

1.1 Bin file
1.1.1 Dump data to bin file
Dump data from a text file:
| A | |
|---|---|
| 1 | =file(“Orders.txt”).cursor@t(CustomerID:string, OrderDate:datetime, ProductID:string, Quantity:int, Unit:string, Price:decimal, Amount:decimal, EmployeeID:int, EmployeeName:string, ShipVia:string) |
| 2 | =T(“Orders.btx”:A1) |
A1 @t option enables reading the first line as column names (without it there are no column names). Parameters specify columns to be imported (by default all columns are imported), and data types to which columns of data are converted after they are imported (by default data type is automatically identified according to the contents of corresponding column). In this example, Orders.txt uses the default tab as column separator. To use comma as the separator, add @c option to the function, like cursor@c(). To use a different separator, just specify it in the cursor function.
Dump data from the database:
| A | |
|---|---|
| 1 | =connect(“sqlserver2012”) |
| 2 | =A1.cursor@x(“select * from Orders”) |
| 3 | =T(“Orders.btx”:A2) |
A2 @x option enables closing database connection automatically after data import is finished.
1.1.2 Filtering, and grouping & aggregation
SQL
SELECT *
FROM Orders
WHERE Amount>1000
SPL
| A | |
|---|---|
| 1 | =file(“Orders.btx”).cursor@mb().select(Amount>1000) |
| 2 | =A1.fetch() |
A2 @m option enables multithreaded data retrieval.
Note: We can use multiple threads to retrieve a file. Each thread is responsible for one segment of data, and finally, results of all threads are merged into one result set. Parallel processing does not have any effect when used for data writing. Here is the diagram representing the process:
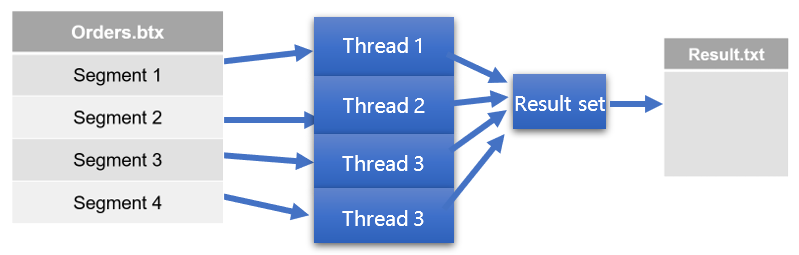
Here we assume the result set is relatively small and can fit into the memory. To return the result set to the search frontend:
| A | |
|---|---|
| 2 | return A1.fetch() |
A large result set can be returned directly as a cursor. Then data is retrieved record by record through JDBC in the frontend:
| A | |
|---|---|
| 2 | return A1 |
Or exported to a text file for loading:
| A | |
|---|---|
| 2 | >file(“result.txt”).export@t(A1) |
SQL
SELECT EmployeeID,sum(Amount) AS Amount
FROM Orders
GROUP BY EmployeeID
ORDER BY EmployeeID
SPL
| A | |
|---|---|
| 1 | =file(“Orders.btx”).cursor@mb(EmployeeID, Amount) |
| 2 | =A1.groups(EmployeeID;sum(Amount):Amount) |
A1 Import only the involved fields, which shortens the time of creating objects. @m option enables importing data with multiple threads.
This is for handling small grouping result sets that can fit into the memory. With large grouping result sets, SPL has the following code:
| A | |
|---|---|
| 2 | =A1.groupx(EmployeeID;sum(Amount):Amount) |
SQL
SELECT sum(Amount) AS Amount, sum(Quantity) AS Quantity,
count(1) AS num
FROM Orders
SPL
| A | |
|---|---|
| 1 | =file(“Orders.btx”).cursor@mb(Amount, Quantity) |
| 2 | =A1.groups(;sum(Amount):Amount, sum(Quantity): Quantity, count(1):num) |
A2 When there isn’t the grouping field parameter in groups function, the aggregation is performed on the whole set and the return value is a single-row table sequence.
We can use total function to return a sequence:
| A | |
|---|---|
| 2 | =A1.total(sum(Amount), sum(Quantity), count(1)) |
SQL
SELECT EmployeeID,count(1) num
FROM Orders
WHERE Amount>1000
GROUP BY EmployeeID
SPL
| A | |
|---|---|
| 1 | =file(“Orders.btx”).cursor@mb(EmployeeID,Amount).select(Amount>1000) |
| 2 | =A1.groups(EmployeeID;count(1):num) |
SQL
SELECT EmployeeID,sum(Amount) AS Amount
FROM Orders
WHERE OrderDate>='2022-01-01'
GROUP BY EmployeeID
HAVING sum(Amount)>250000
SPL
| A | |
|---|---|
| 1 | =file(“Orders.btx”).cursor@mb(EmployeeID,Amount,OrderDate).select(OrderDate>=date(“2022-01-01”,“yyyy-MM-dd”)) |
| 2 | =A1.groups(EmployeeID;sum(Amount):Amount).select(Amount>250000) |
SPL Official Website 👉 https://www.scudata.com
SPL Feedback and Help 👉 https://www.reddit.com/r/esProcSPL
SPL Learning Material 👉 https://c.scudata.com
SPL Source Code and Package 👉 https://github.com/SPLWare/esProc
Discord 👉 https://discord.gg/2bkGwqTj
Youtube 👉 https://www.youtube.com/@esProc_SPL

