

Comparison of SQL & SPL: Join Operations (Ⅱ)
The join operation is used to combine records of two or more tables. This essay explains the handling of join operations using SQL and SPL. By exploring solutions and basic principles of the two commonly used programming languages and providing sample programs written in them, we try to find a faster and more efficient way for you. Looking Comparison of SQL & SPL: Join Operations (Ⅱ) for details.
In this essay, we focus on join operations with many-to-one relationship.
The many-to-one relationship exists between tables where any number of records in the first table correspond to one record in the other table. The two tables usually have a foreign key association. A certain field in table A are associated with the primary key of table B. The field in table A that links to table B’s primary key is called the foreign key pointing to table B. Table B is called table A’s foreign key table.
Suppose there are employee table and department table. The department ID field in employee table points to department table’s ID field. One employee corresponds to one department, but one department could have multiple employees. The relationship of employee table and department table is many-to-one.
The one-to-many relationship and the many-to-one relationship are different, but SQL does not distinguish them. It provides no methods to handle them separately.
The method of handling a join operation with many-to-one relationship is completely different from that of dealing with one with one-to-many relationship. We convert foreign key values into corresponding records in the other table, or attach the target field value into the table at the “many” end, to generate a combined table on which queries can be performed. SQL does not offer a particular method to handle joins with the many-to-one relationship, it uses the ordinary JOIN to do the work. SPL provides A.switch()function and other functions to specifically optimize and speed up foreign-key-type joins (many-to-one association).
【Example 1】Get names of all employees and the department they work in based on EMPLOYEE table and DEPARTMENT table. Below is part of the source data:
EMPLOYEE:
ID |
NAME |
BIRTHDAY |
DEPARTMENTID |
SALARY |
1 |
Rebecca |
1974/11/20 |
6 |
7000 |
2 |
Ashley |
1980/07/19 |
2 |
11000 |
3 |
Rachel |
1970/12/17 |
7 |
9000 |
4 |
Emily |
1985/03/07 |
3 |
7000 |
5 |
Ashley |
1975/05/13 |
6 |
16000 |
… |
… |
… |
… |
… |
DEPARTMENT:
ID |
NAME |
MANAGER |
1 |
Administration |
18 |
2 |
Finance |
2 |
3 |
HR |
4 |
4 |
Marketing |
6 |
5 |
Production |
7 |
… |
… |
… |
SQL solution:
SQL uses JOIN statement to join two tables with the many-to-one relationship according to the condition that a foreign key field value is equivalent to the corresponding primary key value in the foreign key table. Here we use the left join to search for all employees. Below are SQL statements:
SELECT
E.NAME, D.NAME DEPT_NAME
FROM EMPLOYEE E
LEFT JOIN
DEPARTMENT D
ON E.DEPARTMENTID=D.ID
SPL solution:
SPL A.switch() function converts values of DEPARTMENTID values into corresponding records in DEPARTMENT table.
A |
|
1 |
=T("Employee.txt") |
2 |
=T("Department.txt") |
3 |
=A1.switch(DEPARTMENTID, A2:ID) |
4 |
=A3.new(NAME, DEPARTMENTID.NAME:DEPT_NAME) |
A1: Import Employee table.
A2: Import Department table.
A3: A.switch() function objectifies foreign key values, by replacing DEPARTMENTID values with corresponding DEPARTMENT records.
A4: Return employee names and department names. The latter is obtained from NAME field of DEPARTMENT records.
The case is simple. Both SQL and SPL can handle it well. Someone may ask why we objectify the foreign key instead of referencing the foreign key field during the join? Hope you can understand the reason through the following more complicated example.
