

How to handle multi-source calculations in Java reporting tools?
To other questions:
What should I do when the data source in the Java report tool cannot be calculated by SQL?
What should I do when it is difficult to write complex SQL in Java reporting tools?
Solution: esProc – the professional computational package for Java
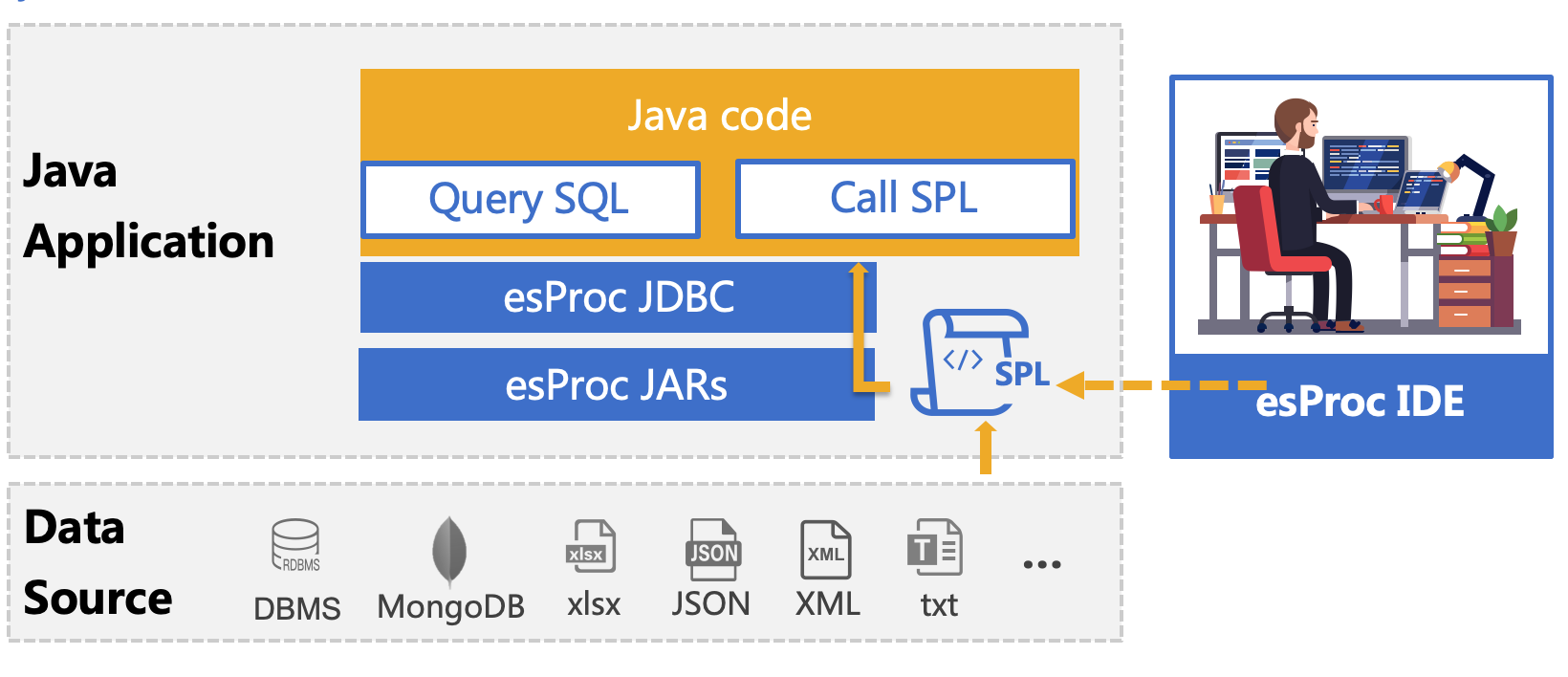
esProc is a class library dedicated to Java-based calculations and aims to simplify Java code. SPL is a scripting language based on the esProc computing package. It can be deployed together with Java programs and understood as a stored procedure outside the database. Its usage is the same as calling a stored procedure in a Java program. It is passed to the Java program for execution through the JDBC interface, realizing step-by-step structured computing, return the ResultSet object.
Same type data sources
Some databases support cross-database queries but generally require the same type of database by mapping a data table in another database or using a special computing gateway. SPL submits SQL statements to various databases through multiple threads executed parallel by these databases. Their respective calculation results are returned and then summarized and processed and provided to the application program.
