

Data warehouse with “no house” performs better than the one with “the house”
We know that the early databases do not distinguish between TP and AP, and all tasks are handled in one database. When dealing with TP business, it is important to ensure the consistency of data, and consistency makes sense only when the data are limited within a certain range, which gives rise to the concept of “base”. The data to be loaded into database should meet some constraints, otherwise it cannot be loaded. There is a clear distinction between the data inside and outside the database, and this characteristic is called the closedness.
In addition to guaranteeing the consistency of data, the closedness can guarantee the security of data by working with the database management system (DBMS).
Data warehouse is developed based on database. When the database is unable to serve both OLTP and OLAP businesses at the same time, the AP business is separated into a separate database, giving rise to the data warehouse. Therefore, the data warehouse inherits many characteristics of database including the closedness. Inheriting the closedness is equivalent to inheriting the characteristics such as “the data can be used only after being loaded into database”, “the data to be loaded should meet some criteria”. Naturally, the concept of “house” of data warehouse is formed.
Then, is this closed storage necessary?
Yes, it is necessary for TP business but, it is not for the data warehouse focusing on AP business. Although the name of data warehouse contains the word “house”, its main function is to compute actually. Even though the data warehouse can store the data like a “house”, it actually serves calculation. After all, the data becomes valuable only when they are used (calculated). The competition among various types of new data warehouses on the market today is concentrated almost entirely on the computing ability, especially the performance, as well as the completeness of computing ability and the richness of functions, without exception, they are all about computing ability. Therefore, we can say that the key point of data warehouse is computation but storage.
In this case, is it feasible to only provide a rich and powerful computing engine, and not bind the storage function? In other words, does it work if there is no “house”?
Unfortunately, it is not feasible for most SQL-based (relational algebra) data warehouses today, because the binding of storage and computation is required by database that the data warehouse originates from, and cannot be changed.
However, it is feasible for the new “no house” data warehouse - esProc SPL!
As an open computing engine, esProc specializes in processing the data of AP business. Depending on its open computing ability, esProc supports connection to diverse data sources, and can perform mixed calculation over multiple data sources. Moreover, esProc boasts its own high-performance file storage to ensure the computing performance. Instead of adopting SQL as its formal language, esProc uses self-created SPL (Structured Process Language), which is more advantageous than SQL.
The term “no house” referred to in this article means that there is no closed and private storage functionality like traditional data warehouse.
Where are the data stored then?
Let’s answer this question and related questions in detail below, and see what benefits does “no house” bring (that is, what problems of “the house” can be overcome).
Real-time computation of diverse data sources
In fact, once data is generated, it will be stored in a medium that carries it, such as a database, a file, or the web. In a broad sense, the data is already stored. Since that’s the case, wouldn’t it be convenient if the data could be processed directly? Moreover, the data sources of enterprises are diverse today, and they often face a variety of data sources and types. It will be very convenient if these data sources can be processed directly.
esProc provides the ability to process such open-format multiple data sources directly. No matter where the data are stored (RDB, NoSQL, File, Hadoop, RESTful, etc.), esProc can read and calculate directly. More importantly, esProc can connect to different data sources to perform mixed computing.

Once the ability to support diverse data sources (mixed calculation) is available, the limitation of “house” is broken through, which saves the development and time costs caused by loading the data into database. In addition, the real-time calculation on multiple data sources fully guarantees the real-timeness of data, and then implements the real-time query after separating data into databases. Moreover, since the data are no longer loaded into database indiscriminately, the storage cost and pressure of database will be greatly reduced, which is also important in the initial application stage of esProc (the data warehouse and esProc coexist).
esProc also fully retains the advantages of various data sources. Specifically, RDB is stronger in computing ability, we can make RDB do part of calculations first and then let esProc do the rest in many scenarios; NoSQL and file are high in IO transfer efficiency, we can read and calculate their data directly in esProc; MongoDB supports multi-layer data storage, we can let SPL use its data directly. All these are the benefits that come with openness.