【Example 2】Find the American employees whose managers are Chinese based on EMPLOYEE table and DEPARTMENT table. Below is part of the source data:
EMPLOYEE:
ID |
NAME |
BIRTHDAY |
DEPARTMENTID |
SALARY |
1 |
Rebecca |
1974/11/20 |
6 |
7000 |
2 |
Ashley |
1980/07/19 |
2 |
11000 |
3 |
Rachel |
1970/12/17 |
7 |
9000 |
4 |
Emily |
1985/03/07 |
3 |
7000 |
5 |
Ashley |
1975/05/13 |
6 |
16000 |
… |
… |
… |
… |
… |
DEPARTMENT:
ID |
NAME |
MANAGER |
1 |
Administration |
18 |
2 |
Finance |
2 |
3 |
HR |
4 |
4 |
Marketing |
6 |
5 |
Production |
7 |
… |
… |
… |
SQL solution:
Just adding the desired foreign key field to EMPLOYEE table is not right. We need two joins instead. The first is the join between DEPARTMENT table and EMPLOYEE table through ID field for getting nationalities of managers. The second join is between EMPLOYEE table and DEPARTMENT table through DEPARTMENTID field for getting the employees’ departments. Below are SQL statements:
SELECT *
FROM EMPLOYEE E2
LEFT JOIN
(SELECT D1.ID,D1.MANAGER,E1.NATION MANAGER_NATION
FROM DEPARTMENT D1
LEFT JOIN EMPLOYEE E1
ON D1.MANAGER=E1.ID
) D2
ON E2.DEPARTMENTID=D2.ID
WHERE D2.MANAGER_NATION='Chinese' AND E2.NATION='American'
This block of SQL code is rather complicated. Each join requires a layer of nested query and you need to know the target fields in the foreign key table in advance.
SPL solution:
SPL handles this task also through A.switch() function by objectifying foreign key values.
A |
|
1 |
=T("Employee.txt").keys(ID) |
2 |
=T("Department.txt").keys(ID) |
3 |
=A2.switch(MANAGER, A1) |
4 |
=A1.switch(DEPARTMENTID, A2) |
5 |
=A4.select(NATION=="American" && DEPARTMENTID.MANAGER.NATION=="Chinese") |
A1: Import Employee table and set ID as the primary key.
A2: Import Department table and set ID as the primary key.
A3: Use A.switch() function to objectify foreign key field by converting Department table’s MANAGER field into corresponding Employee records.
A4: Use A.switch() function to objectify foreign key field by converting Employee table’s DEPARTMETNID field into corresponding Department records.
A5: Get records of American employees whose managers are Chinese.
The SPL script is not so complicated as SQL statements. SPL just performs one more foreign key objectification according to the natural logic. You do not need to know which fields you want in advance for a foreign key field join because SPL allows you to get them directly from the record object. To get managers who are Chinese , SPL uses the expression DEPARTMENTID.MANAGER.NATION, which is natural.
【Example 3】Find the number of students who select “Matlab” course based on COURSE table and SELECT_COURSE table. Below is part of the source data:
COURSE:
ID |
NAME |
TEACHERID |
1 |
Environmental protection and sustainable development |
5 |
2 |
Mental health of College Students |
1 |
3 |
Matlab |
8 |
4 |
Electromechanical basic practice |
7 |
5 |
Introduction to modern life science |
3 |
… |
… |
… |
SELECT_COURSE:
ID |
COURSEID |
STUDENTID |
1 |
6 |
59 |
2 |
6 |
43 |
3 |
5 |
52 |
4 |
5 |
44 |
5 |
5 |
37 |
… |
… |
… |
SQL solution:
We can use inner join to delete non-matching records (where the selected courses are not Matlab). Below are SQL statements:
SELECT
COUNT(*) COUNT
FROM SELECT_COURSE SC
INNER JOIN
COURSE C
ON SC.COURSEID=C.ID
WHERE NAME='Matlab'
SPL solution:
A.switch() function works with @i option to delete non-matching records during the join operation.
A |
|
1 |
=T("Course.csv") |
2 |
=T("SelectCourse.csv") |
3 |
=A1.select(NAME:"Matlab") |
4 |
=A2.switch@i(COURSEID, A3:ID).count() |
A1: Import Course table.
A2: Import SelectCourse table.
A3: Select records containing Matlab from Course table.
A4: A.switch() works with @i option to remove non-matching record at the join and then count students who select Matlab course.
