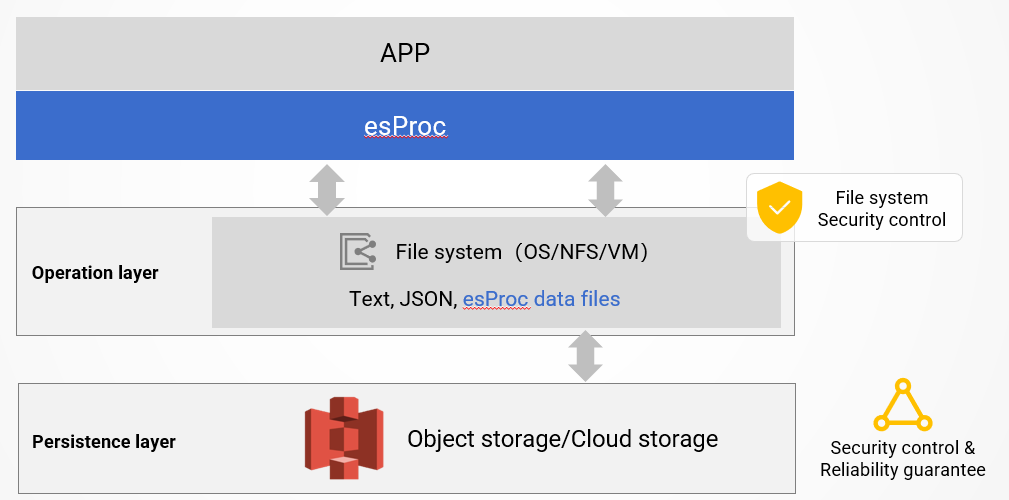
We know that files are the cheapest and most convenient storage solution. Historical data usually does not change, and there are no longer coupling issues of constraints and consistency between data. After being saved as files, it is easy to manage in directories and can be moved according to the situation. For example, storing in a network file system, HDFS, or cloud storage for sharing capabilities and superior reliability.
esProc SPL can store historical data into files and provide computing capability on the files.
esProc SPL has designed a high-performance binary file format. Supports compression, columnar storage, indexing, as well as cursor and segmented parallelism mechanisms for big data, as well as unique ordered storage formats. SPL provides a rich structured data operation library and many high-performance algorithms that traditional data warehouses do not have, making it easy to write code with higher performance by orders of magnitude, completely replacing all the computing power of data warehouses.
The data files calculated by esProc SPL can be placed in any place that can be accessed by the program, whether it is a local file system, network file system, HDFS, or cloud storage (S3). As long as permissions are given, they can be calculated by esProc SPL. esProc SPL itself is a computing engine that naturally supports the separation of storage and computation. Based on these mature third-party storage solutions, the reliability, security, and convenient sharability brought by these technologies can be fully utilized.
esProc SPL also has built-in support for a very rich range of external data sources:

This can facilitate data exchange between esProc files and external data sources, as well as perform calculations for mixed data sources:
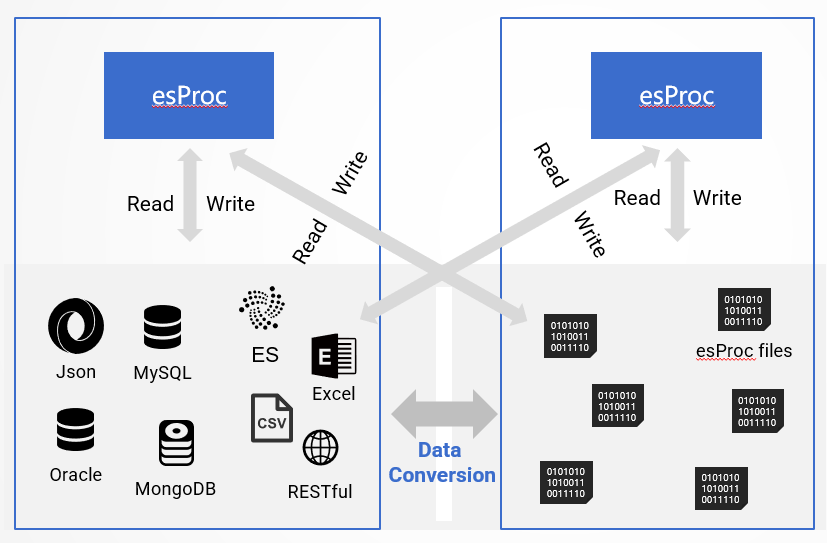
As a computing engine, esProc SPL does not “own” data like traditional databases, and all accessible data files (or other data sources) can be calculated and considered “belonging to” esProc. esProc does not have the concept of “(data)base”, and there is no distinction between “in the database” and “out of the database” data. Of course, there are no actions for “loading into database” and “exporting out of database”: Data warehouse with “no house” performs better than the one with “the house”
esProc SPL can be understood as a data warehouse running on a file system: Data warehouse running on file system, and it is also a very lightweight big data technology solution: Lightweight big data processing technology. Based on esProc, data warehouses can be abandoned and big data computing can be implemented in a lower cost and more flexible way.
Very specifically, SPL code is written in a grid, which is very different from the code typically written as text. The independent development environment is simple and easy to use, providing single step execution, breakpoint setting, and WYSIWYG result preview. Debugging and development are also more convenient than traditional databases and Java.
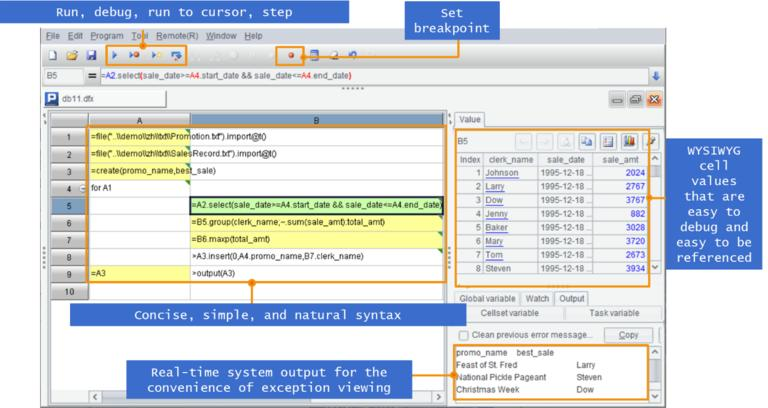
Here A programming language coding in a grid is a more detailed introduction to SPL.
Finally, esProc SPL is here https://github.com/SPLWare/esProc .
SPL Official Website 👉 http://www.scudata.com
SPL Feedback and Help 👉 https://www.reddit.com/r/esProc
SPL Learning Material 👉 http://c.scudata.com
SPL Source Code and Package 👉 https://github.com/SPLWare/esProc
Discord 👉 https://discord.gg/ydhVnFH9
Youtube 👉 https://www.youtube.com/@esProc_SPL


Chinese version