A telecommunications company uses the table userService to store user service information, which is stored in multiple databases by region, and the data is summarized as follows using SPL:
A |
B |
|
| 1 | [mysql1,mysql2,mysql3,mysql4] |
|
| 2 | fork A1 | =connect(A2) |
| 3 | =B2.query@x("select product_no,sum(allDuration) sallDuration,sum(allTimes) sallTimes,sum(localDuration) slocalDuration ,sum(localTimes) slocalTimes from userService where I0419=? group by product_no", argType) | |
| 4 | =A2.conj() | |
| 5 | =A4.groups(product_no;sum(sallDuration):ad,sum(sallTimes):at,sum(slocalDuration):ld,sum(slocalTimes):lt) | |
The statement fork starts four threads in parallel, and each thread fetches data from the corresponding database and returns the grouped and summarized results to the main thread. Finally, the main thread merges the calculation results of the sub-threads, performs grouping and summarization again, and returns the final result set. It involves parallel calculations, merging, grouping, and other structured data calculations. If it is done directly in Java, the code is very lengthy.
The integration of SPL and Java report development tools is also very simple. Take Vertica as the data source and Birt as the reporting tool as an example. Copy the esProc core jar package and the corresponding database driver jar package to the Birt development environment [installation directory]\plugins\org.eclipse.birt.report.data.oda.jdbc_4.6.0.v20160607212 (different Birt versions are slightly different) .
Create a new report in the Birt development tool and add the esProc data source “esProcConnection”

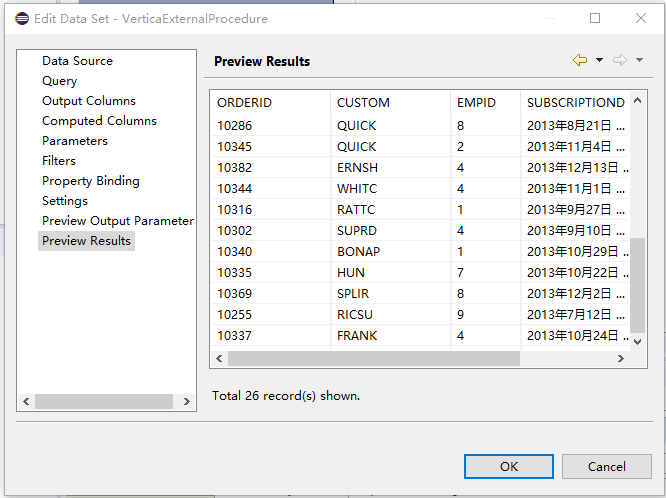
Birt calls the Vertica external stored procedure (esProc data set). Create a new “Data Sets”, select the configured esProc data source (esProcConnection), and select the data set type to select a stored procedure (SQL Stored Procedure Query).

Query Text input: {call VerticaExternalProcedures()}, where VerticaExternalProcedures is the SPL script file name

Finish, preview the data (Preview Results)
For more Java report integration details, please refer to: How to Call an SPL Script in BIRT and How to Call an SPL Script in JasperReport
If the data table is the same, but the database type is different, you can execute the same SQL statement through SPL:
A |
|
1 |
>sql="SELECT * FROM sales WHERE WEEKOFYEAR(orderdate) = 35" |
2 |
>dbname=["oracle","mysql"] |
3 |
>dbtype=["ORACLE","MYSQL"] |
4 |
=dbname.(connect@l(~)) |
5 |
=dbtype.(sql.sqltranslate(~)) |
6 |
=A4.conj(~.query@x(A5(#))) |
If the amount of data is large, SPL also has a cursor reading method. You can bind calculations on the cursor, such as grouping by the Dept field of the Employees table, summarizing the Amount field of the Orders table, and implementing association and grouping calculations on the cursor. Thus, large data calculations can be done using small memory.
A |
|
1 |
=orcl.cursor("select EId, Dept from Employees order by EId") |
2 |
=mysql1.cursor("select SellerId, Amount from Orders order by SellerId") |
3 |
=joinx(A2:O,SellerId; A1:E,EId) |
4 |
=A3.groups(E.Dept;sum(O.Amount)) |
Different types of data sources
Data often comes from a variety of heterogeneous data sources, such as relational databases (oracle, db2, MySQL), nosql databases (MongoDB), HTTP data sources, Hadoop (hive, hdfs), and even excel or text files. Usually, it is necessary to gather all the data into one database for calculation, which will increase a lot of workloads. However, if SPL is used to achieve heterogeneous data association, not only can the existing data storage process remain unchanged, but the development workload is also very small. Furthermore, because SPL has a wealth of structured algorithms, it is easy to implement related queries and subsequent calculations and is often simpler than SQL.