【Example 4】Get sales information of new customers in the year 2014, that is, records of SALES table where CUSTOMERIDs are not included in CUSTOMER table, based on SALES table and CUSTOMER table. Below is part of the source data:
SALES:
ID |
CUSTOMERID |
ORDERDATE |
SELLERID |
PRODUCTID |
AMOUNT |
10248 |
VINET |
2013/7/4 |
5 |
59 |
2440 |
10249 |
TOMSP |
2013/7/5 |
6 |
38 |
1863.4 |
10250 |
HANAR |
2013/7/8 |
4 |
65 |
1813 |
10251 |
VICTE |
2013/7/8 |
3 |
66 |
670.8 |
10252 |
SUPRD |
2013/7/9 |
4 |
46 |
3730 |
… |
… |
… |
… |
… |
… |
CUSTOMER:
ID |
NAME |
CITY |
POSTCODE |
TEL |
ALFKI |
Sanchuan Industrial Co., Ltd |
Tianjin |
343567 |
(030) 30074321 |
ANATR |
Southeast industries |
Tianjin |
234575 |
(030) 35554729 |
ANTON |
Tanson trade |
Shijiazhuang |
985060 |
(0321) 5553932 |
AROUT |
Guoding Co., Ltd |
Shenzhen |
890879 |
(0571) 45557788 |
BERGS |
Tongheng machinery |
Nanjing |
798089 |
(0921) 9123465 |
… |
… |
… |
… |
… |
SQL solution:
SQL can use NOT IN or NOT EXISTS to retain only the non-matching records, which are SALES records whose CUSTOMERIDs are not included in CUSTOMER table at the join. Below are SQL statements:
SELECT *
FROM SALES S
WHERE
EXTRACT (YEAR FROM ORDERDATE)=2014
AND
CUSTOMERID NOT IN
(SELECT DISTINCT ID
FROM CUSTOMER)
Or:
SELECT *
FROM SALES S
WHERE
EXTRACT (YEAR FROM ORDERDATE)=2014
AND
NOT EXISTS
(SELECT *
FROM CUSTOMER C
WHERE S.CUSTOMERID=C.ID)
SPL solution:
A.switch() function works with @d option to keep only the non-matching records.
A |
|
1 |
=T("Sales.csv") |
2 |
=T("Customer.txt") |
3 |
=A1.select(year(ORDERDATE)==2014) |
4 |
=A3.switch@d(CUSTOMERID, A2:ID) |
A1: Import Sales table.
A2: Import Customer table.
A3: Select records of 2014 from Sales table.
A4: A.switch() works with @d option to keep non-matching records only, which are the sales records of new customers in the year 2014.
【Example 5】Find the superior organization for each section based on organization structure table. Below is part of the source data:
ID |
ORG_NAME |
PARENT_ID |
1 |
Head Office |
0 |
2 |
Beijing Branch Office |
1 |
3 |
Shanghai Branch Office |
1 |
4 |
Chengdu Branch Office |
1 |
5 |
Beijing R&D Center |
2 |
… |
… |
… |
SQL solution:
In the table, PARENT_ID points to a value in the same table. This is a case of self-join. We query the table twice, which is equivalent to treating the source data as two tables, and then perform the join. Below are SQL statements:
SELECT
ORG1.ID,ORG1.ORG_NAME,ORG2.ORG_NAME PARENT_NAME
FROM
ORGANIZATION ORG1
LEFT JOIN
ORGANIZATION ORG2
ON ORG1.PARENT_ID=ORG2.ID
ORDER BY ID
SPL solution:
SPL uses A.switch() function to objectify foreign key values, where the foreign key table is the table itself.
A |
|
1 |
=T("Organization.txt") |
2 |
=A1.switch(PARENT_ID, A1:ID) |
3 |
=A2.new(ID, ORG_NAME, PARENT_ID.ORG_NAME:PARENT_NAME) |
A1: Import Organization table.
A2: A.switch() function objectify foreign key values by replacing PARENT_ID values with corresponding parent organization records.
A3: Return names of all organizations and their parent organizations.