In contrast, the closed data warehouse cannot compute the data outside the database, and hence it has to import the data before computing, resulting in the addition of an ETL action. This action not only increases the workload of programmers and the burden of database, but losses the real-timeness of data. Usually, the data outside the database have irregular formats, and it is not easy to load them into database with strong constraints and, even ETL action is performed, it first needs to load the raw data into database in order to utilize database’s computing ability. As a result, ETL is changed to ELT, which increases the burden of database.
Computation can be done regardless of where the data is stored, this is one of the benefits “no house” esProc brings.
High performance
However, when esProc reads diverse data sources, although they have same logical status, the read performances (which will be reflected in the total computation time) varies because the efficiencies of accessing the interfaces provided by different data sources are different. For certain interfaces (such as RDB’s JDBC), the read performance is very low.
While it is convenient to access various data sources directly, it may result in poor computing performance.
To fully ensure the computing performance, esProc offers the specialized binary file storage format, and offers many mechanisms, such as compression, columnar storage, ordering, and parallel segmentation.
It is worth noting that esProc’s file storage is not closed within esProc (totally different from the closed storage of data warehouse), but stored as the files in the file system, and has the same status with other files such as text and Excel. esProc does not own these files, and instead it provides many optimization strategies to make the efficiency to access the files more efficient.
In contrast, the performance of data warehouse with “house” is often not high. We know that the computing efficiency of data warehouse depends on the optimization degree of optimization engine, and a good database will choose more efficient execution path according to the computing objective of SQL (rather than its literally expressed logic). However, such auto-optimization mechanism works only for simple calculations. Once SQL becomes slightly more complex, the engine will fail, and has to execute SQL according its literally expressed logic, resulting in a sharp decline in performance. In this case, if data storage can be intervened by adjusting the data according to algorithms (for example, sort the data by primary key), higher performance can be achieved. Unfortunately, the data warehouse is closed and its storage is private, we cannot intervene the storage, so we cannot achieve high performance.
In comparison, the file storage of esProc is very flexible, allowing us to design the storage based on any algorithm to make most of the advantages of file storage itself, and adjust the data based on the algorithm, so it is not surprising to achieve high performance.
Security and reliability
Having open computing ability and storing data to files will cause a problem: the closedness of traditional data warehouses can ensure the security and reliability of data inside the system, yet how can esProc, which no longer binds storage, ensure security and reliability?
In fact, there is no need to worry about this issue. esProc does not manage the data in principle, nor is it responsible for data security. To some extent, it can be said that esProc does not have and does not need a security mechanism.
The security of persistent data is in principle the responsibility of data source itself. For example, the database provides the security mechanisms such as user identification and authentication, authorization and verification mechanisms, and auditing techniques. For the data files in esProc format, many file systems or VMs provide perfect security mechanisms that can be utilized directly, such as access control, identity verification, and transmission encryption. The reliability of data can be guaranteed through the ability of the data source or professional storage technology itself.
In addition, esProc supports retrieving the data from object storage services before computing such as S3, and can also utilize their security mechanisms. The cloud storage technologies like S3 are more advantageous in terms of security and reliability. Currently, there are few databases that have the ability to provide reliability guarantees surpassing these professional technologies. Therefore, it is ok to directly employ the security mechanism of these technologies.
In terms of application access, esProc of the independent service process uses standard TCP/IP and HTTP to communicate, and can be monitored and managed by professional network security products, and the specific security measures will be the responsibility of these products. esProc specializes in data computation, and its philosophy on the non-computing tasks is to work with other specialized products.

In fact, the security and reliability will be worse for the database with “house”. The permission management and control of database is often not meticulous enough, resulting in all users of an application being high-privilege user. For the convenience of “computing”, the permission to intervene in “storage” is given, such as the dangerous permission to compile stored procedures. As a result, the security itself cannot be well protected. In contrast, esProc focuses only on “computing” rather than “storage”, and its “computing” works only on the secure mechanism of “storage” and does not affect or destroy “storage”. As for reliability, it is directly proportional to the investment cost. Even with the extremely expensive “two sites and three centers” construction, the reliability is still far inferior to the current professional cloud storage. Since that’s the case, leave professional matters to the professionals.
Therefore, we can say that “no house” can bring more security and more reliability than “with house”.
