

Front-end calculation of BI
A certain organization has established a distributed data warehouse, gradually loading historical data into the warehouse, and then building a BI system based on the data warehouse (mainly for multidimensional analysis). At first, everything went smoothly, but over time, there were more and more applications based on central data warehouse, and over the years, dozens of applications were accumulated. These applications all rely on data warehouse for calculations, leading to an increasing burden on the central data warehouse and a sluggish response of the BI system. For multidimensional analysis businesses requiring strong interactivity, this is hard to tolerate.

What should to be done?
Expanding is not realistic. This is already a distributed system, and the number of nodes has reached the limit of an MPP data warehouse. Adding more nodes will not have a significant performance improvement.
It is also impossible to replace the data warehouse, even if there are products with better performance tested, you dare not replace it. Dozens of applications need to be retested one by one, otherwise no one can guarantee that these applications will still work properly after changing the data warehouse. This requires coordinating many departments to get started. Moreover, products that perform well in multidimensional analysis testing may not necessarily perform better for other applications, and may also lead to poorer response times for other applications.
The selection of a central data warehouse is a significant political task for many organizations, and it is unlikely to be easily replaced solely for a specific application issue.
The central data warehouse cannot be replaced at the moment, so only the solution on the application side can be adopted . A common way is to use front-end computing, which places the required data on the application side and allows the application program to calculate it directly without requesting a central data warehouse. The commonly used technique is to place a front-end database on the application side to provide storage and computing power.
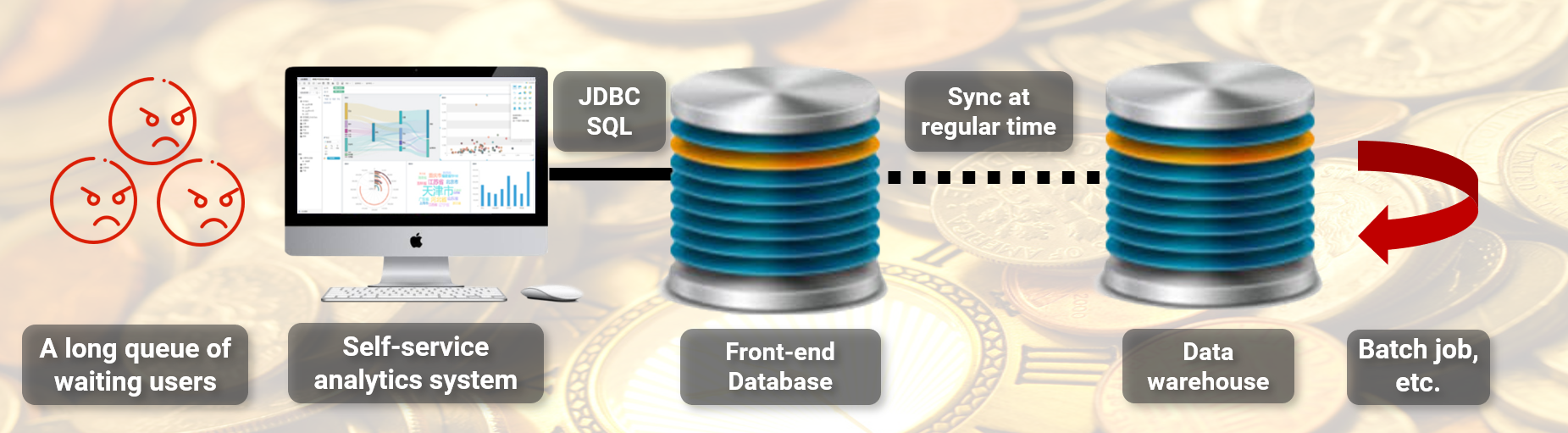
However, simply placing a regular database cannot solve the problem here:
-
The BI system needs to analyze the whole amount of data from the past many years. If all the data related to BI business is moved out, it will be in the same order of magnitude as the central data warehouse. This is equivalent to rebuilding a distributed data system, and this cost is unacceptable.
-
If only recent data that is frequently accessed is stored, then a single database can indeed be used for storage. However, we cannot predict which time period of data that users will analyze, although it is not frequent, there is still a possibility of accessing long-term historical data. Unless significant changes are made on the BI application side, requiring users to choose different databases based on access time periods and prohibiting cross time period analysis, such user experience can be a bit harsh, and significant changes need to be made to the BI system.
-
There is also an issue with SQL translation. The BI system used here is a semi commercial software provided by a third-party manufacturer. Each analysis task can only connect to one database at a time, and only SQL statements with corresponding syntax will be generated based on this database. If we want to access two databases simultaneously, we need to generate two sets of SQL syntax at the same time. Although the SQL statements used for multidimensional analysis are very regular, there are still some database-specific function syntax (especially date and time related), which requires modifying the front-end BI system.
-
The commercial database commonly used by this organization is a row-based storage database, which is difficult to meet performance requirements even for small-scale recent frequent data. It needs to be replaced with a professional columnar data warehouse here, but finding a lightweight solution is not easy.
In this scenario, it is suitable to use esProc as the front-end computing engine.
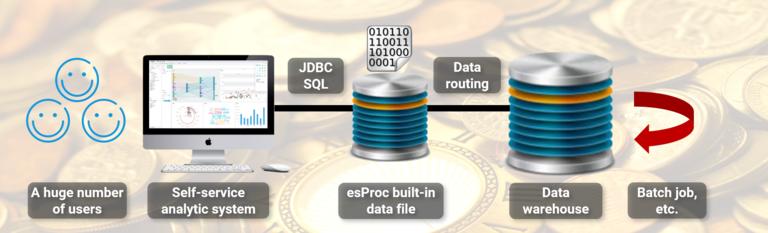
The recent data volume that is frequently accessed is not large, and a single server is sufficient for storage, so there is no need to use a complex distributed system; The composite table of esProc provides columnar storage compression scheme, which can provide high-performance traversal and statistical operations; esProc provides a simple SQL interface that can be directly integrated with the BI system; All of the above can be provided by regular databases, but esProc is a bit lighter (it can even be directly embedded into the BI application to work).
The key is that esProc provides open computing power, allowing programmers to obtain SQL statements and use SPL to split the time period parameters in the WHERE clause, identifying the range of data involved in the query. If only local data is used, the calculation will be carried out by esProc; If there is long-term historical data involved, the query will still be sent to the central data warehouse for calculation, and in the process, SQL can also be translated into syntax accepted by the data warehouse using SPL, perfectly implementing the programmable data gateway function.
In this way, the front-end BI system can implement the separation of hot and cold backend data with almost no modification. Due to the vast majority of frequent access being taken over by esProc, there are very few query requests that need to be forwarded to the central data warehouse, resulting in a significant improvement in overall computational performance and smoother front-end interaction response.
This is a real case (with individual features organized to highlight typicality). However, the performance optimization here does not involve the algorithmic advantages of SPL, mainly the adjustment of application framework. It is not important whether the implementation of this solution involves the use of esProc. The key is the concept we have always advocated of freeing computation from the database. Open computing itself is an important capability, not necessarily tied to a database. Data computing requires its own middleware.
SPL Official Website 👉 http://www.scudata.com
SPL Feedback and Help 👉 https://www.reddit.com/r/esProc
SPL Learning Material 👉 http://c.scudata.com
SPL Source Code and Package 👉 https://github.com/SPLWare/esProc
Discord 👉 https://discord.gg/ydhVnFH9
Youtube 👉 https://www.youtube.com/@esProc_SPL


Chinese version