【Example 6】Get customers and their order amounts in the year 2015. Below are part of data in ORDERS table, ORDER_DETAIL table and CUSTOMER table:
ORDERS:
ID |
CUSTOMERID |
EMPLOYEEID |
ORDER_DATE |
ARRIVAL_DATE |
10248 |
VINET |
5 |
2012/07/04 |
2012/08/01 |
10249 |
TOMSP |
6 |
2012/07/05 |
2012/08/16 |
10250 |
HANAR |
4 |
2012/07/08 |
2012/08/05 |
10251 |
VICTE |
3 |
2012/07/08 |
2012/08/05 |
10252 |
SUPRD |
4 |
2012/07/09 |
2012/08/06 |
… |
… |
… |
… |
… |
ORDER_DETAIL:
ID |
ORDER_NUMBER |
PRODUCTID |
PRICE |
COUNT |
DISCOUNT |
10814 |
1 |
48 |
102.0 |
8 |
0.15 |
10814 |
2 |
48 |
102.0 |
8 |
0.15 |
10814 |
3 |
48 |
306.0 |
24 |
0.15 |
10814 |
4 |
48 |
102.0 |
8 |
0.15 |
10814 |
5 |
48 |
204.0 |
16 |
0.15 |
… |
… |
… |
… |
… |
… |
CUSTOMER:
ID |
NAME |
CITY |
POSTCODE |
TEL |
ALFKI |
Sanchuan Industrial Co., Ltd |
Tianjin |
343567 |
(030) 30074321 |
ANATR |
Southeast industries |
Tianjin |
234575 |
(030) 35554729 |
ANTON |
Tanson trade |
Shijiazhuang |
985060 |
(0321) 5553932 |
AROUT |
Guoding Co., Ltd |
Shenzhen |
890879 |
(0571) 45557788 |
BERGS |
Tongheng machinery |
Nanjing |
798089 |
(0921) 9123465 |
… |
… |
… |
… |
… |
SQL solution:
This task involves both one-to-many relationship (between ORDERS table and ORDER_DETAIL table) and many-to-one relationship (between ORDERS table and CUSTOEMR table). SQL does not define the two relationship separately, but it is necessary to differentiate them. First, we handle foreign key table (the many-to-one relationship) by attaching the foreign key values or desired field values to the table at the “many” end, and then we deal with the primary-and-sub tables (the one-to-many relationship). Below are SQL statements:
SELECT
CUSTOMER_NAME, SUM(AMOUNT) AMOUNT
FROM (
SELECT
Orders1.ID, CUSTOMER_NAME, Detail.PRICE*Detail.COUNT AMOUNT
FROM (
SELECT
Orders.ID,Customer.NAME CUSTOMER_NAME
FROM ORDERS Orders
LEFT JOIN
CUSTOMER Customer
ON Orders.CUSTOMERID=Customer.ID
WHERE EXTRACT (YEAR FROM ORDER_DATE)=2015
) Orders1
INNER JOIN
ORDER_DETAIL Detail
ON Orders1.ID=Detail.ID
)
GROUP BY CUSTOMER_NAME
ORDER BY CUSTOMER_NAME
SPL solution:
SPL performs foreign key objectification to replace ORDERS table’s CUSTOMERID field values with corresponding CUSTOMER records and then we have only the primary table and its sub table, which are joined using join() function.
A |
|
1 |
=T("Orders.txt") |
2 |
=T("Customer.txt") |
3 |
=A1.select(year(ORDER_DATE)==2015).switch(CUSTOMERID, A2:ID) |
4 |
=T("OrderDetail.txt").group(ID) |
5 |
=join(A3:Orders, ID;A4:Detail, ID) |
6 |
=A5.groups(Orders.CUSTOMERID.NAME; Detail.sum(PRICE*COUNT):AMOUNT) |
A1: Import Orders table.
A2: Import Customers table.
A3: Select Orders records of the year 2015, and use A.switch() function to objectify the foreign key CUSOTMERID by converting its values to corresponding CUSTOMER records.
A4: Import OrderDetail table and group it by ID.
A5: The join() function joins Orders table and OrderDetail table by ID fields.
A6: Group A5’s result set and sum sales amounts for each customer.