Implement HTAP requirement
In recent years, HTAP has become another hot spot in the database field. However, most databases implement HTAP only by attaching certain AP capabilities to TP database or by binding the two technologies together in other ways. Regardless of the method adopted, the issue of database migration is unavoidable. Not to mention the high risk, the closedness and performance problems of original data warehouse cannot be solved.
In fact, HTAP requirement is essentially to query the data in real-time after the separation of databases. If this ability is available, then this requirement can be implemented without modifying the original TP database (no migration risk).
We can introduce esProc based on original independent TP and AP systems, and utilize esProc’s open cross-source computing ability, high-performance storage and computing abilities and agile development ability to implement this requirement.

esProc implements HTAP in a way that cooperates with the existing system. In this way, it only needs to make few modifications to the existing system, and there is almost no need to modify TP database. Even original AP data source can still be used to make esProc gradually take over AP business. Having partially or completely taken over AP business, the historical cold data is stored in esProc’s high-performance file, and original ETL process that moves the data from business database to data warehouse can be directly migrated to esProc. When the cold data are large in amount, and no longer change, storing them as esProc’s high-performance file can obtain higher computing performance; when the amount of hot data is small, storing them still in original TP data source enables esProc to read and calculate directly. Since the amount of hot data is not large, querying directly based on TP data source will not have much impact, and the access time will not be too long. After that, by making use of esProc’s cold and hot data mixed computing ability, we can achieve real-time query for full data. The only thing we need to do is to periodically store cold data as esProc’s high-performance file, and store the small amount of recently generated hot data in original data source. In this way, not only is HTAP implemented, but it implements a high-performance HTAP, and there is little impact on the application framework.
Implement true Lakehouse
The closed data warehouse cannot build a true Lakehouse. The data lake is just like a data junk yard, it should store the original raw data in spite of the data type, as it is impossible to predict whether some data are useful or not in the future. The value of data can only be reflected through calculation, which requires the computing ability of data warehouse. However, the data warehouse is closed, and the data must be deeply organized to meet criteria before being loaded into database. In addition, the large amount of raw “junk data” in the data lake cannot be calculated directly, whereas organizing data not only losses original information, but also faces diverse data sources problem mentioned above. Consequently, the real-timeness of data cannot be guaranteed, and the ETL itself costs a lot, resulting in a poor timeliness.
Compared to the fake Lakehouse implemented on traditional data warehouse, esProc can implement true Lakehouse, because esProc has enough openness, and can calculate the unorganized data of data lake directly, and has the ability to perform mixed computation on many types of data sources while guaranteeing the computing efficiency by means of high-performance mechanism.
esProc has the ability to directly calculate the raw data in data lake, and there are no constraints, and there is no need to load data into database. Moreover, esProc can perform mixed calculation on diverse data sources. Whether the data lake is built based on a unified file system or diverse data sources (RDB, NoSQL, LocalFile, Webservice), a direct mixed computing can be done by esProc to quickly output the value of data lake. Furthermore, the high-performance file storage of esProc (the storage function of data warehouse) can be utilized to organize the data in an orderly way while computing by esProc. Converting the raw data to esProc’s storage can obtain higher performance. The data are still stored in file system after they are converted to esProc storage, and theoretically, they can be stored in the same place with data lake. In this way, a true Lakehouse is implemented.
