

Looking for the Best Method of Handling Multistep Data Preparation for Reporting Tools
In some report development scenarios, the original data will undergo complicated computations through a number of steps before it is presented as expected in the desired layout. Finding a simple and efficient way or tool to get the multistep, complicated preparations done is crucial to increasing report development performance. This essay will examine several such methods to try to give you the best choice.
Complicated SQL/Stored procedure
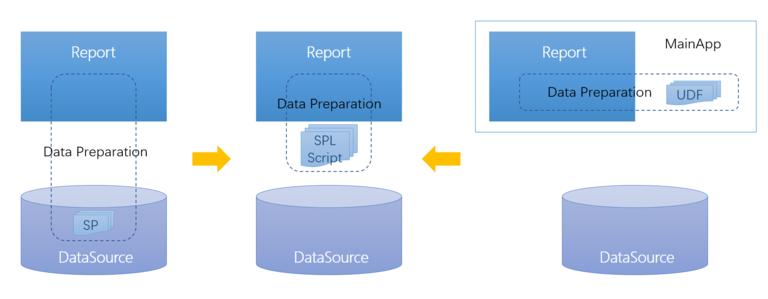
RDB data sources have strong computing power. Using SQL enables us to handle most of the data processing scenarios. Yet some SQL queries are too hard to write for ordinary report development staff, and professional DBAs are still needed. On certain occasions, it is also hard to write a multistep computation in one SQL statement. But if the database supports stored procedure (SP), we can write SPs to handle the multistep, complicated computations.
SP has its disadvantages. The practice of storing SP within the database causes tight coupling between report and database, as well as maintenance difficulty. Any change of the report needs the corresponding modification of SP through the database operation, which poses potential security problems. SP is unmigratable and narrowly applicable, and becomes invalid once the database is split, extended, or replaced by another type of database.
Even so, not all databases support SP. Vertica, for instance, achieves the equal functionality by calling an external UDF at a much higher degree of complexity. The non-RDB data sources, such as NoSQL, File and Webservice, even do not support SQL or only provide weak support for SQL (through file SQL engines), let alone SPs. Without SP, there are more difficulties in managing multistep, complicated data preparation work.
User-defined programming
Many reporting tools provide user-defined data preparation interface for users to write their own programs to perform data preparation. After all, there are no computations that hardcoding cannot manage. Users obtain the most freedom as well as the greatest difficulties. Only professional programmers, rather than ordinary report development people, can do the job using special computing class libraries.
Apart from the high development cost, a user-defined data preparation program (like Java) needs to be compiled and deployed together with the main program. This usually leads to high-coupling between report module and the main application, and makes the report too dependent and hard to maintain.
Reporting tool’s auxiliary cells
Some grid-style reporting tools try to facilitate data preparation process through auxiliary cells (while it is hard for control-style reporting tools). They add a certain number of cells during the preparation process to perform the intermediate data computations according to positions and using variables, and then hide the cells when the multistep computation is finished.
Auxiliary cells can only handle a very few types of computations. Reporting tools, in themselves, are intended for data presentation instead of data computations. So computing is not their strength. The excessive use of auxiliary cells takes up too much memory, thus reducing performance, making maintenance of reports more difficult, and disrupts the clear (procedure type) relationship between cells, resulting in messy report. Generally speaking, users should not depend much on this special method to handle complicated computations in real-world situations.
esProc SPL
esProc is the professional open-source data processing engine. It is suitable for performing the complicated, multistep data preparation task for report development. The application settles itself between the report and the data source, yet is positioned closer to the report side for an easier integration by the reporting tool. It enables a reporting tool to conveniently deal with the complicated, multistep data preparation process, creating a separate data preparation module independent of the main application and loosely coupled with the data source. esProc offers standard JDBC and ODBC interface to let the reporting tool obtain the result of an SPL script easily (SPL is the formal scripting language esProc uses).
SPL also implements the computation in a succinct way. Here is an example:
Based on the stock record table, we are trying to find the stocks that have been rising consecutively for 5 days and count the days (treat equal stock prices as rising).
SQL solution:
select code,max(risenum)-1 maxRiseDays from
( select code,count(1) risenum from
(
select code,changeSign,sum(changeSign) over(partition by code order by ddate) unRiseDays from
(
select
code,
ddate,
case when price>=lag(price) over(partition by code order by ddate)
then 0 else 1 end changeSign
from stock_record
)
)
group by code,unRiseDays
)
group by code
having max(risenum) > 5
SPL solution:
A |
||
1 |
=connect@l("orcl").query@x("select * from stock_record order by ddate") |
|
2 |
=A1.group(code) |
|
3 |
=A2.new(code,~.group@i(price<price[-1]).max(~.len())-1:maxrisedays) |
Count the dates when each stock rises consecutively |
4 |
=A3.select(maxrisedays>=5) |
Get eligible records |
You can see that SPL supports a step-by-step coding that achieves an algorithm according to the natural way of thinking. By contrast, SQL needs to combine all steps into a long and nested statement.
On top of that, SPL boasts big data handling capability supported by order-based computation, external storage computation, and parallel processing. You can use it to deal with most of the big data computing scenarios and output result set fast to the reporting tool.
In summary, user-defined programming is the most flexible yet the most difficult way. It is not easily applicable, and causes high coupling between applications. SQL/SP shows better ability in handling complicated, multistep computations (though in a roundabout way), but it is applicable to a limited number of data sources and has various database problems. The reporting tool’s auxiliary cells have too limited ability to manage complex data computing scenarios. All the three tools are not the first and satisfactory choices for handling complicated, multistep data preparation work for report development. esProc SPL is easy to use and as flexible as the user-defined programming. From a technical engineering point of view, the tool has a balanced and even framework. Compared with SP, SPL is more like an external database SP independent of the database. From the standpoint of the user-defined programming, SPL is a kind of loosely coupled, low-complexity user-defined implementation.
SPL Official Website 👉 https://www.scudata.com
SPL Feedback and Help 👉 https://www.reddit.com/r/esProcSPL
SPL Learning Material 👉 https://c.scudata.com
SPL Source Code and Package 👉 https://github.com/SPLWare/esProc
Discord 👉 https://discord.gg/2bkGwqTj
Youtube 👉 https://www.youtube.com/@esProc_SPL