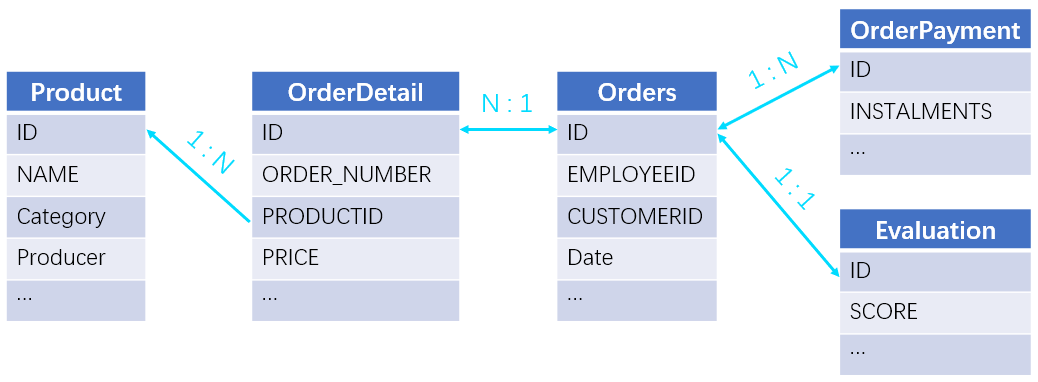
【Example 7】Get order information of the year 2014 (order IDs, product names and total amounts) where the product name contains “water” and order amount is greater than 200, and that do not pay in installment and get 5-star evaluation. Below is part of the source data and the relationships between tables:
ORDERS:
ID |
CUSTOMERID |
EMPLOYEEID |
ORDER_DATE |
ARRIVAL_DATE |
10248 |
VINET |
5 |
2012/07/04 |
2012/08/01 |
10249 |
TOMSP |
6 |
2012/07/05 |
2012/08/16 |
10250 |
HANAR |
4 |
2012/07/08 |
2012/08/05 |
10251 |
VICTE |
3 |
2012/07/08 |
2012/08/05 |
10252 |
SUPRD |
4 |
2012/07/09 |
2012/08/06 |
… |
… |
… |
… |
… |
ORDER_DETAIL:
ID |
ORDER_NUMBER |
PRODUCTID |
PRICE |
COUNT |
DISCOUNT |
10814 |
1 |
48 |
102.0 |
8 |
0.15 |
10814 |
2 |
48 |
102.0 |
8 |
0.15 |
10814 |
3 |
48 |
306.0 |
24 |
0.15 |
10814 |
4 |
48 |
102.0 |
8 |
0.15 |
10814 |
5 |
48 |
204.0 |
16 |
0.15 |
… |
… |
… |
… |
… |
… |
ORDER_PAYMENT:
ID |
PAY_DATE |
AMOUNT |
CHANNEL |
INSTALMENTS |
10814 |
2014/01/05 |
816.0 |
3 |
0 |
10848 |
2014/01/23 |
800.25 |
2 |
1 |
10848 |
2014/01/23 |
800.25 |
0 |
0 |
10848 |
2014/01/23 |
800.25 |
3 |
1 |
10966 |
2014/03/20 |
572.0 |
2 |
1 |
… |
… |
… |
… |
… |
EVALUATION:
ID |
SCORE |
DATE |
COMMENT |
10248 |
4 |
2012/07/12 |
|
10249 |
1 |
2012/07/06 |
|
10250 |
4 |
2012/07/10 |
|
10251 |
2 |
2012/07/11 |
|
10252 |
3 |
2012/07/16 |
|
… |
… |
… |
… |
PRODUCT:
ID |
NAME |
SUPPLIERID |
CATEGORY |
1 |
Apple Juice |
2 |
1 |
2 |
Milk |
1 |
1 |
3 |
Tomato sauce |
1 |
2 |
4 |
Salt |
2 |
2 |
5 |
Sesame oil |
2 |
2 |
… |
… |
… |
… |
SQL solution:
This task involves one-to-many relationship, many-to-one relationship and one-to-one relationship. It is wrong to join them all with the JOIN operation because that will result in many-to-many relationship. The right way is to handle the many-to-one relationship (foreign key table) first by attaching foreign key values or desired field values to the table at the “many” end, and we have one-to-one relationship and one-to-many relationship only. Then we group the sub table by the primary table’s primary key (order ID), which makes the key the sub table’s actual primary key. Finally, we join the four tables through order ID. Below are SQL statements:
SELECT
Orders.ID,Detail1.NAME, Detail1.AMOUNT
FROM (
SELECT ID
FROM ORDERS
WHERE
EXTRACT (YEAR FROM Orders.ORDER_DATE)=2014
) Orders
INNER JOIN (
SELECT ID,NAME, SUM(AMOUNT) AMOUNT
FROM (
SELECT
Detail.ID,Product.NAME,Detail.PRICE*Detail.COUNT AMOUNT
FROM ORDER_DETAIL Detail
INNER JOIN
PRODUCT Product
ON Detail.PRODUCTID=Product.ID
WHERE NAME LIKE '%water%'
)
GROUP BY ID,NAME
) Detail1
ON Orders.ID=Detail1.ID
INNER JOIN(
SELECT
DISTINCT ID
FROM ORDER_PAYMENT
WHERE INSTALMENTS=0
) Payment
ON Orders.ID = Payment.ID