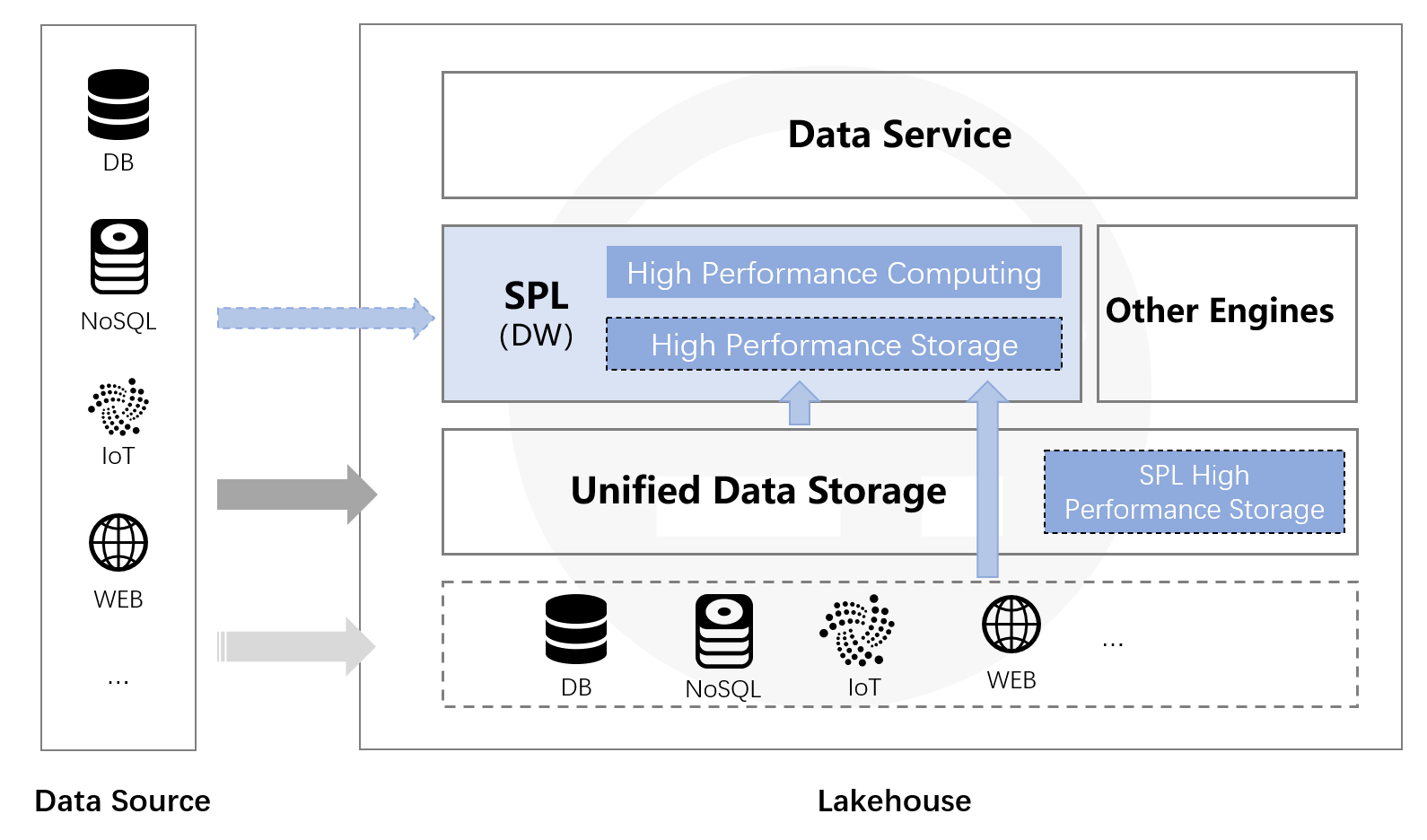
With the support of esProc’s computing ability, the organization and computation of data can be conducted at the same time, and the data lake can be built in a stepwise and ordered manner. Moreover, the data warehouse is being refined in the process of building data lake, making the data lake has strong computing ability as well, thereby implementing a true Lakehouse.
From closed to open, this is the manifestation of the continuous progress of technology. The same goes for data warehouse, more specifically, developing from “with house” to “no house” is an inevitable stage that data warehouse experiences, and hence the data warehouse is about to enter the era of “no house”. esProc may not be perfect, but it has taken a big step forward in terms of developing the capabilities of “no house” data warehouse, and it is definitely worth a try
SPL Official Website 👉 https://www.scudata.com
SPL Feedback and Help 👉 https://www.reddit.com/r/esProcSPL
SPL Learning Material 👉 https://c.scudata.com
SPL Source Code and Package 👉 https://github.com/SPLWare/esProc
Discord 👉 https://discord.gg/2bkGwqTj
Youtube 👉 https://www.youtube.com/@esProc_SPL


Chinese version