For example, the sales data is stored in MongoDB and the salesperson information table from the DB2 database. Therefore, the calculation example is as follows:
| A | |
|---|---|
| 1 | >hrdb=connect(“db22”) |
| 2 | =hrdb.query(“select * from employee where state=?”,state) |
| 3 | =mongodb(“mongo://localhost:27017/test?user=test&password=test”) |
| 4 | =A3.find(“orders”,,“{_id:0}”).fetch() |
| 5 | =A4.switch@i(SELLERID,A2:EID) |
| 6 | =A5.new(ORDERID,CLIENT,SELLERID.NAME:SELLERNAME,AMOUNT,ORDERDATE) |
| 7 | >hrdb.close() |
| 8 | >A3.close() |
| 9 | result A6 |
For another example, the text is associated with JSON, sales.txt is a structured text separated by tabs, and city.json is an unstructured JSON string. There is a foreign key relationship between the second column of sales.txt and part of the text in city.json. The two files are connected as a two-dimensional table.
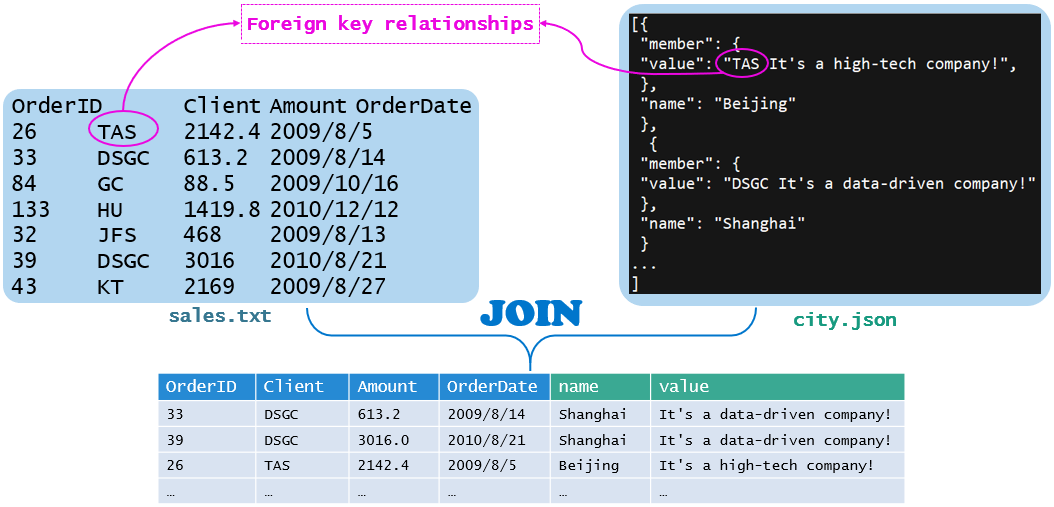
The SPL code is implemented as follows:
| A | |
|---|---|
| 1 | =json(file(“/workspace/city.json”).read()) |
| 2 | =A1.new(name,#1.(#1):desc,(firstblank=pos(desc," "),left(desc,firstblank-1)):key,right(desc,len(desc)-firstblank):value) |
| 3 | =file(“/workspace/sales.txt”).import@t() |
| 4 | =join(A3:sales,#2;A2:city,key) |
| 5 | =A4.switch@i(SELLERID,A2:EID) |
| 6 | =A4.new(sales.OrderID,sales.Client,sales.Amount,sales.OrderDate,city.name,city.value) |
More SPL applications
Refer to Use SPL in applications
SPL Official Website 👉 https://www.scudata.com
SPL Feedback and Help 👉 https://www.reddit.com/r/esProcSPL
SPL Learning Material 👉 https://c.scudata.com
SPL Source Code and Package 👉 https://github.com/SPLWare/esProc
Discord 👉 https://discord.gg/2bkGwqTj
Youtube 👉 https://www.youtube.com/@esProc_SPL