INNER JOIN(
SELECT ID
FROM EVALUATION
WHERE SCORE=5
) Evaluation
ON Orders.ID = Evaluation.ID
The SQL statements are difficult to write, hard to understand and maintain. More importantly, it is inconvenient to check whether the statements are correctly written since there are too many joins and nested queries.
SPL solution:
A |
|
1 |
=T("Orders.txt").select(year(ORDER_DATE)==2014) |
2 |
=T("Product.txt").select(like(NAME, "*water*")) |
3 |
=T("OrderDetail.txt").switch@i(PRODUCTID, A2:ID) |
4 |
=A3.group(ID).select(sum(PRICE*COUNT)>200) |
5 |
=T("OrderPayment.txt").select(INSTALMENTS==0).group(ID) |
6 |
=T("Evaluation.txt").select(SCORE==5) |
7 |
=join(A1:Orders,ID;A4:Detail,ID;A5:Payment,ID;A6:Evaluation,ID) |
8 |
=A7.new(Orders.ID,Detail.PRODUCTID.NAME,Detail.sum(PRICE*COUNT):AMOUNT) |
A1: Import Orders table and select records of the year 2014.
A2: Import Product table and select records that contain water.
A3: Import OrderDetail table and objectify the foreign key PRODUCTID by replacing its values with corresponding records in Product table.
A4: Group OrderDetail table by ID field and select records where the amount is above 200.
A5: Import OrderPayment table and select records that do not have installment information.
A6: Import Evaluation table and select records containing 5-star evaluations.
A7: The join() function joins Orders table, OrderDetail table, OrderPayment table, and Evaluation table according to ID fields.
A8: Return the eligible order IDs, product names and order amounts.
The SPL script has two more lines of code. The import, select, and group operations on each table are separately performed, and only one line (A7) is for the join. The logic is natural and clear.
As seen from the above example, many-to-one relationship and one-to-many relationship is rather different. It is important for you to distinguish them even though SQL treat them in the same way. SPL, however, treats them in separate ways by supplying different functions for handling them. Now let’s take a look at the SPL solution to multi-table joins:
(1) With the many-to-one relationship (foreign key table), attach foreign key values or desired field values to the table at the “many” end.
(2) With the one -to-many relationship (primary and sub tables), group the sub table by the primary table’s primary key and the key becomes the sub table’s actual primary key.
(3) Join multiple tables through the primary keys (or the actual primary keys).
SPL Official Website 👉 https://www.scudata.com
SPL Feedback and Help 👉 https://www.reddit.com/r/esProcSPL
SPL Learning Material 👉 https://c.scudata.com
SPL Source Code and Package 👉 https://github.com/SPLWare/esProc
Discord 👉 https://discord.gg/cFTcUNs7
Youtube 👉 https://www.youtube.com/@esProc_SPL

